【I/O流的分类】

左边input读字,右边的reader读文件file
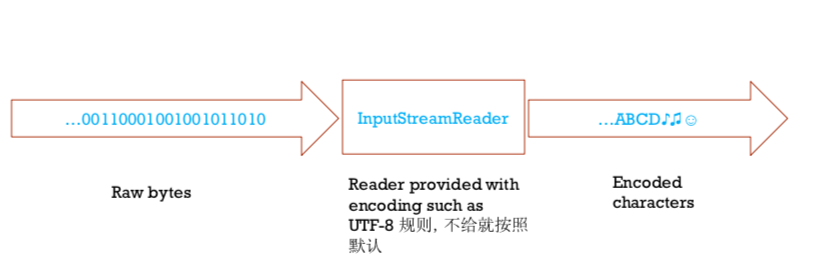
左边是byte, 右边是character(用default encoding,不能自己选,要自己选就要加inputstreamreader或者outputstreamwriter)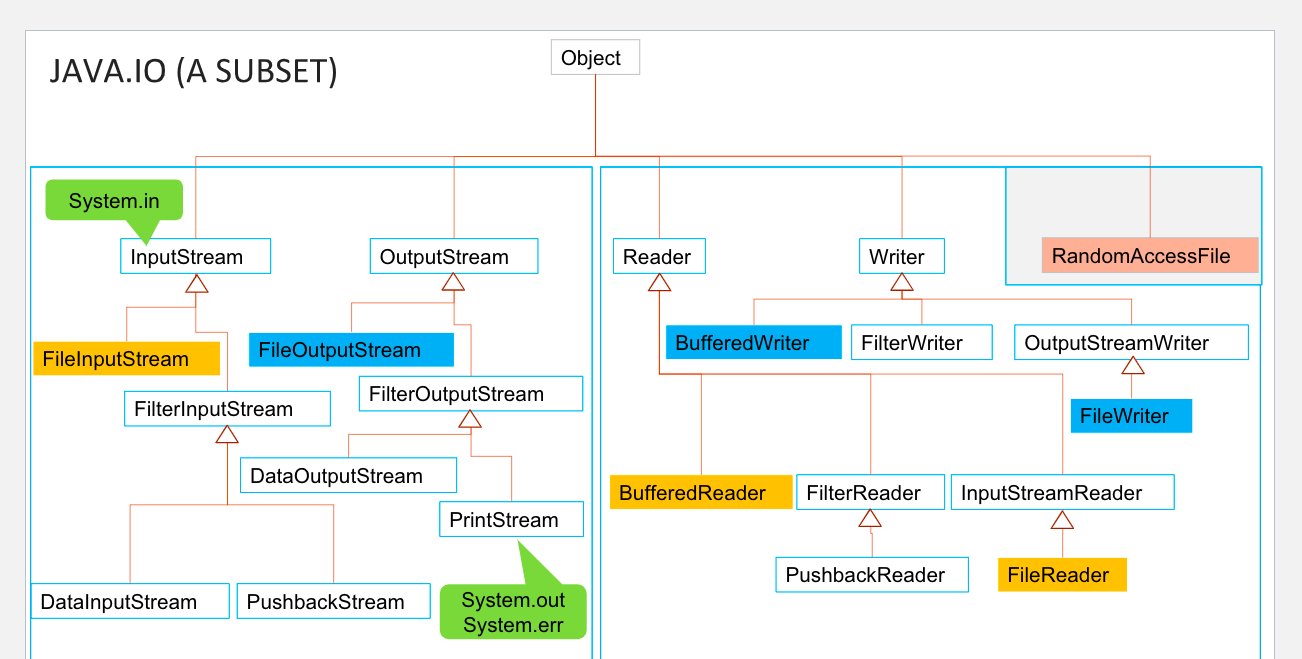
inputstream/outputstream:一次读一个byte
inputstreamREADER/outputstreamWRITER的机制:把byte(一次读1个byte)转成char,用specifiec encoding可以自己选
数字用input/outputstream,先写后读,后面的形式不同

