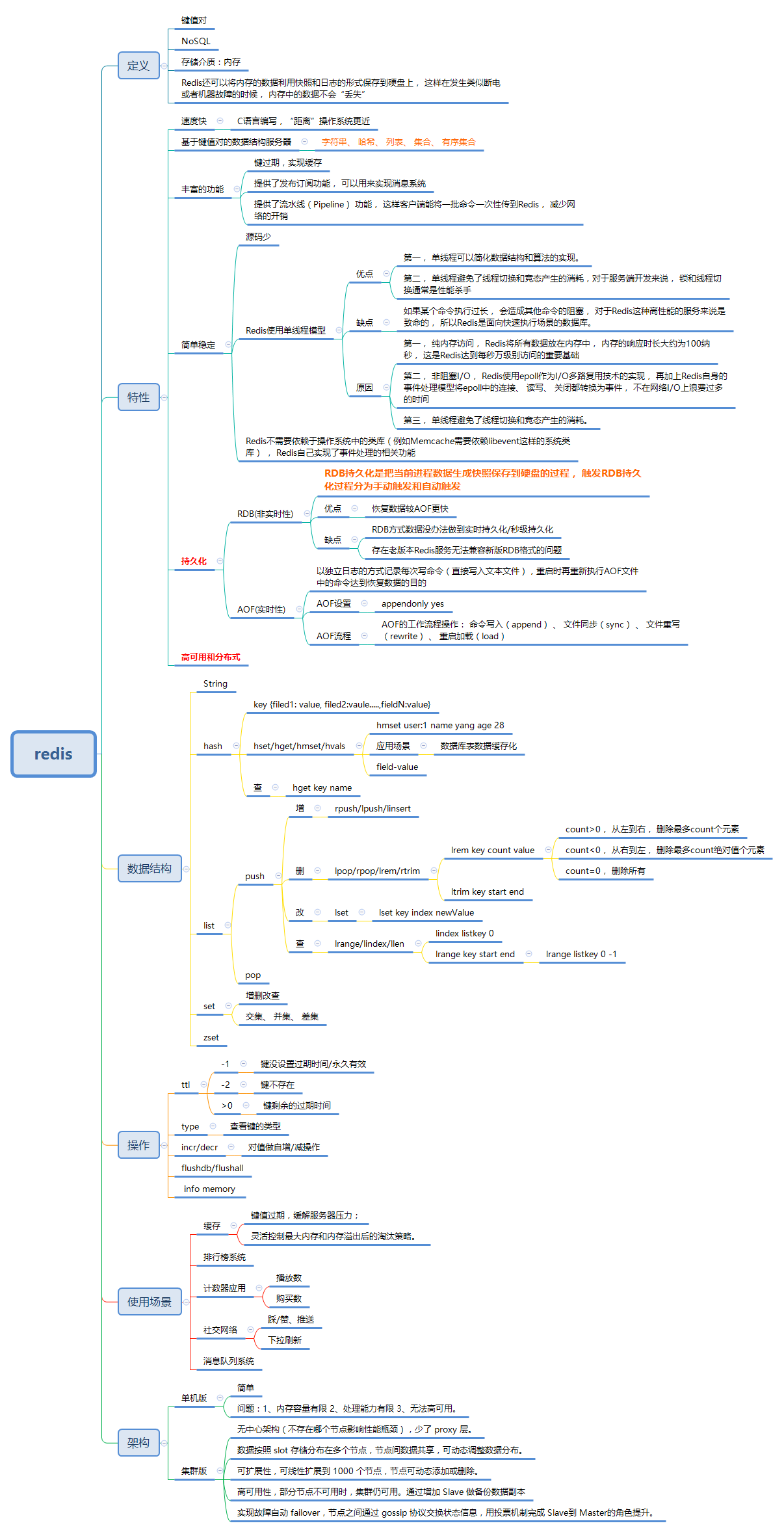
一、redis 简介
redis适合放一些频繁使用,比较热的数据,因为是放在内存中,读写速度都非常快,一般会应用在下面一些场景,排行榜、计数器、消息队列推送、好友关注、粉丝。
首先要知道mysql存储在磁盘里,redis存储在内存里,redis既可以用来做持久存储,也可以做缓存,而目前大多数公司的存储都是mysql + redis,mysql作为主存储,redis作为辅助存储被用作缓存,加快访问读取的速度,提高性能。
官方定义:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs and geospatial indexes with radius queries. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis与MySQL/Oracle的区别:
(1)存储介质:Redis存储在内存,但是可以将数据持久化到硬盘。MySQL/Oracle将数据持久化的存储到硬盘;
(2)数据库类型:Redis属于非关系型数据库;MySQL/Oracle关系型数据库
(3)存取效率:Redis直接在内存中存取数据效率高;MySQL/Oracle每次请求访问数据库时,都存在着I/O操作,如果反复频繁的访问数据库。第一:会在反复链接数据库上花费大量时间,从而导致运行效率过慢;第二:反复的访问数据库也会导致数据库的负载过高。
二、数据类型与常用操作
Redis支持五种数据类型:字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)
字符串(String): 增删改查
set key value
del key
set key newvalue
get key
mset key1 value1 key2 value2 --批量增加
哈希(Hash): key {filed1: value, filed2:vaule.....,fieldN:value}
hset key field_1 value1 -- 增 hmset key field_1 value1 filed_2 value2 --批量增 hdel key filed-- 删 hset key field newValue -- 改 hget key field --查某一field值 hvals filed -- 查key对应的field-values
hlen key --计算field个数
hkeys --获取所有field


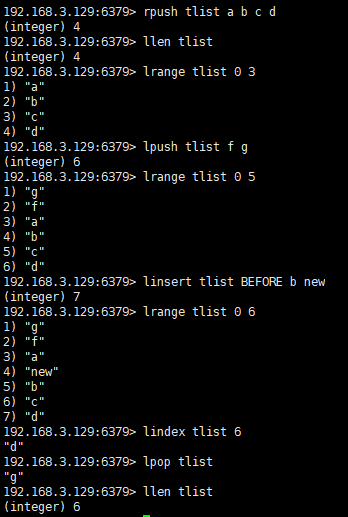
列表(list)
rpush key value [value ...] --右插 lpush key value [value ...] -- 左插 linsert key BEFORE|AFTER pivot value lrange key start stop lindex key index llen key lpop key -- 左弹 rpop key -- 右弹 lset key index value --修改下标index的元素值
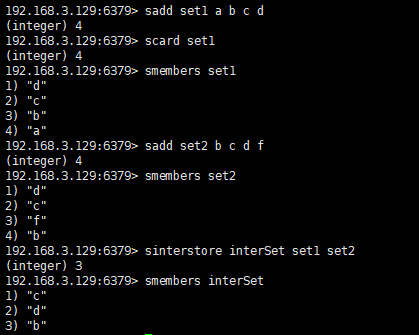
集合(sets) (集合内不允许相同的元素)

-- 集合内元素操作
sadd key element [element ...] --增
srem key element [element ...] --删
scard key --计算元素个数
sismember key element --判断元素是否在集合中
spop key
smembers key --获取所有元素
-- 集合间元素操作
sinter key [key ...] --交集
