小编在去年的时候,写过一篇轰动全网的文章《你需要的不是实时数仓 | 你需要的是一款强大的OLAP数据库》,这篇文章当时被各大门户网站和自媒体疯狂转载,保守阅读量也在50万+UV,在这篇文章中提到过Preto,Presto作为OLAP计算领域的一员有着独特的优势和特点。
本篇文章是作者作为Presto小白时期,经过调研、线上调试、生产环境稳定运行这个过程中大量的实践经验和资料检索,沉淀下来的一个读书笔记。本文从原理入门、线上调优、典型应用等几个方面为读者全面剖析Presto,希望对大家有帮助。
我是谁?我从哪里来?要到哪里去?
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.
Presto is targeted at analysts who expect response times ranging from sub-second to minutes. Presto breaks the false choice between having fast analytics using an expensive commercial solution or using a slow "free" solution that requires excessive hardware.
这是官网对Presto的定义,Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,适用于交互式分析查询,可支持众多的数据源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的接口开发数据源连接器。
Presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
- 丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
为了给大家一个更为清晰一点的印象,我们可以把Presto和Mysql进行一下对比:
首先Mysql是一个数据库,具有存储和计算分析能力,而Presto只有计算分析能力;其次数据量方面,Mysql作为传统单点关系型数据库不能满足当前大数据量的需求,于是有各种大数据的存储和分析工具产生,Presto就是这样一个可以满足大数据量分析计算需求的一个工具。
一览无余之Presto的架构
我们借用美团的博客中的一张架构图:

Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
Presto的服务进程
Presto集群中有两种进程,Coordinator服务进程和worker服务进程。coordinator主要作用是接收查询请求,解析查询语句,生成查询执行计划,任务调度和worker管理。worker服务进程执行被分解的查询执行任务task。