filestream会把所有数据都转成binary类
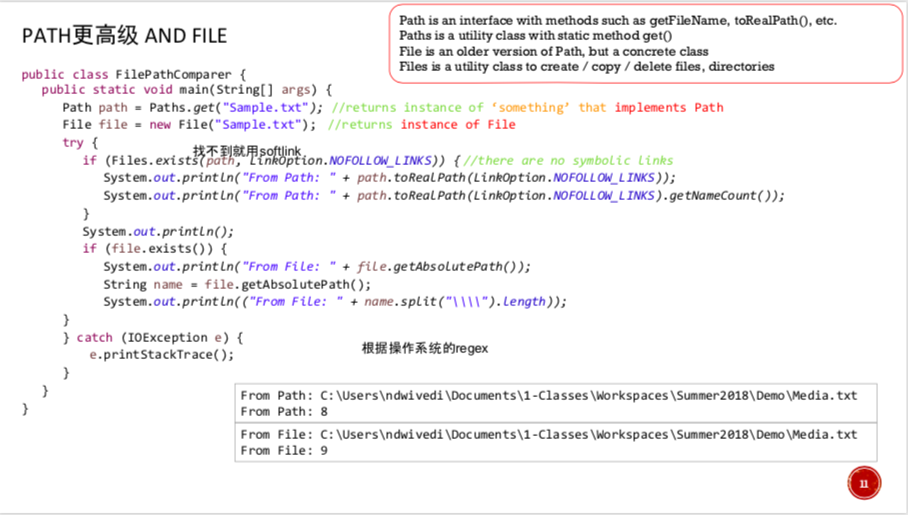
【paths是静态类,可以返回一个path】
路径Path:
一个界面
表示由一系列目录和文件名元素组成的分层路径,这些元素由特殊的分隔符或分隔符分隔。
档File
此类仅包含对文件,目录或其他类型文件进行操作的静态方法
例如。 copy(),createFile(),createDitectory()等。用于复制粘贴。
File是path的更古老版本,但是是一个实体类
不包括根目录,比如:8级
路径
此类仅包含通过转换路径字符串或URI返回Path的静态方法。
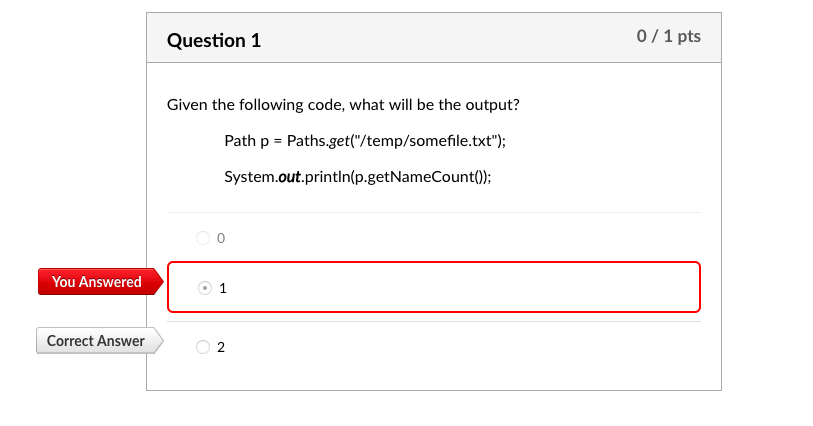
例如。 路径p1 = Paths.get(“/ tmp / foo”);
用.get方法: Path p = Paths.get("/temp/somefile.txt")得到的是路径:/temp/somefile.txt
找完全路径用toRealPath()
包括根目录,比如:9级
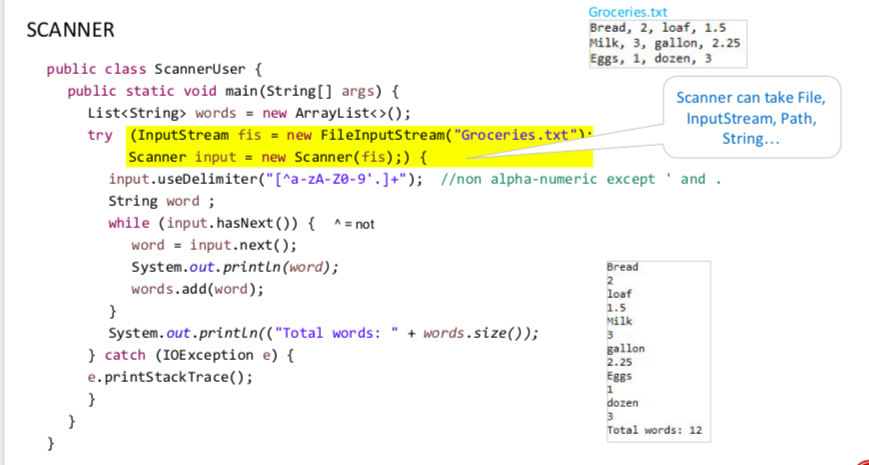
scanner的参数可以是file, input string, path, string...(好处: Scanner offers text pattern-recognition)
默认用space分隔,不是逗号
【NIO增加了/基于 mappedbytebuffer的性能 非阻塞,不能代替IO】
都是带buffer的

【用于读取的类】
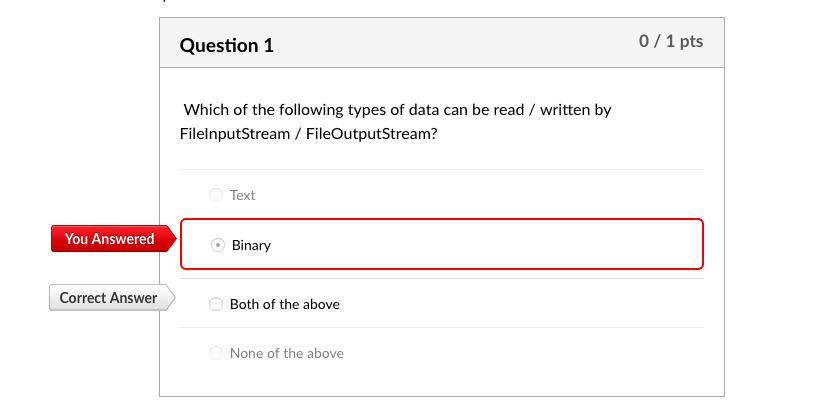
FileInputStream FileOutputStream:both text and binary files, to binary
FileReader and FileWriter:text files
【使用buffer来优化读写的方法】
一次可以读很多,默认size = 8k
。。。writer。。。
包含关系:byte - char - constructor里有inputstreamreader or filereader - buffereader
【scanner可以自己识别nextLine,默认用space隔开】
按斜杠分割