epoll
worker数(核数或核数的2倍)
worker进程绑定到核
单worker最大连接数
单worker最大打开文件数
优化传文件
优化zip压缩
优化超时参数
expire缓存
优化fastcgi
日志优化(切割/选择记录/权限/汇总备份)
nginx性能优化
epoll
user www www;
worker_processes 1;
events {
worker_connections 1024;
use epoll; # 指定使用的模型为epoll
- NGINX 使用的是epoll 和Kqueue 异步网络I/O模型,而apache使用的是传统的select模型
select & epoll的最主要的区别
| epoll和select的区别 | 说明 |
|---|---|
| 第一个比喻: | 假设你在大学读书,住的宿舍楼有很多房间,你的朋友要来找你。select版宿管大妈就会带着你的朋友到各房间挨个去找,直到找到你为止。而epoll版宿管大妈会先记下每位入住同学的房间号,你的朋友来找你时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满宿舍楼找人了。如果同时来了100个人,都要找自己住这栋楼的同学,select版和epoll版宿管大妈,谁的效率更高,就很明显了。 |
| 第二个比喻: | select的调用复杂度是线性的,即O(n)。举个例子,一个保姆照看照看一群孩子,如果把孩子是否需要尿尿比作网络I/O事件,select的作用就好比这个保姆挨个询问每个孩子"你要尿尿吗?”如果孩子回答是,保姆则把孩子领出来放到另外一个地方。当所有孩子询问完之后,保姆领着这些要尿尿的孩子去上厕所(处理网络I/O事件).在epoll机制下,保姆不再需要挨个询问每个孩子是否需要尿尿。取而代之的是,如果孩子需要尿尿,他就自己主动站到事先约定好的地方,而保姆的职责就是查看事先约定好的地方是否有孩子。如果有小孩,则领着孩子去上厕所(网络事件处理)。因此,epoll的这种机制,能够高效地处理成千上万的并发连接,并且性能不会随着连接数増加而下降太多。 |
- apache select和nginx epoll技术对比图
| 指标 | select | epoll |
|---|---|---|
| 性能 | 随着连接数的增加性能急剧下降。处理成千上万的并发连接数,性能很差 | 随着连接数的增加,性能基本上没有下降。处理成千上万连接时性能很好 |
| 连接数 | 连接数有限制,处理的最大连接数不超过1024,如果要处理的连接数超过1024个,则需要修改FD_SETSIZE宏,并重新编译 | 连接数无限制 |
| 内在处理机制 | 线性轮询 | 回调callback |
| 开发复杂性 | 低 | 中 |
worker数(核数或核数的2倍)
01) master进程:(主管)可以控制nginx服务的启动 停止 或重启
02) worker进程:(干活的)处理用户请求信息,帮助用户向后端服务进行请求(php mysql)
$ vim nginx.conf
worker_processes 1; # 修改nginx配置文件中worker_processes指令后面的数值
建议:worker进程数量=等于CPU的核数 worker进程数量=等于CPU的核数*2
如何在一个系统中获悉CPU核心是多少?
1. 利用top命令--按数字1,获取到CPU核数信息
2. grep processor /proc/cpuinfo|wc -l
3. lscpu
4. top -> 按1
执行top,
按 1
worker进程绑定到核
- 4个worker进程分配CPU资源方法:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
- 8个worker进程分配CPU资源方法;
worker_processes 8;
worker_cpu_affinity 0001 0010 0100 1000 0001 0010 0100 1000; # 分配8进程方法
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
- 4个worker进程分配CPU资源方法:
worker_processes 4;
worker_cpu_affinity 0101 1010; # 将进程分配到两颗CPU上
单worker最大连接数
$ vim nginx.conf
events #<==events指令是设定Nginx的工作模式及连接数上限
{
worker_connections 1024;
}
注: 此数值设置不要超过系统最大打开文件数量。
单worker最大打开文件数
[root@web02 conf]# cat nginx.conf
user www www;
worker_processes 1;
