代码在硬盘上是一堆二进制
- 弄清楚文件在硬盘/内存中的存储值
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
vim查看 :%!xxd

在终端里执行 man ascii
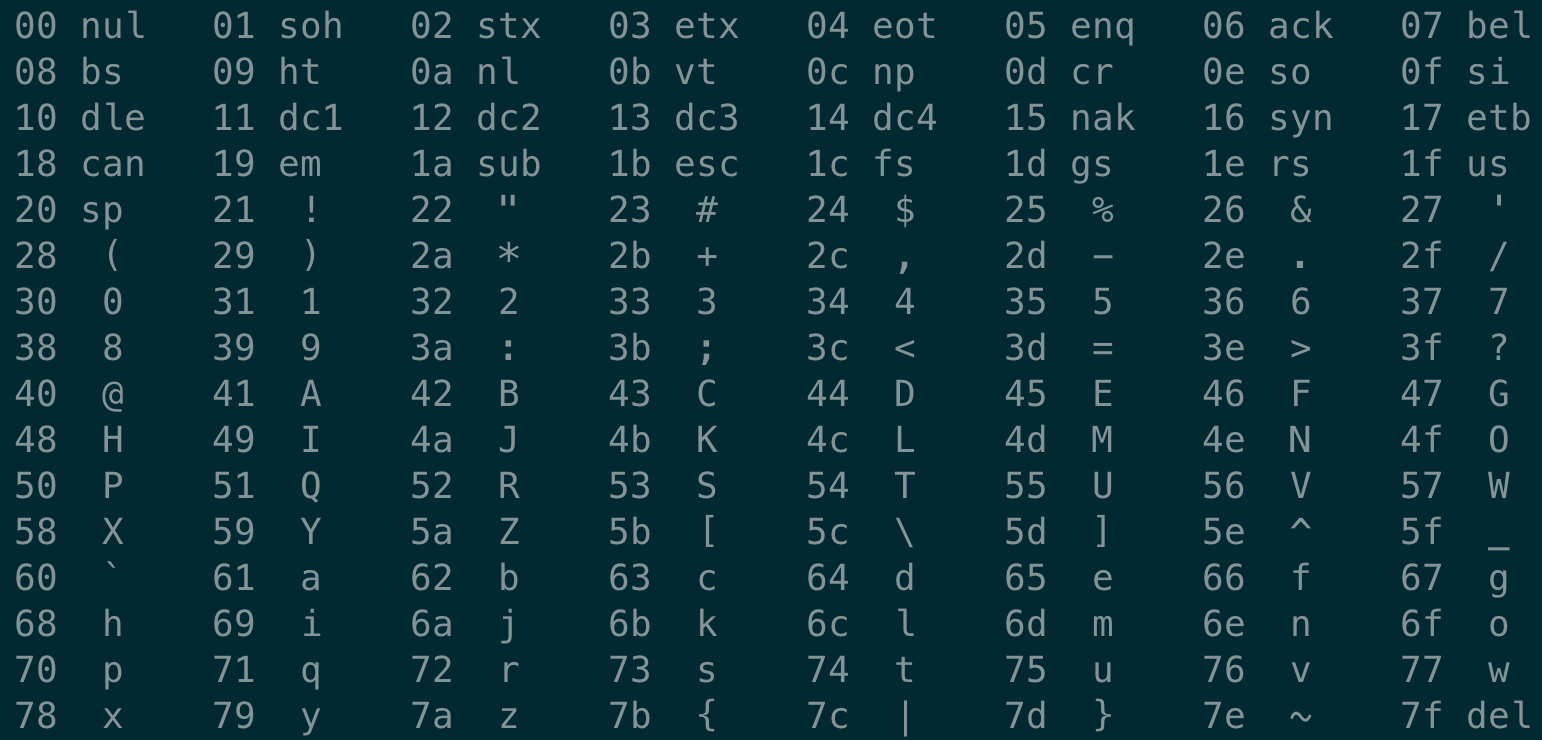
观察发现, 中间列和最右列 是一一对应的。
也就是说,刚刚写完的 hello.go 文件都是由 ASCII 字符表示的(文本文件)
- 汇编转换位机器指令

- go语句转换为机器指令过程
Go 程序并不能直接运行,每条 Go 语句必须转化为一系列的低级机器语言指令,将这些指令打包到一起,
并以二进制磁盘文件的形式存储起来,也就是可执行目标文件。
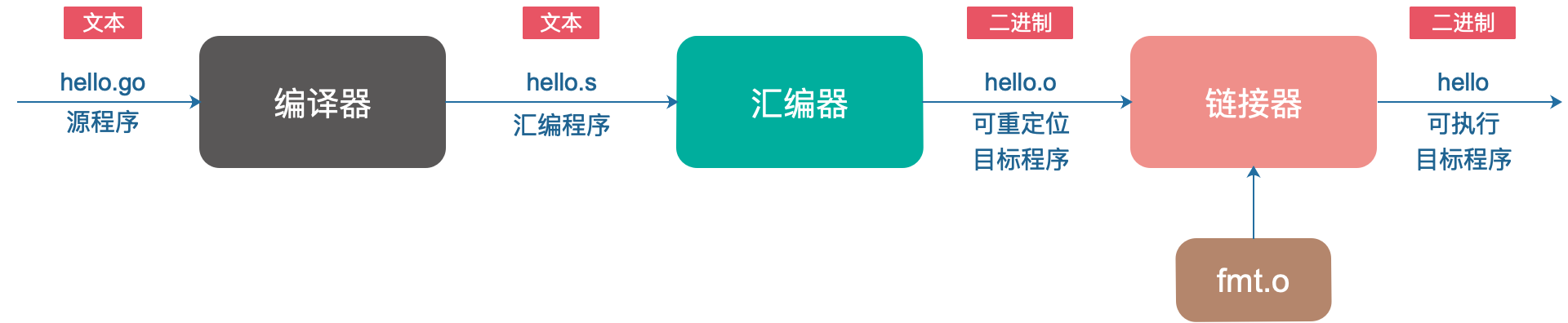
探索编译和运行的过程
通常将编译和链接合并到一起的过程称为构建(Build)。
编译过程就是对源文件进行词法分析、语法分析、语义分析、优化,最后生成汇编代码文件,以 .s 作为文件后缀的汇编指令。
汇编器会将汇编代码转变成机器可以执行的指令。
由于每一条汇编语句几乎都与一条机器指令相对应,所以只是一个简单的一一对应,比较简单,没有语法、语义分析,也没有优化这些步骤。
- 编译器的作用: 将高级语言翻译成机器语言
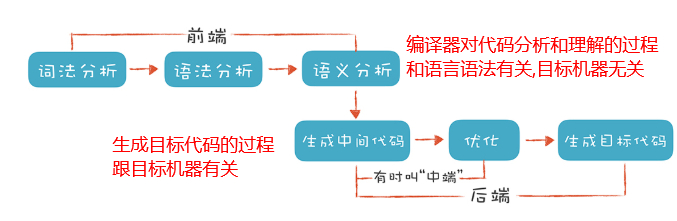
- 词法分析
使用一种有限状态机的算法
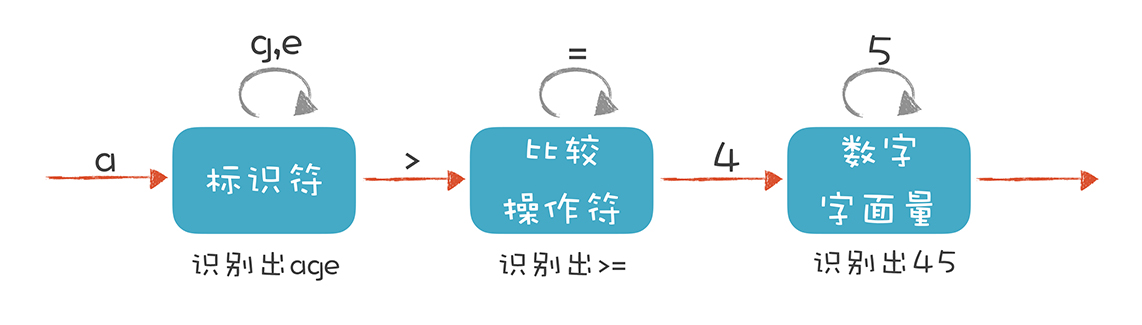
有限自动机是有限个状态的自动机器。
