Drebin样本的百度网盘下载链接我放在下面评论区了,大家自行下载。本次实验收到上一次实验启发(微软恶意软件分类),并采用了这篇博文的实现代码(用机器学习检测Android恶意代码),代码都可以在博主提供的github地址中找到。
原理
具体原理参考上一次实验,都是提取反编译文件中的操作码,n-gram中n取3。具体原理可以参考这篇文章。与上次实验不同的是,本次实验针对的是安卓软件,所以具体的操作码有所不同。并且由于所采用的数据集中良性软件明显比恶意软件大的多。所以n-gram不再采用出现频次而是是否出现作为特征。
数据集
本次实验的恶意软件数据集来自于Drebin,只采用了第一个part共1000个恶意软件。良性软件来自于这个网站。共1100多个良性软件,取其中的1000个。良性软件集12.3GB,恶意软件集1.2GB。可以看出良性软件要比恶意软件大的多。
反编译
将良性数据集以及恶意数据集软件分别反编译到 smaliskind 以及 smalismalware 中。代码如下
1# -*- coding: utf-8 -*-
"""
Created on Tue Feb 6 14:00:51 2018
@author: 燃烧杯
"""
import os
import subprocess
def disassemble(frompath, topath, num, start=0):
files = os.listdir(frompath)
files = files[start:num]
total = len(files)
for i, file in enumerate(files):
fullFrompath = os.path.join(frompath, file)
fullTopath = os.path.join(topath, file)
command = "apktool d " + fullFrompath + " -o " + fullTopath
subprocess.call(command, shell=True)
print("已反汇编", i, "个应用,百分比如下:")
print((i + 1) * 100 / total, "%")
#反汇编恶意软件样本
virus_root = "..\bit\virus\VirusAndroid"
disassemble(virus_root, ".\smalis\malware", 600)
#反汇编正常软件样本
kind_root = "..\bit\virus\normalApk"
disassemble(kind_root, ".\smalis\kind", 600)
完成后每个软件会创建一个以文件名字命名的文件夹,文件夹中包含反编译后的文件,如下图所示:
其中smali文件夹中包含了我们要提取特征码的文件。smali文件大致如下
我们要提取的操作码就在.method中。操作码大概有下图这几类

将每一类的操作码对应为大写字母以简化特征码。如move表示为M。
操作码提取
代码对应上文提到的github中的bytecode_extract.py文件。
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 6 22:41:06 2018
@author: 燃烧杯
"""
from infrastructure.ware import Ware
from infrastructure.fileutils import DataFile
virusroot = "./smalis/malware"
kindroot = "./smalis/kind"
f = DataFile("./data.csv")
import os
def collect(rootdir, isMalware):
wares = os.listdir(rootdir)
total = len(wares)
for i, ware in enumerate(wares):
warePath = os.path.join(rootdir, ware)
ware = Ware(warePath, isMalware)
ware.extractFeature(f)
print("已提取", i + 1, "个文件的特征,百分比如下:")
print((i + 1) * 100 / total, "%")
#1代表恶意软件
collect(virusroot, 1)
collect(kindroot, 0)
f.close()
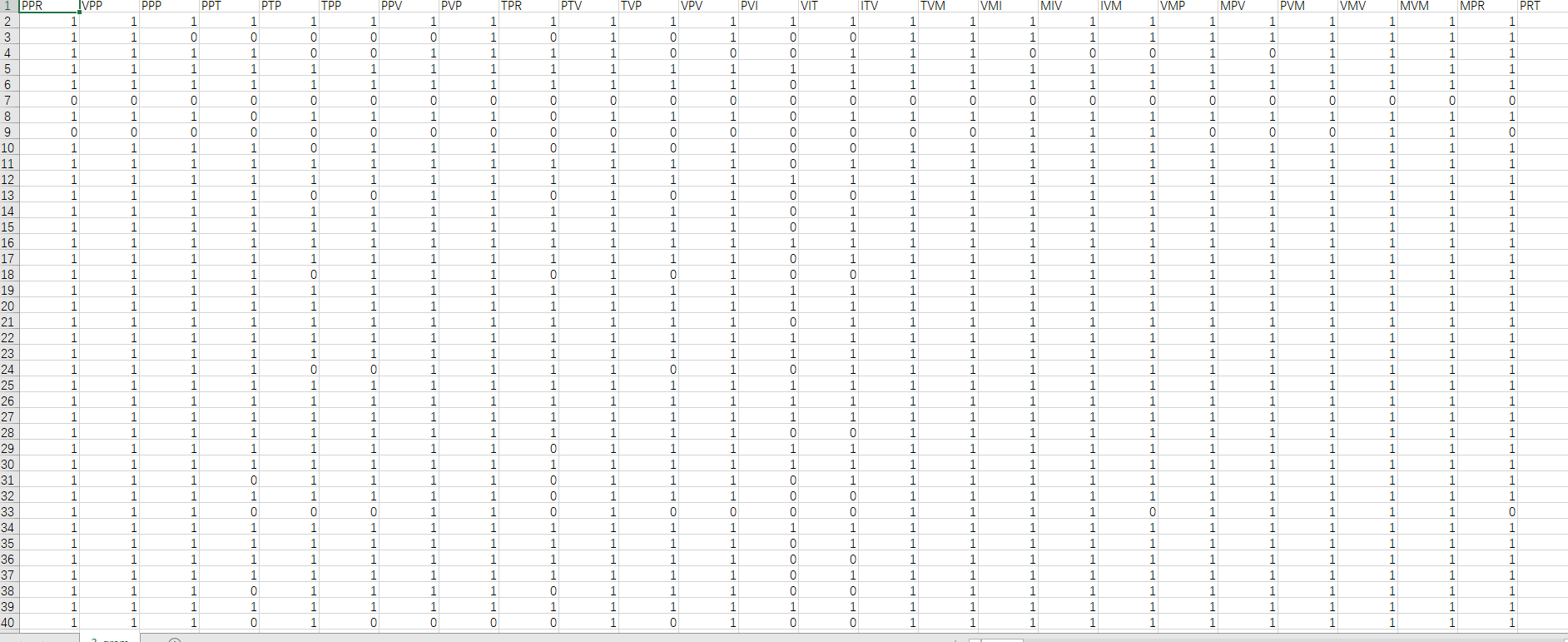
提取出后如下图所示:

feture列就是我们为每个文件提取出的特征。每个方法的特征码序列用“|”隔开。
n-gram特征
从上文的feture中提取出n-gram特征,其数值表示该操作序列是否出现。代码如下
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 9 13:26:50 2018
@author: 燃烧杯
词集模型
"""
import sys
#n-gram的n值
n = int(sys.argv[1])
print("n = ", n)
import pandas as pd
origin = pd.read_csv("data.csv")
#origin = pd.read_csv("test.csv")
from infrastructure.mydict import MyDict
mdict = MyDict()
feature = origin["Feature"].str.split("|")
total = len(feature)
for i, code in enumerate(feature):
mdict.newLayer()
if not type(code) == list:
continue
for method in code:
length = len(method)
if length < n:
continue
for start in range(length - (n - 1)):
end = start + n
mdict.mark(method[start:end])