worker_rlimit_nofile 2048; # 设置worker进程打开文件数
优化传文件
sendfile参数的官方说明如下:
syntax:sendfile on | off; #<==参数语法
default:sendfile off; #<==参数默认大小
context:http,server,location,if in location #<==可以放置的标签段
说明:在系统内核中,利用零拷贝方式实现数据传输
- 实现高效数据传输的两种方式
第一种方式:tcp_nopush
syntax: tcp_nopush on | off; #<==参数语法
default: tcp_nopush off; #<==参数默认大小
context: http,server,location #<==可以放置的标签段
说明:将数据包积攒到一定量时再进行传输
参数作用:
激活或禁用Linux上的TCP_NODELAY选项。这个参数启用只在连接传输进入到 keep-alive状态。TCP_NODELAY和TCP_CORK基本上控制了包的"Nagle化",Nagle化在这里 的含义是采用Nagle算法把较小的包组装为更大的帧。John Nagle是Nagle算法的发明人,后者就是用他的名字来命名的。
此算法解决的问题就是所谓的silly window syndrome,中文称"愚蠢窗口症候群",具体含义是,因为普遍终端应用程序每产生一次击键操作就会发送一个包,很轻易地就能令网络发生拥塞,Nagle化后来成了一种标准并且立即在因特网上得以实现。它现在已经成为缺省配置了,但在我们看来,有些场合下希望发送小块数据,把这一选项关掉也是合乎需要的。
第二种方式:tcp_nodelay(默认)
Syntax: tcp_nodelay on | off;
Default: tcp_nodelay on;
Context: http, server, location
说明:只要有数据包产生,不管大小多少,就尽快传输
参数作用:
激活或禁用Linux上的TCP_CORK socket选项,tcp_cork是linux下tcp/ip传输的一个标准了,这个标准的大概的意思是,一般情况下,在tcp交互的过程中,当应用程序接收到数据包后马上传送出去,不等待,而tcp_cork选项是数据包不会马上传送出去,等到数据包最大时,一次性的传输出去,这样有助于解决网络堵塞,已经是默认了。
此选项仅仅当开启sendfile时才生效, 激活这个.tcp_nopush参数可以允许把http response header和响应数据文件的开始部分放在一个文件里发布,其积极的作用是减少网络报文段的数量。
强调:两个指令是相悖的,请选择其一开启,不要同时开启;
默认采用tcp_nodelay方式进行传输。
优化zip压缩
- 需要和不需要压缩的对象?
- 纯文本内容压缩比很高,因此,纯文本的内容最好进行压缩,例如:html、js、css、xml、shtml等格式的文件。
- 被压缩的纯文本文件必须要大于1KB,由于压缩算法的特殊原因,极小的文件压缩后可能反而变大。
- 图片、视频(流媒体)等文件尽量不要压缩,因为这些文件大多都是经过压缩的。
- 如果再压缩很可能不会减小或减小很少,或者有可能增大,同时压缩时还会消耗大量的CPU、内存资源。
- 压缩参数
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.1;
gzip_comp_level 4;
gzip_types text/css text/xml application/javascript;|
gzip_vary on;
注意:将服务端响应的数据信息进行压缩,可以有效节省带宽,提高用户访问效率
- 压缩配置参数说明
| 参数 | 说明 |
|---|---|
| gzip on ; | #<==开启gzip压缩功能。 |
| gzip_min_length lk; | #<==设置允许压缩的页面最小宇节数,页面宇节数从header头的Content-Length中获取。默认值是0,表示不管页面多大都进行压缩。建议设置成大于1K,如果小于1K可能会越压越大。 |
| gzip_buffers 4 16k; | #<==压缩缓冲区大小。表示申请4个单位为16K的内存作为压缩结果流缓存,默认值是申请与原始数据 大小相同的内存空间来存储gzip压缩结果。 |
| gzip_http_version 1.1 ; | #<==压缩版本(默认1.1,前端为squid2.5时使用1.0),用于设置识别HTTP协议版本,默认是1.1, 目前大部分浏览器已经支持GZIP解压,使用默认即可。 |
| gzip_comp_level 2 ; | #<==压缩比率。用来指定gzip压缩比,1压缩比最小,处理速度最快;9压缩比最大,传输速度快,但处理最慢,也比较消耗CPU资源。 |