我们可以拿抽水马桶举例,它分为两个状态:“注水”和“水满”。
摁下冲马桶的按钮,它转到“注水”的状态,而浮球上升到一定高度,就会把注水阀门关闭,它转到“水满”状态。
我们会识别出if、else、int这样的关键字,main、printf、age这样的标识符,+、-、=这样的操作符号,还有花括号、圆括号、分号这样的符号,以及数字字面量、字符串字面量等。这些都是Token。
token一般分为这几类:关键字、标识符、字面量(包含数字、字符串)、特殊符号(如加号、等号)。
slice[i] = i * (2 + 6)
总共包含 16 个非空字符,经过扫描(对那棵树 递归下降算法(Recursive Descent Parsing)构建一棵完整的树)后,
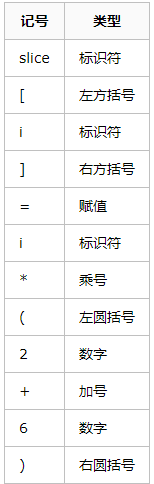
- src/cmd/compile/internal/syntax/scanner.go
最关键的函数就是 next 函数,它不断地读取下一个字符(go utf8以字符为单位)
func (s *scanner) next() {
- src/cmd/compile/internal/syntax/token.go
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
-
语法分析
例如“2+3*5”,你会得到一棵类似下图的AST。
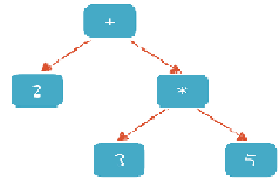
-
语义分析
以“You can never drink too much water.” 这句话为例。它的确切含义是什么?