Coordinator 服务进程部署在集群中的单独节点之中,是整个presto集群的管理节点,主要作用是接收查询请求,解析查询语句,生成查询执行计划Stage和Task并对生成的Task进行任务调度,和worker管理。Coordinator进程是整个Presto集群的master进程,需要与worker进行通信,获取最新的worker信息,有需要和client通信,接收查询请求。Coordinator提供REST服务来完成这些工作。
Presto集群中存在一个Coordinator和多个Worker节点,每个Worker节点上都会存在一个worker服务进程,主要进行数据的处理以及Task的执行。worker服务进程每隔一定的时间会发送心跳包给Coordinator。Coordinator接收到查询请求后会从当前存活的worker中选择合适的节点运行task。
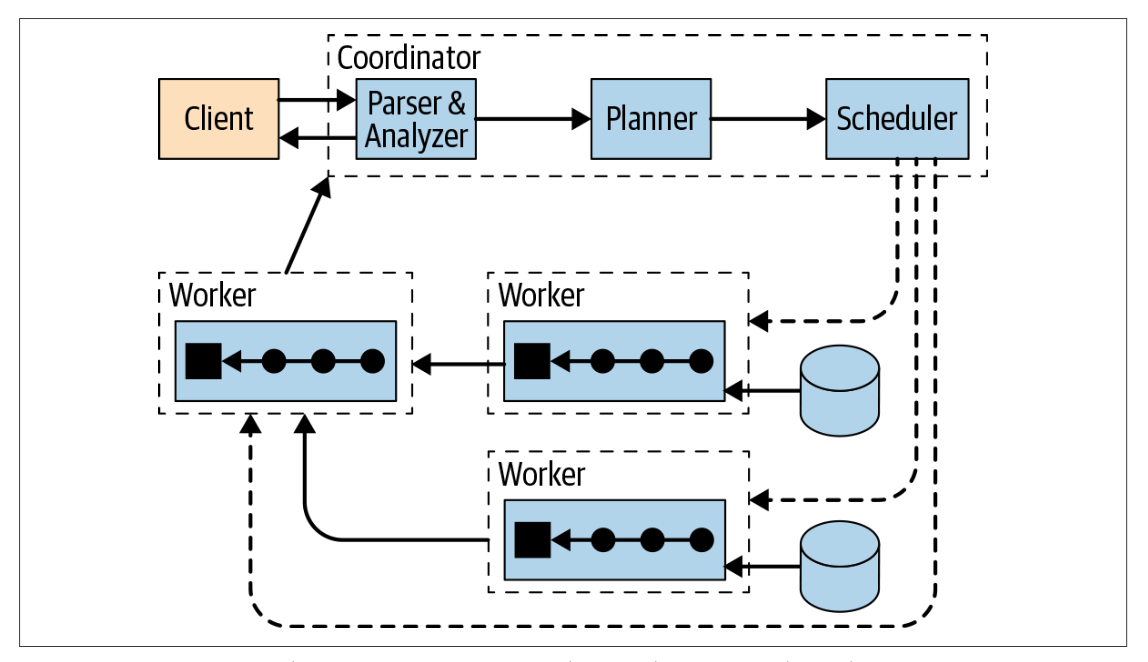
上图展示了从宏观层面概括了Presto的集群组件:1个coordinator,多个worker节点。用户通过客户端连接到coordinator,可以短可以是JDBC驱动或者Presto命令行cli。
Presto是一个分布式的SQL查询引擎,组装了多个并行计算的数据库和查询引擎(这就是MPP模型的定义)。Presto不是依赖单机环境的垂直扩展性。她有能力在水平方向,把所有的处理分布到集群内的各个机器上。这意味着你可以通过添加更多节点来获得更大的处理能力。
利用这种架构,Presto查询引擎能够并行的在集群的各个机器上,处理大规模数据的SQL查询。Presto在每个节点上都是单进程的服务。多个节点都运行Presto,相互之间通过配置相互协作,组成了一个完整的Presto集群。

上图展示了集群内coordinator和worker之间,以及worker和worker之间的通信。coordinator向多个worker通信,用于分配任务,更新状态,获得最终的结果返回用户。worker之间相互通信,向任务的上游节点获取数据。所有的worker都会向数据源读取数据。
Coordinator
Coordinator的作用是:
- 从用户获得SQL语句
- 解析SQL语句
- 规划查询的执行计划
- 管理worker节点状态
Coordinator是Presto集群的大脑,并且是负责和客户端沟通。用户通过PrestoCLI、JDBC、ODBC驱动、其他语言工具库等工具和coordinator进行交互。Coordinator从客户端接受SQL语句,例如select语句,才能进行计算。
