深入JVM学习心得
前言
相信很多人和我一样长期使用java编程,却 很少关注过JVM底层实现,这很大程度上是因为JVM设计的很精巧,因此平时项目也很少遇到涉及JVM的问题。但是一方面出于对java底层技术的好奇, 另一方面某些高并发,要对特定场景优化或者是排错的问题也迫切需要对JVM实现的了解,于是楼主这两天仔细拜读了《inside JVM》这本关于JVM的经典著作,对JVM的一些实现细节有了较为清楚的认识,将一些学习的体会和收获记录下来与各位有相同困扰的朋友分享。
本文将从JVM的几大核心技术切入:JVM内存管理、class文件格式、类装载、垃圾收集、多线程并发。需要注意的是因为Java是一个平台无关的技 术,JVM在不同平台上必须有不同的实现,因此当年的Sun发布了一个JVM specification(Java 虚拟机规范)。任何团体或个人实现的JVM都必须遵照该规范才能正确的运行java程序。因此本文讨论的很多技术可能在不同的虚拟机上实现会有所不同,本 文只是讨论一些通用的技术以及虚拟机规范定义的一些要求。
JVM内存管理
在Java虚拟机规范中,将JVM虚拟机的内存分成了如下图中运行时数据区几大区域
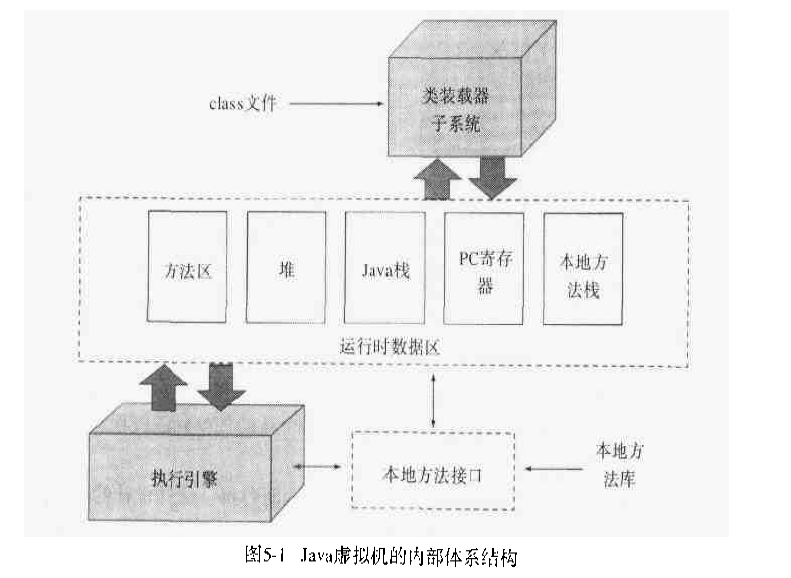
这几个区域分别是方法区,堆,Java栈,PC寄存器,本地方法栈。接下来我们就来详细认识下这些内存区域的作用。
首先要说的是堆,堆中存放的是所有在java程序运行过程中创建的对象,因为在java里,数组是以对象的形式存在,因此数组也是存放在堆中的。堆占据了JVM的大部分内存。因此也是Java的GC,垃圾收集器主要工作的目标区域。【提到数组如:int[5] a = {1,2,3,4,5};】
接下来要说的是方法区,方法区里存储了所有 类装载进来后和这个类相关的所有运行时需要的信息(如类的静态变量,常量,类的全局名称,方法信息等)。我们在后面介绍class文件的章节里会详细介绍 class文件加载进来之后是如何将这些信息对应写入方法区的数据结构中的。
【即类在装载这个动作时,会将类的静态变量(static修饰的),常量(final修饰的),类的全局名称(可能就是加上包名等的吧)等这些东西初始化赋值,以满足该类在运行(即实例化new)时所需要的东西。如上面中括号里写的如果写成:final int[5] = {1,2,3,4,5};应该就是存储在方法区里了。】
和前面介绍的两个区域是所有线程共享的不同,Java栈和本地方法栈以及PC寄存器都是线程独占的,也就是说每个线程都有一个java栈和PC寄存器或者本地方法栈(如果用到了本地方法的话)。