print("已完成", i, "个应用,百分比如下:")
print((i + 1) * 100 / total, "%")
result = mdict.dict
pd.DataFrame(result, index=origin.index)
.to_csv("./" + str(n) + "_gram.csv", index=False)
结果如图:
形成了2000343的特征表,之所以是343个特征序列是应为总共有7大类操作码,并且采用3-gram,有777个序列。
机器学习
接下来就是训练了,本次实验采用随机森林算法,并采用10交叉验证,代码如下:
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
import pandas as pd
train_feture = pd.read_csv('D:\android\dataset\smalis\3_gram.csv')
data = pd.read_csv('D:\android\dataset\smalis\data.csv')
labels = data["isMalware"]
train_feture = train_feture.iloc[:,:].values
srf = RF(n_estimators=500, n_jobs=-1)
clf_s = cross_val_score(srf, train_feture, labels, cv=10)
结果如下
array([0.965 , 0.995 , 0.995 , 0.96 , 0.89 ,
0.945 , 0.965 , 0.95 , 0.97487437, 0.97487437])
深度学习
顺便用用深度学习做一下分类看看效果,深度学习库采用keras。以下是代码:
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
test_split = 0.2 #划分训练集与测试集
data = pd.read_csv("D:\android\dataset\smalis\data_2.csv")
fetrues = pd.read_csv("D:\android\dataset\smalis\3_gram.csv")
labels = data["isMalware"]
p1 = int(len(labels)*(1-test_split))
index = np.random.permutation(len(fetrues)) #打乱顺序
train_data = fetrues.iloc[index]
labels = labels.iloc[index]
index = np.random.permutation(len(fetrues))
train_data = fetrues.iloc[index]
labels = labels.iloc[index]
model = keras.Sequential()
model.add(layers.Dense(50,input_dim = 343, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.compile(
optimizer = 'adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=60, batch_size=256, validation_data=(x_test, y_test))
测试结果如下:
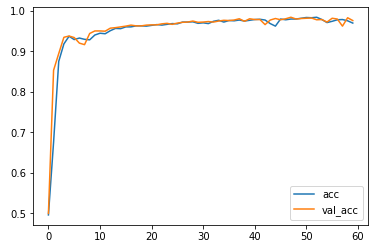
最后10轮精确度如下:
0.9812, 0.9819, 0.9775, 0.9781, 0.9718, 0.9812, 0.9793, 0.9618, 0.9825, 0.9756
另外做10交叉验证,代码如下:
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from sklearn.model_selection import StratifiedKFold
seed = 7
np.random.seed(seed)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
cvscores = []
data = pd.read_csv("D:\android\dataset\smalis\data_2.csv")
labels = data["isMalware"]
train_data = pd.read_csv("D:\android\dataset\smalis\3_gram.csv")
train_data = train_data.iloc[:,:].values
for train, test in kfold.split(train_data, labels):
model = keras.Sequential()
model.add(layers.Dense(50,input_dim = 343, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.compile(
optimizer = 'adam',
loss='binary_crossentropy',
metrics=['acc']
)
model.fit(train_data[train],labels[train],epochs=60, batch_size=256,verbose = 0)
scores = model.evaluate(train_data[test], labels[test], verbose=0)
print(scores[1])
cvscores.append(scores[1])
print(cvscores)
精确度如下:
[0.95, 0.985, 0.95, 0.945, 0.975, 0.95, 0.955, 0.96, 0.9798995, 0.9748744]
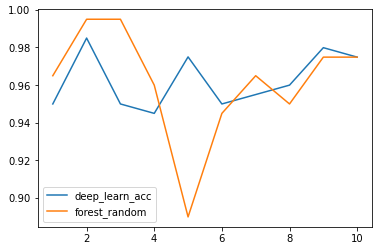
与随机森林对比图;