sunion key [key ...] -- 并集
sdiff key [key ...] --差集
-- 将结果保存
sinterstore destination key [key ...]
suionstore destination key [key ...]
sdiffstore destination key [key ...]
(有序集合) 参考sets
常用操作
ttl -1 键没设置过期时间/永久有效 -2 键不存在 >0 键剩余的过期时间 type --查看键的类型 flushdb/flushall --删除数据 info memory --查看内存信息
select db --选择库
Expire -- 设置过期时间
三、数据持久化
为什么数据持久化?
由于redis的强大性能很大程度上是因为所有数据都是存储在内存中,然而当出现服务器宕机、redis重启等特殊场景,所有存储在内存中的数据将会丢失,这是无法容忍的事情,所以必须将内存数据持久化。例如:将redis作为数据库使用的;将redis作为缓存服务器使用等场景。
持久化存在的方式?
目前持久化存在两种方式:RDB方式和AOF方式。
RDB方式
RDB持久化是把当前进程数据生成快照保存到硬盘的过程, 触发RDB持久化过程分为手动触发和自动触发。一般存在以下情况会对数据进行快照
根据配置规则进行自动快照;
用户执行SAVE, BGSAVE命令;
执行FLUSHALL命令;
执行复制(replication)时。
优缺点:恢复数据较AOF更快;
RDB方式数据没办法做到实时持久化/秒级持久化;存在老版本Redis服务无法兼容新版RDB格式的问题;非实时性。
AOF方式
以独立日志的方式记录每次写命令(写入的内容直接是文本协议格式 ),重启时再重新执行AOF文件中的命令达到恢复数据的目的。
AOF的工作流程操作: 命令写入(append) 、 文件同步(sync) 、 文件重写(rewrite) 、 重启加载(load)
优点:实时性较好
四、redis过期时间
为什么需要设置过期时间?
涉及的业务场景 有数据更新要求(每秒/每天,根据业务的不同,更新频率也不同)
行情数据,则每秒需要更新; 账户资产等数据 ,则满足每天更新即可;
测试案例分析:
1. 内存占用过大问题【问题描述:面对后台一张"表"400w的资金账户数据量(Hadoop HDFS分布式系统存储映射后的其中一张表),中台接口通过impala查询(类似Oracle查询语法)将得到的结果以bitmap的形式存放至Redis,供其它中台接口调用,最终将数据在前端展示。】
经过计算1byte=8bit, 每个客户进行一次查询存储的key占用的内存400w/8/1024/1024=0.47M,粗略估计2000客户进行查询,存储key占用的内存=2000*0.47(将近1G),如果查询频繁,则必然会出现内存溢出的风险。
优化方法:针对客户的操作频率,一般不会不停地进行数据查询操作,所以可以将客户查询存储的key设置过期时间,这样可以减小内存压力。
五、Redis 架构模式
1.单机版
优点:简单;缺点:内存容量有限;处理能力有限;无法高可用
2.集群版
- 无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
- 实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master的角色提升。
附件:redis简易操作的python脚本 链接:https://pan.baidu.com/s/13KTadH68-GRHuHH3ZaPSXw%20%20提取码:klw8
redis思维导图:
链接:https://pan.baidu.com/s/1WPZuTYuxLhfpyDz7OxWE-g
提取码:pp2p