一.(测试时间:20151220 - 下午14:00-17:00)
windows环境
第一次测试,运行中发现在eclipse环境下.4w个连接耗尽了约1G的内存.
另外:服务本来可用的,压测客户端强制关闭,造成大量的session需要清理,这时候会造成拒绝服务现象,新连接无法建立..
session Close是锁住进行的?
二.(测试时间:20151223 - 晚上18:00-19:20)
linux 64位虚拟机 - 开集群(每秒15个连接)
压测5W,小卡顿,但是能用,到5.9w,突然完全卡死.无法建立新的连接
telent 127.0.0.1 5222 无反应
当通过集群查看内存正常,无高占用,GC后还不到1G.
三.(测试时间:20151223 - 晚上18:00-19:40)
linux 64位虚拟机 - 不开集群(每秒40个连接,2台tsung)
2W个连接开始堵,psi登录需要3分钟才连接上.
4w连接后,psi登录用了6分钟,每个报文送过去,回来都要1分30秒.-2分钟等个登陆流程用了15分钟
5.9w连接后,psi登录不了,同上
telent 127.0.0.1 5222 无反应
注:Linux可调整网络参数
四.(测试时间:20151224 - 8:20-11:00)
linux 64位虚拟机 - 不开集群(每秒30个连接,2台tsung)
2W个连接开始堵,psi登录需要1分钟才连接上.10点到达峰值10w连接.
此时telent 127.0.0.1 5222 连接正常.
结论:优化网络配置后,10w并发单机正常运行.
五.(测试时间:20151224 - 16:20-11:00)
windows环境 64位 - 开集群(每秒15+7个连接)
5w连接正常.1秒登录.到8w并发,出现卡顿.登录用时15秒.9w连接.使用1.2G内存(FULL GC后)
但在一台tsung不发起新连接后,接入事件又变快.cpu使用率很高,70%以上.
OpenJDK虚拟机不行.
六.(测试时间:20151224 - 18:20-21:00)
Linux环境 64位 - 开集群(每秒9+9个连接)
3w连接正常.1秒登录.10w连接.使用1.2G内存(FULL GC后)
七.(测试时间:20151225 - 8:40-12:00)
Linux环境 64位(使用oracle JDK) - 开集群(每秒20个连接)
6w连接正常.1秒登录.10w连接.使用1.2G内存(FULL GC后),cpu,内存均正常.说明用了oracle的HotSpot确实不错.
八.(测试时间:20151228 - 17:30-20:30)
Linux环境 64位(使用oracle JDK) - 开集群(每秒20个连接)
三台tsung同时测试,10w连接.使用1.2G内存,16w连接,使用2G内存.只分配3g内存,GC频率增加,出现卡顿现象.
九.(测试时间:20160117- 9:30-12:30)
inux环境 64位(使用oracle JDK) - 开集群(每秒100个连接)
1.序列化优化
2.tsung无chat交易,仅仅登陆
三台tsung同时测试,18w连接.使用1.4G内存,
十.(测试时间:20160119 - 18:00-21:30)
Linux环境 64位(使用oracle JDK) - 开集群(每秒90个连接)
启动3台服务器,均开4G内存.其中2台运行在同一台实体机器上.
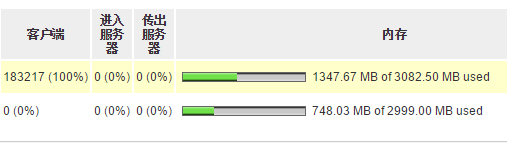
启动9台tsung客户机,tsung每台分配1g内存,跑3台centos已经是极限了.内存基本吃完.如下图:

在运行1个小时50分钟后,大约有35w连接,突然出现无响应.psi也无法发出新连接请求.

十一.(测试时间:20160120 - 09:30-11:30)
1台Window环境 64位,1台Linux环境 64位(5G内存),开集群(每秒100个连接)
前面运行正常,当Linux用户数到达14w,系统卡死,全在GC,且影响另外一台设备.两台均无法正常登录.
后续策略:调整内存大小,修改hazelcast的驱逐策略.在linux上再次运行,并跟踪GC
十二.(测试时间:20160121 - 18:00-19:30)
1台Window环境 64位,1台Linux环境 64位(5G内存),开集群(每秒120个连接)
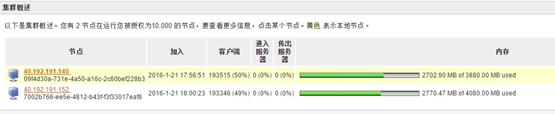
Window给5G,Linux给5G,两机用户均正常稳步增加,达到19w+.如下图:
内存使用情况,如下图:
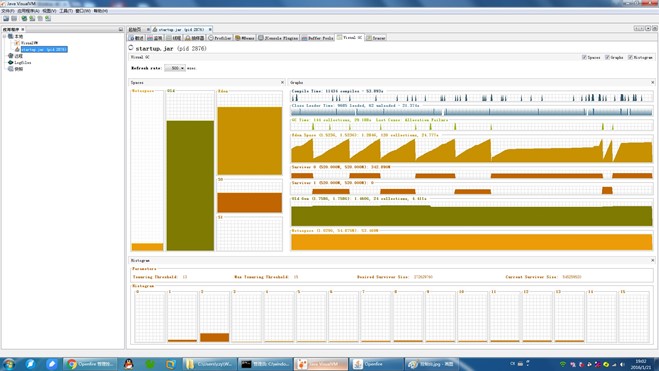
不过Linux会出现OldGen区突然满的情况..修改为JDK1.7后也偶尔会(虚拟机的问题??).
十二.(测试时间:20160124 - 11:00-12:30)
1台Window环境 64位(16G),2台Linux环境 64位(6G内存-虚拟机),开集群(每秒125个连接)
6G内存分配5G个openfire.显然不够.运行一个半小时,linux内存满了,GC无效.
十三.(测试时间:20160124 - 18:15-20:20)
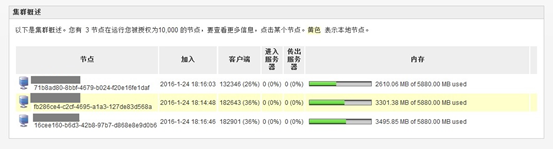
3台Linux环境 64位(8G内存-虚拟机),开集群(每秒100个连接)
内存分配6G个openfire.运行2个小时,用户达到50W(9台tsungClient,有2台只有5w连接,一台只有3w连接)