每个Presto集群必须有一个coordinator,可以有一个或多个worker。在开发和测试环境中,一个Presto进程可以同时配置成两种角色。Coordinator追踪每个worker上的活动,并且协调查询的执行过程。Coordinator给查询创建了一个包含多阶段的逻辑模型,一旦接受了SQL语句,Coordinator就负责解析、分析、规划、调度查询在多个worker节点上的执行过程,语句被翻译成一系列的任务,跑在多个worker节点上。worker一边处理数据,结果会被coordinator拿走并且放到output缓存区上,暴露给客户端。一旦输出缓冲区被客户完全读取,coordinator会代表客户端向worker读取更多数据。worker节点,和数据源打交道,从数据源获取数据。因此,客户端源源不断的读取数据,数据源源源不断的提供数据,直到查询执行结束。
Coordinator通过基于HTTP的协议和worker、客户端之间进行通信。
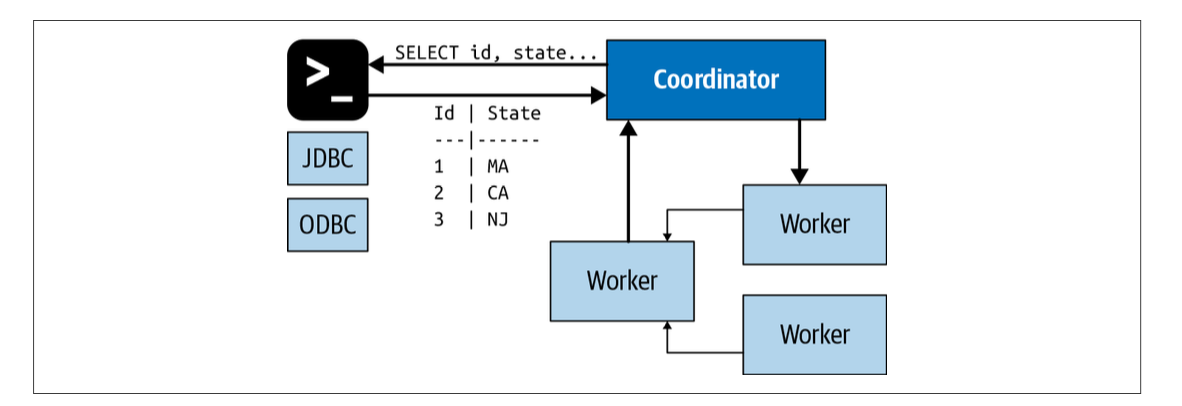
上图给我们展示了客户端、coordinator,worker之间的通信。
Workers
Presto的worker是Presto集群中的一个服务。它负责运行coordinator指派给它的任务,并处理数据。worker节点通过连接器(connector)向数据源获取数据,并且相互之间可以交换数据。最终结果会传递给coordinator。 coordinator负责从worker获取最终结果,并传递给客户端。
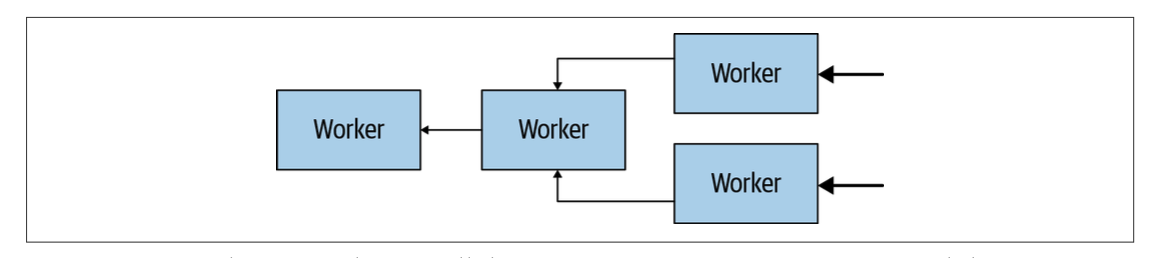
Worker之间的通信、worker和coordinator之间的通信采用基于HTTP的协议。下图展示了多个worker如何从数据源获取数据,并且合作处理数据的流程。直到某一个worker把数据提供给了coordinator。
一层一层剥开你的心之Presto数据模型
Presto采取了三层表结构,我们可以和Mysql做一下类比:
- catalog 对应某一类数据源,例如hive的数据,或mysql的数据
- schema 对应mysql中的数据库
- table 对应mysql中的表
在Presto中定位一张表,一般是catalog为根,例如:一张表的全称为 hive.testdata.test,标识 hive(catalog)下的 testdata(schema)中test表。
可以简理解为:数据源.数据库.数据表。
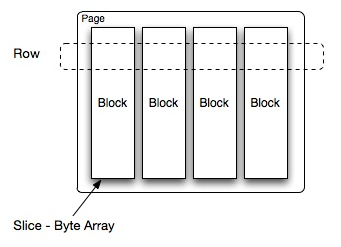
另外,presto的存储单元包括:
- Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
Presto中处理的最小数据单元是一个Page对象,Page对象的数据结构如下图所示。一个Page对象包含多个Block对象,每个Block对象是一个字节数组,存储一个字段的若干行。多个Block横切的一行是真实的一行数据。一个Page最大1MB,最多16 * 1024行数据。
核心问题之Presto为什么这么快?
