[抄题]:
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index.
According to the definition of h-index on Wikipedia: "A scientist has index h if h of his/her N papers have at least h citations each, and the other N − h papers have no more than h citations each."
Example:
Input:citations = [3,0,6,1,5]Output: 3 Explanation:[3,0,6,1,5]means the researcher has5papers in total and each of them had received3, 0, 6, 1, 5citations respectively. Since the researcher has3papers with at least3citations each and the remaining two with no more than3citations each, his h-index is3.
Note: If there are several possible values for h, the maximum one is taken as the h-index.
[暴力解法]:
时间分析:
空间分析:
[优化后]:
时间分析:
空间分析:
[奇葩输出条件]:
[奇葩corner case]:
[思维问题]:
以为n篇文章的引用量,有什么相互关系:并没有
[一句话思路]:
[输入量]:空: 正常情况:特大:特小:程序里处理到的特殊情况:异常情况(不合法不合理的输入):
[画图]:
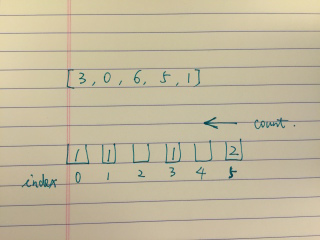
[一刷]:
- 累加数组元素的时候最好用一个新的sum 变量,也不占空间。加到数组元素上容易出现范围错误。
[二刷]:
[三刷]:
[四刷]:
[五刷]:
[五分钟肉眼debug的结果]:
[总结]:
[复杂度]:Time complexity: O(就是n) Space complexity: O(n)
[英文数据结构或算法,为什么不用别的数据结构或算法]:
这题比较特殊,数组元素 = 个数(也可以理解为桶排序)
计数排序(Counting sort)是一种稳定的线性时间排序算法。
计数排序使用一个额外的数组 {displaystyle C} C ,其中第i个元素是待排序数组 {displaystyle A} A中值等于 {displaystyle i} i的元素的个数。
然后根据数组 {displaystyle C} C 来将 {displaystyle A} A中的元素排到正确的位置。
[算法思想:递归/分治/贪心]:
[关键模板化代码]:
//for loop : add to bucket for (int c : citations) { if (c > n) bucket[n]++; else bucket[c]++; }
[其他解法]:
[Follow Up]:
排序后:
[LC给出的题目变变变]:
[代码风格] :


class Solution { public int hIndex(int[] citations) { //cc if (citations == null || citations.length == 0) return 0; //ini: bucket[n + 1] form exception int n = citations.length; int[] bucket = new int[n + 1]; //for loop : add to bucket for (int c : citations) { if (c > n) bucket[n]++; else bucket[c]++; } //count from back int count = 0; for (int i = n; i >= 0; i--) { count += bucket[i]; if (count >= i) return i; } return 0; } }