1、分区
对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm。
根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表呢,还是一张表。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。
- 优点:数据不存在多个副本,不必进行数据复制,性能更高。
- 缺点:分区策略必须经过充分考虑,避免多个分区之间的数据存在关联关系,每个分区都是单点,如果某个分区宕机,就会影响到系统的使用。
2、分片
对业务透明,在物理实现上分成多个服务器,不同的分片在不同服务器上。如HDFS。
3、分表
同库分表:所有的分表都在一个数据库中,由于数据库中表名不能重复,因此需要把数据表名起成不同的名字。
- 优点:由于都在一个数据库中,公共表,不必进行复制,处理更简单。
- 缺点:由于还在一个数据库中,CPU、内存、文件IO、网络IO等瓶颈还是无法解决,只能降低单表中的数据记录数。表名不一致,会导后续的处理复杂(参照mysql meage存储引擎来处理)
不同库分表:由于分表在不同的数据库中,这个时候就可以使用同样的表名。
- 优点:CPU、内存、文件IO、网络IO等瓶颈可以得到有效解决,表名相同,处理起来相对简单。
- 缺点:公共表由于在所有的分表都要使用,因此要进行复制、同步。一些聚合的操作,join,group by,order等难以顺利进行。
4、分库
分表和分区都是基于同一个数据库里的数据分离技巧,对数据库性能有一定提升,但是随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等。此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
分库只是一个通俗说法,更标准名称是数据分片,采用类似分布式数据库理论指导的方法实现,对应用程序达到数据服务的全透明和数据存储的全透明
5、MyCat入门
用于数据库分表分库,读写分离的中间件。从http://www.mycat.io/下载即可。
MyCat作为数据库中间件与代码是弱关联的,连接方式和普通数据库一样,如:jdbc:mysql://192.168.0.2:8066/
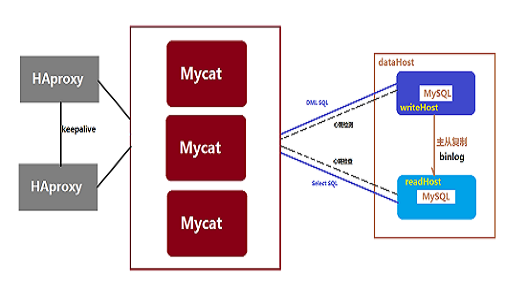
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
| 文件 | 说明 |
|---|---|
| server.xml | Mycat的配置文件,设置账号、参数等 |
| schema.xml | Mycat对应的物理数据库和数据库表的配置 |
| rule.xml | Mycat分片(分库分表)规则 |
server.xml:Mycat的配置文件,设置账号、参数等。
<user name="test">
<property name="password">test</property>
<property name="schemas">lunch</property>
<property name="readOnly">false</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
| user | 用户配置节点 |
| --name | 登录的用户名,也就是连接Mycat的用户名 |
| --password | 登录的密码,也就是连接Mycat的密码 |
| --schemas | 数据库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如需要这个用户需要管理两个数据库db1,db2,则配置db1,dbs |
| --privileges | 配置用户针对表的增删改查的权限,具体见文档 |
schema.xml:Mycat对应的物理数据库和数据库表的配置。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<!-- 分库写表 -->
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
</writeHost>
</dataHost>
<dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
| 参数 | 说明 |
|---|---|
| schema | 数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应 |
| dataNode | 分片信息,也就是分库相关配置 |
| dataHost | 物理数据库,真正存储数据的数据库 |
| 属性 | 说明 |
|---|---|
| name | 逻辑数据库名,与server.xml中的schema对应 |
| checkSQLschema | 数据库前缀相关设置,建议看文档,这里暂时设为folse |
| sqlMaxLimit | select 时默认的limit,避免查询全表 |
| 属性 | 说明 |
|---|---|
| name | 表名,物理数据库中表名 |
| dataNode | 表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name |
| primaryKey | 主键字段名,自动生成主键时需要设置 |
| autoIncrement | 是否自增 |
| rule | 分片规则名,具体规则下文rule详细介绍 |
| 属性 | 说明 |
|---|---|
| name | 节点名,与table中dataNode对应 |
| datahost | 物理数据库名,与datahost中name对应 |
| database | 物理数据库中数据库名 |
| 属性 | 说明 |
|---|---|
| name | 物理数据库名,与dataNode中dataHost对应 |
| balance | 均衡负载的方式 |
| writeType | 写入方式 |
| dbType | 数据库类型 |
| heartbeat | 心跳检测语句,注意语句结尾的分号要加。 |
rule.xml:Mycat分片(分库分表)规则。
分表分库案例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
</writeHost>
</dataHost>
<dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
PS: lunchmenu、restaurant、userlunch、users这些表都只写入节点dn1,也就是192.168.0.2这个服务,而dictionary写入了dn1、dn2两个节点,也就是192.168.0.2、192.168.0.3这两台服务器。
读写分离案例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.0.2:3306" user="root" password="123456">
<readHost host="hostS1" url="192.168.0.3:3306" user="root" password="123456"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
ps:MyCat没有实现主从复制,需要使用数据库本身自带的这个功能来实现。
6、MyCat使用
##启动
mycat start
##停止
mycat stop
##重启
mycat restart
开发注意事项
1、非分片字段查询,整库查询导致性能极差
Mycat中的路由结果是通过分片字段和分片方法来确定的。例如下图中的一个Mycat分库方案:
- 根据 tt_waybill 表的 id 字段来进行分片
- 分片方法为 id 值取 3 的模,根据模值确定在DB1,DB2,DB3中的某个分片

