本次分享者:辰石,来自阿里巴巴计算平台事业部EMR团队技术专家,目前从事大数据存储以及Spark相关方面的工作。
- Spark Shuffle介绍
- Smart Shuffle设计
- 性能分析
Spark Shuffle流程
Spark 0.8及以前 Hash Based Shuffle
Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
Spark 0.9 引入ExternalAppendOnlyMap
Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle
Spark 1.4 引入Tungsten-Sort Based Shuffle
Spark 1.6 Tungsten-sort并入Sort Based Shuffle
Spark 2.0 Hash Based Shuffle退出历史舞台
总结一下, 就是最开始的时候使用的是 Hash Based Shuffle, 这时候每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M x R ,其中M是Map的个数,R是Reduce的个数。这样会产生大量的小文件,对文件系统压力很大,而且也不利于IO吞吐量。后面忍不了了就做了优化,把在同一core上运行的多个Mapper 输出的合并到同一个文件,这样文件数目就变成了 cores x R 个了。
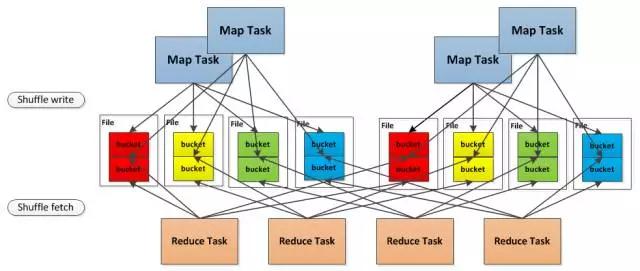
Spark Shuffle实现
Sort-based shuffle介绍
这个方式的选择是在org.apache.spark.SparkEnv完成的:
// Let the user specify short names forshuffle managers
val shortShuffleMgrNames = Map(
"hash" ->"org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" ->"org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName =conf.get("spark.shuffle.manager", "sort") //获得Shuffle Manager的type,sort为默认
val shuffleMgrClass =shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager =instantiateClass[ShuffleManager](shuffleMgrClass)
Hashbased shuffle的每个mapper都需要为每个reducer写一个文件,供reducer读取,即需要产生M x R个数量的文件,如果mapper和reducer的数量比较大,产生的文件数会非常多。Hash based shuffle设计的目标之一就是避免不需要的排序(Hadoop Map Reduce被人诟病的地方,很多不需要sort的地方的sort导致了不必要的开销)。但是它在处理超大规模数据集的时候,产生了大量的DiskIO和内存的消耗,这无疑很影响性能。Hash based shuffle也在不断的优化中,正如前面讲到的Spark 0.8.1引入的file consolidation在一定程度上解决了这个问题。为了更好的解决这个问题,Spark 1.1 引入了Sort based shuffle。首先,每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个index文件,Reducer可以通过这个index文件取得它需要处理的数据。避免产生大量的文件的直接收益就是节省了内存的使用和顺序Disk IO带来的低延时。节省内存的使用可以减少GC的风险和频率。而减少文件的数量可以避免同时写多个文件对系统带来的压力。