| gzip_types text/plain application/x-javascript text/css application/xml ; | #<==用来指定压缩的类型,"text/html"类型总是会被压缩,这个就是HTTP原理部分讲的媒体类型。 |
| gzip_vary on ; | #<==vary header支持。该选项可以让前端的缓存服务器缓存经过gzip压缩的页面,例如用Squid缓存 经过Nginx压缩的数据。 |
优化超时参数
Nginx连接超时的参数设置
-
- 设置参数: keepalive_timeout 60; # 长连接才有意义
keepalive_timeout参数的官方说明如下:
syntax:keepalive_timeout timeout [header_timeout];#<==参数语法
default:keepalive_timeout 75s; #<==参数默认大小
context:http,server,location #<==可以放置的标签段
说明:客户端和服务端都没有数据传输时,进行超时时间倒计时,一旦超时时间读取完毕还没有数据传输,就断开连接
-
- 设置参数:client_header_timeout 55;
syntax:client_header_timeout time; #<==参数语法
default:client_header_timeout 60s; #<==参数默认大小
context:http,server #<==可以放置的标签段
说明:表示定义客户端请求报文发送的间隔超时时间,客户端发送的请求报文中请求头信息的间隔时间
- 3)设置参数:client_body_timeout 55;
syntax:client_body_timeout time; #<==参数语法
default:client_body_timeout 60s; #<==默认值是60秒
context:http,server,location #<==可以放置的标签段
说明:表示定义服务端响应报文发送的间隔超时时间,客户端发送的请求报文中请求主体信息的间隔时间
- 4)设置参数:send_timeout 60s
syntax:send_timeout time; #<==参数语法
default:send_timeout 60s; #<==默认值是60秒
context:http,server,location #<==可以放置的标签段
说明:表示定义客户端读取服务端响应报文的间隔超时时间,服务端发送的响应报文间隔时间
expire缓存
简单地说,Nginx expires的功能就是为用户访问的网站内容设定一个过期时间,当用户第一次访问这些内容时,会把这些内容存储在用户浏览器本地,这样用户第二次及以后继续访问该网站时,浏览器会检查加载已经缓存在用户浏览器本地的内容,就不会去服务器下载了,直到缓存的内容过期或被清除为止。
- Nginx expires功能优点
- expires可以降低网站的带宽,节约成本。
- 加快用户访问网站的速度,提升用户访问体验。
- 服务器访问量降低了,服务器压力就减轻了,服务器成本也会降低,甚至可以节约人力成本。
- 对于几乎所有的Web服务来说,这是非常重要的功能之一,Apache服务也有此功能。
- 实战配置
server {
listen 80;
server_name www.maotai.com;
server_tokens off;
# 静态请求处理的location
location / {
root html/blog;
index index.php index.html index.htm;
}
# 动态请求处理的location
location ~* .*.(php|php5)?$ {
root html/blog;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
location ~ .*.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 10y;
root html/blog;
}
location ~ .*.(js|css)$
{
expires 30d;
root html/blog;
}
location / {
expires 3650d;
}
}
- 企业网站有可能不希望被缓存的内容?
- 广告图片,用于广告服务,都缓存了就不好控制展示了。
- 网站流量统计工具(JS代码),都缓存了流量统计就不准了。
- 更新很频繁的文件(google的logo),这个如果按天,缓存效果还是显著的。
优化fastcgi
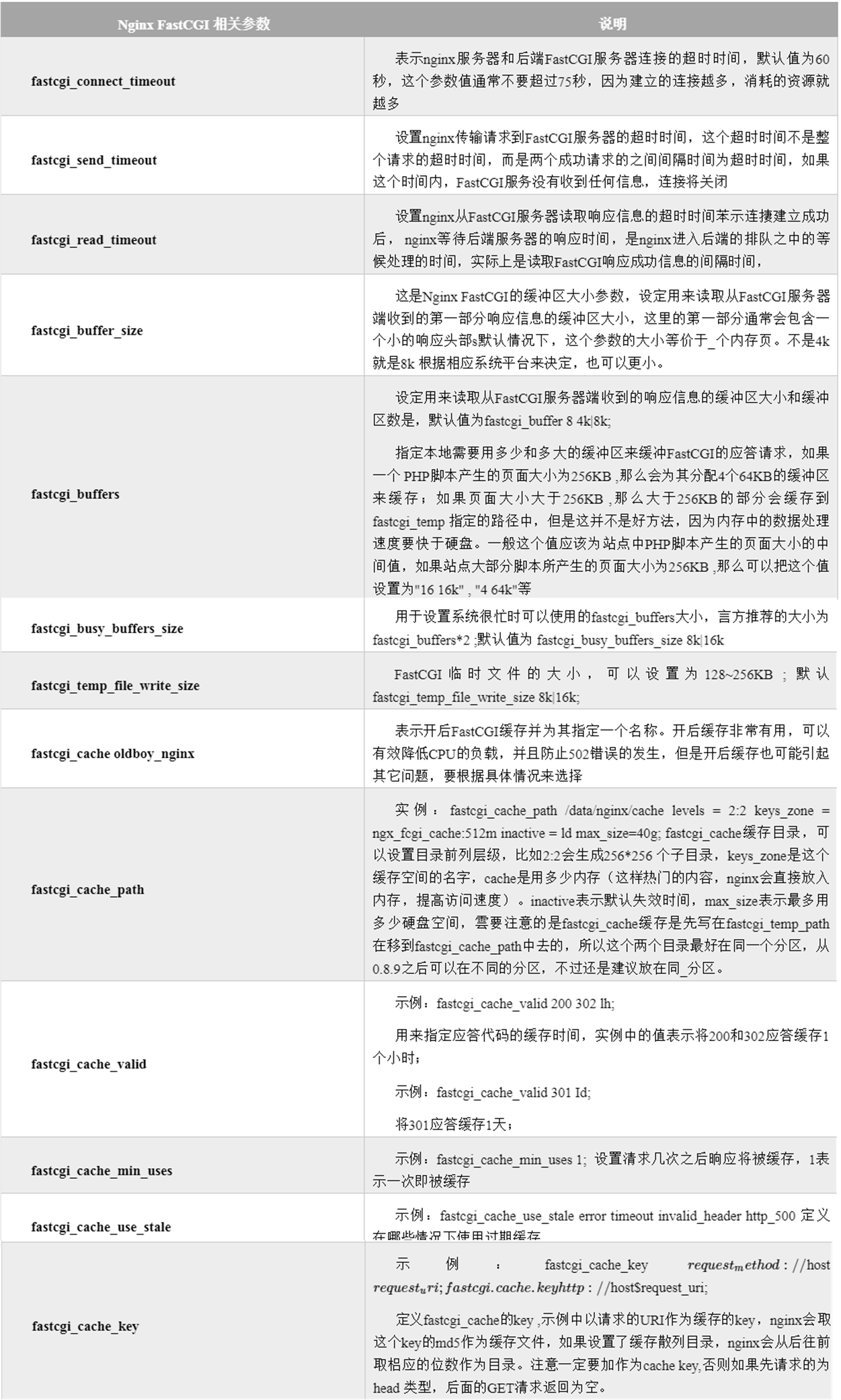