如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片。例如:
MySQL>select * from tt_waybill where id = 12330;
此时Mycat会计算路由结果
12330 % 3 = 0 –> DB1
并将该请求路由到DB1上去执行。
如果查询条件中没有 分片字段 条件,例如:
mysql>select * from tt_waybill where waybill_no =88661;
此时Mycat无法计算路由,便发送到所有节点上执行:
DB1 –> select * from tt_waybill where waybill_no =88661;
DB2 –> select * from tt_waybill where waybill_no =88661;
DB3 –> select * from tt_waybill where waybill_no =88661;
如果该分片字段选择度高,也是业务常用的查询维度,一般只有一个或极少数个DB节点命中(返回结果集)。示例中只有3个DB节点,而实际应用中的DB节点数远超过这个,假如有50个,那么前端的一个查询,落到MySQL数据库上则变成50个查询,会极大消耗Mycat和MySQL数据库资源。
如果设计使用Mycat时有非分片字段查询,请考虑放弃!
2、分页,没有排序的情况下统一sql执行结果随机选择不同库的查询结果
先看一下Mycat是如何处理分页操作的,假如有如下Mycat分库方案:
一张表有30份数据分布在3个分片DB上,具体数据分布如下
DB1:[0,1,2,3,4,10,11,12,13,14]
DB2:[5,6,7,8,9,16,17,18,19]
DB3:[20,21,22,23,24,25,26,27,28,29]
(这个示例的场景中没有查询条件,所以都是全分片查询,也就没有假定该表的分片字段和分片方法)

当应用执行如下分页查询时
mysql>select * from table limit 2;
Mycat将该SQL请求分发到各个DB节点去执行,并接收各个DB节点的返回结果
DB1: [0,1]
DB2: [5,6]
DB3: [20,21]
但Mycat向应用返回的结果集取决于哪个DB节点最先返回结果给Mycat。如果Mycat最先收到DB1节点的结果集,那么Mycat返回给应用端的结果集为 [0,1],如果Mycat最先收到DB2节点的结果集,那么返回给应用端的结果集为 [5,6]。也就是说,相同情况下,同一个SQL,在Mycat上执行时会有不同的返回结果。
在Mycat中执行分页操作时必须显示加上排序条件才能保证结果的正确性,下面看一下Mycat对排序分页的处理逻辑。
假如在前面的分页查询中加上了排序条件(假如表数据的列名为id)
mysql>select * from table order by id limit 2;
Mycat的处理逻辑如下图:

在有排序呢条件的情况下,Mycat接收到各个DB节点的返回结果后,对其进行最小堆运算,计算出所有结果集中最小的两条记录 [0,1] 返回给应用。
但是,当排序分页中有 偏移量 (offset)时,处理逻辑又有不同。假如应用的查询SQL如下:
mysql>select * from table order by id limit 5,2;
如果按照上述排序分页逻辑来处理,那么处理结果如下图:

Mycat将各个DB节点返回的数据 [10,11], [16,17], [20,21] 经过最小堆计算后返回给应用的结果集是 [10,11]。可是,对于应用而言,该表的所有数据明明是 0-29 这30个数据的集合,limit 5,2 操作返回的结果集应该是 [5,6],如果返回 [10,11] 则是错误的处理逻辑。
所以Mycat在处理 有偏移量的排序分页 时是另外一套逻辑——改写SQL 。如下图:

Mycat在下发有 limit m,n 的SQL语句时会对其进行改写,改写成 limit 0, m+n 来保证查询结果的逻辑正确性。所以,Mycat发送到后端DB上的SQL语句是
mysql>select * from table order by id limit 0,7;
各个DB返回给Mycat的结果集是
DB1: [0,1,2,3,4,10,11]
DB2: [5,6,7,8,9,16,17]
DB3: [20,21,22,23,24,25,26]
经过最小堆计算后得到最小序列 [0,1,2,3,4,5,6] ,然后返回偏移量为5的两个结果为 [5,6] 。
虽然Mycat返回了正确的结果,但是仔细推敲发现这类操作的处理逻辑是及其消耗(浪费)资源的。应用需要的结果集为2条,Mycat中需要处理的结果数为21条。也就是说,对于有 t 个DB节点的全分片 limit m, n 操作,Mycat需要处理的数据量为 (m+n)*t 个。比如实际应用中有50个DB节点,要执行limit 1000,10操作,则Mycat处理的数据量为 50500 条,返回结果集为10,当偏移量更大时,内存和CPU资源的消耗则是数十倍增加。
如果设计使用Mycat时有分页排序,请考虑放弃!
3、任意表JOIN,关联字段不在同一个库导致查询失败
先看一下在单库中JOIN中的场景。假设在某单库中有 player 和 team 两张表,player 表中的 team_id 字段与 team 表中的 id 字段相关联。操作场景如下图:

JOIN操作的SQL如下
mysql>select p_name,t_name from player p, team t where p.no = 3 and p.team_id = t.id;
此时能查询出结果
| p_name | t_name |
|---|---|
| Wade | Heat |
如果将这两个表的数据分库后,相关联的数据可能分布在不同的DB节点上,如下图:

这个SQL在各个单独的分片DB中都查不出结果,也就是说Mycat不能查询出正确的结果集。
设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请考虑放弃!
4、分布式事务
Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的 弱XA事务 ,实现过程如下:
应用开启事务后Mycat标识该连接为非自动提交,比如前端执行
mysql>begin;
Mycat不会立即把命令发送到DB节点上,等后续下发SQL时,Mycat从连接池获取非自动提交的连接去执行。

Mycat会等待各个节点的返回结果,如果都执行成功,Mycat给该连接标识为 Prepare Ready 状态,如果有一个节点执行失败,则标识为 Rollback 状态。

执行完成后Mycat等待前端发送 commit 或 rollback 命令。发送 commit 命令时,Mycat检测当前连接是否为 Prepare Ready 状态,若是,则将 commit 命令发送到各个DB节点。

但是,这一阶段是无法保证一致性的,如果一个DB节点在 commit 时故障,而其他DB节点 commit 成功,Mycat会一直等待故障DB节点返回结果。Mycat只有收到所有DB节点的成功执行结果才会向前端返回 执行成功 的包,此时Mycat只能一直 waiting 直至TIMEOUT,导致事务一致性被破坏。
设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请考虑放弃!