目前writer的实现分为三种, 分为 BypassMergeSortShuffleWriter, SortShuffleWriter 和 UnsafeShuffleWriter。
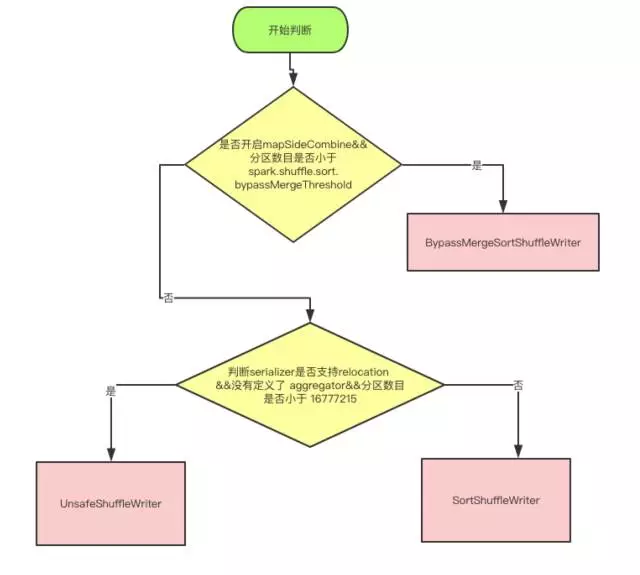
SortShuffleManager只有BlockStoreShuffleReader这一种ShuffleReader。
Spark-shuffle存在的问题
同步操作
Shuffle数据只有等map task任务结束后可能会触发多路归并生成最终数据。
大量的磁盘IO
Shuffle的数据在Merge阶段存在大量的磁盘读写IO,在sort-merge阶段对磁盘IO带宽要求较高。
计算与网络的串行
Task任务计算和网络IO的串行操作。
Smart Shuffle

shuffle数据的pipeline
shuffle数据在map端累积到一定数量发送到reduce端。
避免不必要的网络IO
根据partition数量的位置,可以调度该reduce任务到相应的节点。
计算和网络IO的异步化
shuffle数据的生成和shuffle数据的发送可以并行执行。
避免sort-merge减少磁盘IO
shuffle数据是按照partition进行分区,shuffle数据无需sort-merge
Smart Shuffle使用
- 配置spark.shuffle.manager : org.apache.spark.shuffle.hash.HashShuffleManager
- 配置spark.shuffle.smart.spill.memorySizeForceSpillThreshold:控制shuffle数据占用内存的大小,默认为128M
- 配置spark.shuffle.smart.transfer.blockSize:控制shuffle在网络传输数据块的大小
性能分析
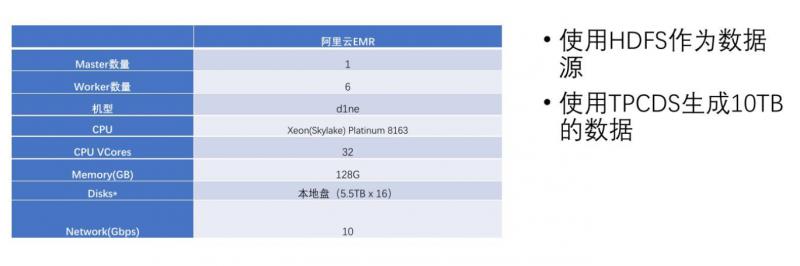
硬件及软件资源:
TPC-DS性能:
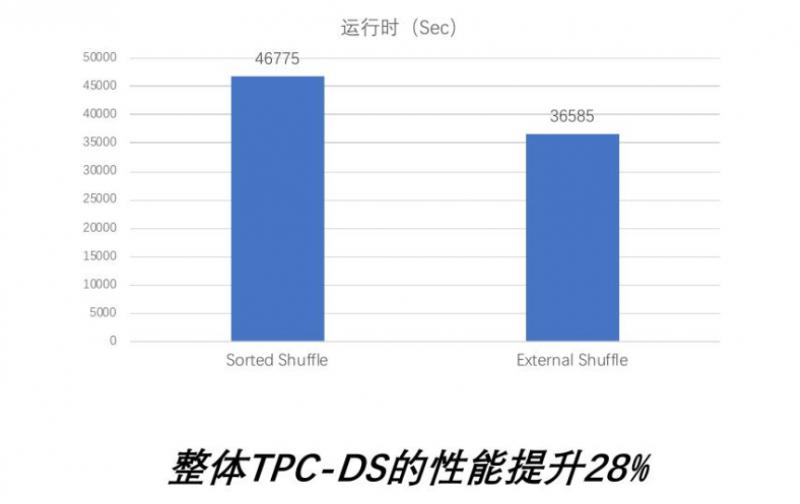
Smart shuffle TPC-DS性能提升28%:
- Smart shuffle没有打来单个query性能的下降
- 单个query最大能够带来最大2倍的性能提升
提取Q2和Q49查询性能分析:
- Q2在两种shuffle性能保持一致
- Q49在Smart shuffle下性能有很大提升
单个查询对比:

左侧为sorted shuffle,右边为smart shuffle。
Q2查询相对简单,shuffle数据也比较少,smart shuffle性能保持不变。
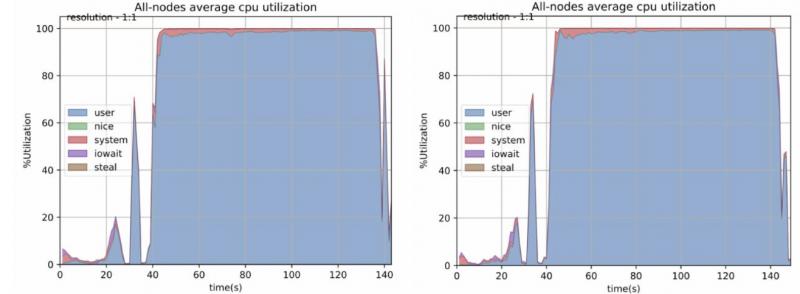
Q2 CPU对比:
左侧为sorted shuffle,右侧是smart shuffle
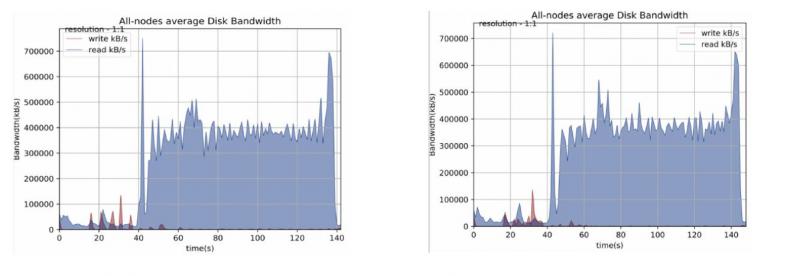
磁盘对比:
左侧为sorted shuffle,右侧是smart shuffle
声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?