- FastCGI常见参数的Nginx配置示例如下:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
worker_rlimit_nofile 65535;
user www www;
events {
use epoll;
worker_connections 10240;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
tcp_nodelay on;
client_header_timeout 15;
client_body_timeout 15;
send_timeout 15;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
server_tokens off;
fastcgi_connect_timeout 240;
fastcgi_send_timeout 240;
fastcgi_read_timeout 240;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#fastcgi_temp_path /data/ngx_fcgi_tmp;
fastcgi_cache_path /data/ngx_fcgi_cache levels=2:2 keys_zone=ngx_fcgi_cache:512m inactive=1d max_size=40g;
#web...............
server {
listen 80;
server_name blog.nmtui.com;
root html/blog;
location / {
root html/blog;
index index.php index.html index.htm;
}
location ~ .*.(php|php5)${
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
fastcgi_cache ngx_fcgi_cache;
fastcgi_cache_valid 200 302 1h;
fastcgi_cache_valid 301 1d;
fastcgi_cache_valid any 1m;
fastcgi_cache_min_uses 1;
fastcgi_cache_use_stale error timeout invalid_header http_500;
fastcgi_cache_key http://$host$request_uri;
}
access_log logs/web_blog_access.log main;
}
upstream blog_etiantian{
server 10.0.0.8:8000 weight=1;
}
server {
listen 8000;
server_name blog.nmtui.com;
location / {
proxy_pass http://blog_etiantian;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
}
access_log logs/proxy_blog_access.log main;
}
}
常见参数
日志优化(切割/选择记录/权限/汇总备份)
- 01.进行日志的切割
[root@maotai ~]# mkdir /server/scripts/ -p
[root@maotai ~]# cd /server/scripts/
[root@maotai scripts]# vim cut_nginx_log.sh
#!/bin/bash
cd /usr/local/nginx/logs &&
/bin/mv www_access.log www_access_$(date +%F -d -1day).log #<==将日志按日期改成前一天的名称
/usr/local/nginx/sbin/nginx -s reload #<==重新加载nginx使得触发重新生成访问日志文件
提示:实际上脚本的功能很简单,就是改名日志,然后加载nginx,重新生成文件记录日志
说明:也可以编辑使用logrotate日志切割服务,进行日志切割
- 02.进行日志的选择记录
location ~ .*.(js|jpg|JPG|jpeg|JPEG|css|bmp|gif|GIF)$ {
access_log off;
}
- 03.进行日志文件授权
假如日志目录为/app/logs,则授权方法如下:
chown -R root.root /app/logs
chmod -R 700 /app/logs
- 04.日志信息尽量汇总备份
[root@maotai ~]# zgrep 456 maotai.tar.gz