说到这里需要介绍一下本地方法,我们知道 java是跨平台的,但是我们比如在需要读文件的时候,不用去关心将来是在哪个平台运行,只要调用FileInputStream把文件读入就可以了,不 用调用底层操作系统的API函数,这是因为不同平台Java的API把所有这些与平台相关的操作都封装了起来提供了一个统一的Java编程接口。而 Java的API正是通过调用一些本地方法(这些方法很多时候是一些编译后的可执行的C程序)来实现了这些功能。同时虽然Java实现了大部分平台都有的 一些功能(如IO,多线程等),但是有些平台的一些功能是该平台特有的,提供Java虚拟机的厂商为了提供这些功能往往就以动态链接库的形式提供一些本地 方法的调用来完善JVM在该平台的功能。至于如何去调用以及如何与本地方法通信(获取返回值等)就是具体JVM实现需要去做的事情。
说了这么多本地方法的内容,现在回到Java 栈的部分,每个线程都有一个自己独立的Java栈,每次线程执行到一个新的方法时就在栈里面压入一个栈帧。帧里包含了方法里的局部变量,操作数栈以及帧数 据区。这三种区域中局部变量很好理解,就是在方法作用范围内的变量,包括基本变量和对象的引用。理解操作数栈要先对JVM执行java程序的过程有所了 解,JVM在装载进class文件后可能采用解释执行、即时编译执行、混合执行这三种方式来执行class文件中的JVM指令集。JVM指令集是一个4字 节的指令集,就像汇编语言做相加操作需要先将两个数存入寄存器一样,JVM指令做数据相关的操作也要先将数据压入java栈里面的操作数栈才能进行。比如 方法里将i变量和j变量相加赋值给z,JVM先将i压入操作数栈,再将j压入操作数栈,最后将结果写回局部变量表或者是对象的字段。至于帧数据区,是为了 在方法执行过程中访问方法区的数据以及返回方法结果而用的。某个方法执行结束完之后如果是正常返回则会将返回结果压入上一个方法的操作数栈中,如果是异常 退出且没有catch该异常则会运行到上一个方法继续抛出该异常。
本地方法和Java方法一样,只是Java栈是执行Java方法的线程申请的内存,而本地方法是执行本地方法而申请的内存。下面这张图显示了两者的关系。
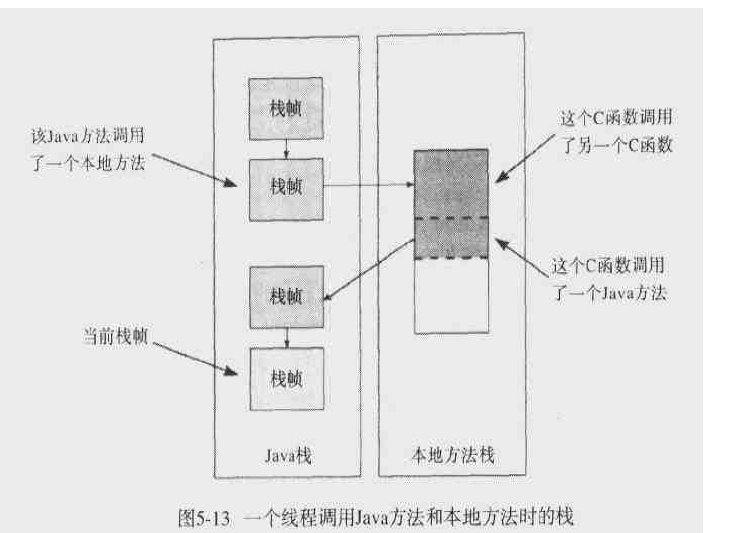
最后程序计数器是为每个线程记录当前执行的字节码位置而设立的,线程切换时需要记录下当前执行到哪一步了以便该线程重新获取CPU执行时能继续正确执行。
顺便说一句,在java里面对象是通过引用来 操作的,栈里面存储的引用,而堆里存储的对象。不同的JVM实现在引用的具体实现上可能有所不同,两种比较流行的方式分别是通过对象句柄引用和通过直接指 针引用。JVM的GC也是通过引用来确定哪些对象可以回收。下图分别表示了两种引用的实现:
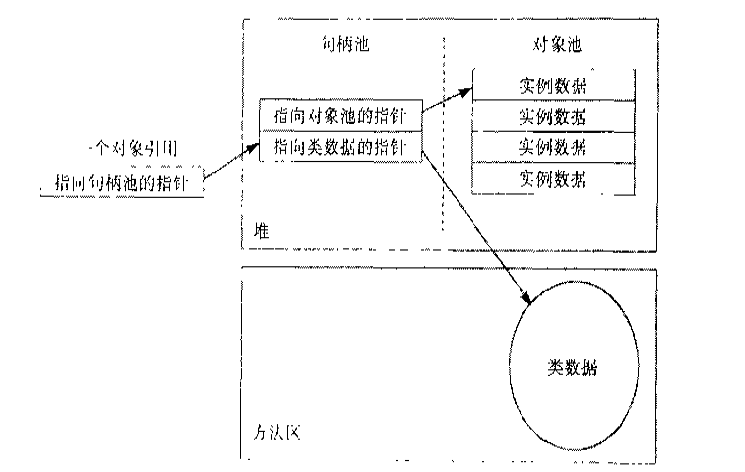
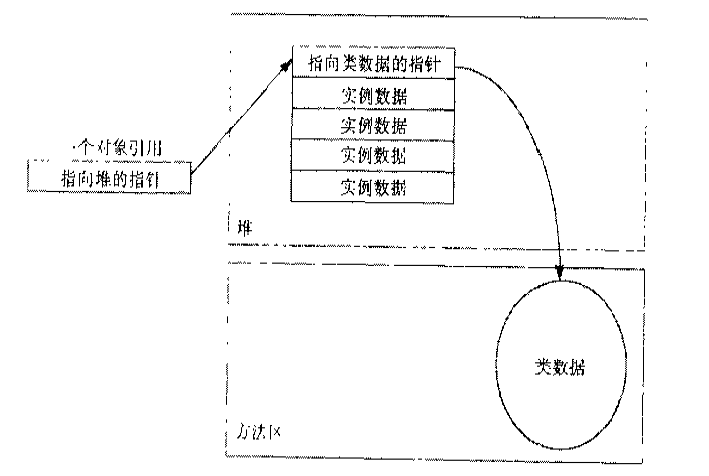
对比这两种引用实现,句柄池的方法在GC需要 移动对象(消除内存碎片以存放大对象)时,只需要将句柄池中每个对象的指针地址修改即可。但是引用访问对象需要经过两个地址查找,降低了效率。直接指向对 象的方式在需要移动对象时要将每个引用的地址都做修改,这相对直接修改句柄池来说要昂贵的多,但是因为一次寻址提高了效率。
细心的读者可能注意到不管采用什么方式,每个 引用都有一个指向方法区里该类数据的指针。这是因为在java里面不像C++可以直接对内存对象做类型转换,Java类型转换前一定要做类型检查以保证这 次转换是安全的以避免可能因此带来的程序崩溃。因此每个引用都有一个指向类型数据的指针。
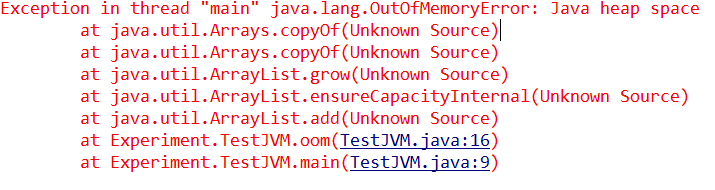
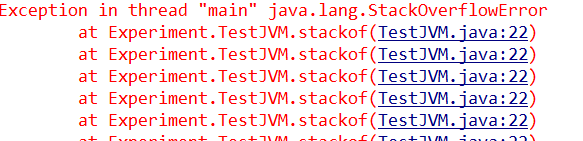
本文花了很大篇幅介绍java栈的内容,是因 为作者认为在这几个区域中,Java栈是最难理解的部分,希望读者能耐心读完,有什么问题也欢迎留言交流,最后为了加深对堆和栈存储哪些数据的理解,作者 写了两个分别产生OutOfMemoryError和StackOverflowError的函数以帮助理解,oom函数在数组对象s中不停的添加数据, 最后堆内存无法满足新的添加需求JVM就退出同时报出了OutOfMemoryError, stack()方法中有一个s的双精度局部变量,同时不停的递归调用自己,Java栈中就不停的压入新的方法栈,最后JVM退出并报出了 StackOverflowError
Java代码:

package Experiment;
import java.util.ArrayList;
public class TestJVM {
public static void main(String[] args)
{
stackof();
//oom();
}
private static void oom()
{
ArrayList<Integer> s=new ArrayList<>();
while(true)
{
s.add(1);
}
}
private static void stackof()
{
double s;
stackof();
}
}
运行结果:
原文地址:http://www.cnblogs.com/developerY/p/3330811.html 转载请注明出处