是“你不能喝太多水”,
还是“你喝多少水都不嫌多”?
实际上,这两种解释都是可以的,我们只有联系上下文才能知道它的准确含义。
词法分析是把程序分割成一个个Token的过程,可以通过构造有限自动机来实现。
语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。可以用递归下降的算法来实现。
语义分析是消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码。
-
目标代码生成与优化
不同机器的机器字长、寄存器等等都不一样,意味着在不同机器上跑的机器码是不一样的。最后一步的目的就是要生成能在不同 CPU 架构上运行的代码。
为了榨干机器的每一滴油水,目标代码优化器会对一些指令进行优化,例如使用移位指令代替乘法指令等。 -
链接
链接过程就是要把编译器生成的一个个目标文件链接成可执行文件。最终得到的文件是分成各种段的,比如数据段、代码段、BSS段等等,运行时会被装载到内存中。各个段具有不同的读写、执行属性,保护了程序的安全运行。

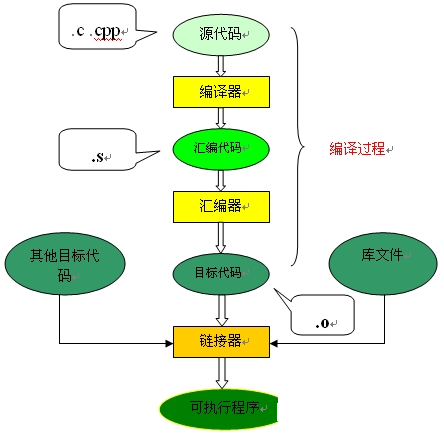
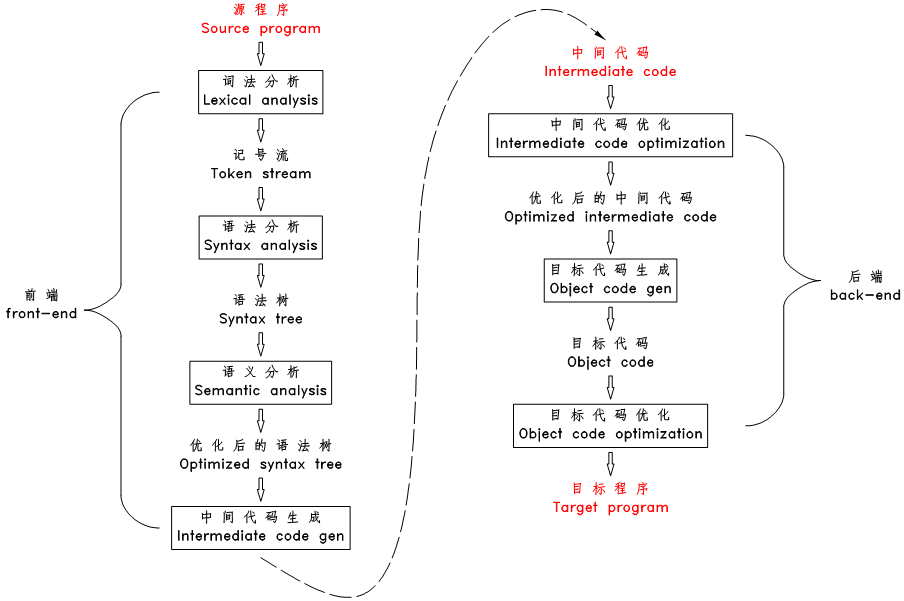
从上图: 将编写的一个c程序(源代码 )转换成可以在硬件上运行的程序(可执行代码 ),需要进行
编译阶段
先通过“编译器 “把一个 .c/.cpp 源代码 编译成 .s的汇编代码;
再经过“汇编器 ” 把这 个.s的汇编代码汇编成 .o 的 目标代码
链接阶段
通过连接其他 .o 代码(如果需要的话) 库文件 和 1 中的.o 目标代码生成可执行文件
该文件流被这三种程序(红色)的加工,分别表现出四种形式(蓝色),这就是c程序的编译和链接过程。
如果再详细的话,编译器在将源文件编译成汇编文件的过程又分为:预处理阶段(生成 .i 代码) 和 优化阶段