我们在选择Presto时很大一个考量就是计算速度,因为一个类似SparkSQL的计算引擎如果没有速度和效率加持,那么很快就就会被抛弃。
美团的博客中给出了这个答案:
- 完全基于内存的并行计算
- 流水线式的处理
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- 类BlinkDB的近似查询
- GC控制
和Hive这种需要调度生成计划且需要中间落盘的核心优势在于:Presto是常驻任务,接受请求立即执行,全内存并行计算;Hive需要用yarn做资源调度,接受查询需要先申请资源,启动进程,并且中间结果会经过磁盘。
欲先攻其事,必先利其器之Presto调优
合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用snappy压缩
预排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
内存调优
Presto有三种内存池,分别为GENERAL_POOL、RESERVED_POOL、SYSTEM_POOL。这三个内存池占用的内存大小是由下面算法进行分配的:
builder.put(RESERVED_POOL, new MemoryPool(RESERVED_POOL, config.getMaxQueryMemoryPerNode()));
builder.put(SYSTEM_POOL, new MemoryPool(SYSTEM_POOL, systemMemoryConfig.getReservedSystemMemory()));
long maxHeap = Runtime.getRuntime().maxMemory();
maxMemory = new DataSize(maxHeap - systemMemoryConfig.getReservedSystemMemory().toBytes(), BYTE);
DataSize generalPoolSize = new DataSize(Math.max(0, maxMemory.toBytes() - config.getMaxQueryMemoryPerNode().toBytes()), BYTE);
builder.put(GENERAL_POOL, new MemoryPool(GENERAL_POOL, generalPoolSize));
简单的说,RESERVED_POOL大小由config.properties里的query.max-memory-per-node指定;SYSTEM_POOL由config.properties里的resources.reserved-system-memory指定,如果不指定,默认值为Runtime.getRuntime().maxMemory() * 0.4,即0.4 * Xmx值;而GENERAL_POOL值为 总内存(Xmx值)- 预留的(max-memory-per-node)- 系统的(0.4 * Xmx)。
从Presto的开发手册中可以看到:
GENERAL_POOL is the memory pool used by the physical operators in a query.
SYSTEM_POOL is mostly used by the exchange buffers and readers/writers.
RESERVED_POOL is for running a large query when the general pool becomes full.
简单说GENERAL_POOL用于普通查询的physical operators;SYSTEM_POOL用于读写buffer;而RESERVED_POOL比较特殊,大部分时间里是不参与计算的,只有当同时满足如下情形下,才会被使用,然后从所有查询里获取占用内存最大的那个查询,然后将该查询放到 RESERVED_POOL 里执行,同时注意RESERVED_POOL只能用于一个Query。
我们经常遇到的几个错误:
Query exceeded per-node total memory limit of xx
适当增加query.max-total-memory-per-node。
Query exceeded distributed user memory limit of xx
适当增加query.max-memory。
Could not communicate with the remote task. The node may have crashed or be under too much load
内存不够,导致节点crash,可以查看/var/log/message。
并行度
我们可以通过调整线程数增大task的并发以提高效率。

SQL优化
- 只选择使用必要的字段: 由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用 * 读取所有字段
- 过滤条件必须加上分区字段
- Group By语句优化: 合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列, 减少GROUP BY语句后面的排序一句字段的数量能减少内存的使用.
- Order by时使用Limit, 尽量避免ORDER BY: Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存
- 使用近似聚合函数: 对于允许有少量误差的查询场景,使用这些函数对查询性能有大幅提升。比如使用approx_distinct() 函数比Count(distinct x)有大概2.3%的误差
- 用regexp_like代替多个like语句: Presto查询优化器没有对多个like语句进行优化,使用regexp_like对性能有较大提升
- 使用Join语句时将大表放在左边: Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
- 使用Rank函数代替row_number函数来获取Top N
- UNION ALL 代替 UNION :不用去重
- 使用WITH语句: 查询语句非常复杂或者有多层嵌套的子查询,请试着用WITH语句将子查询分离出来
当然还有很多优化的方式,建议大家都在网上搜一些资料,并且参考Presto操作手册。
它山之石可以攻玉之行业典型应用
这部分内容是小编参考的各大公司的行业应用进行的总结,目的是可以帮大家找到适合自己公司业务的应用方式。具体的原文可以再最后的参考链接中找到。
Presto 在滴滴的应用
滴滴 Presto 用了3年时间逐渐接入公司各大数据平台,并成为了公司首选 Ad-Hoc 查询引擎及 Hive SQL 加速引擎,支持了包含以下的业务场景:
- Hive SQL查询加速
- 数据平台Ad-Hoc查询
- 报表(BI报表、自定义报表)
- 活动营销
- 数据质量检测
- 资产管理
- 固定数据产品
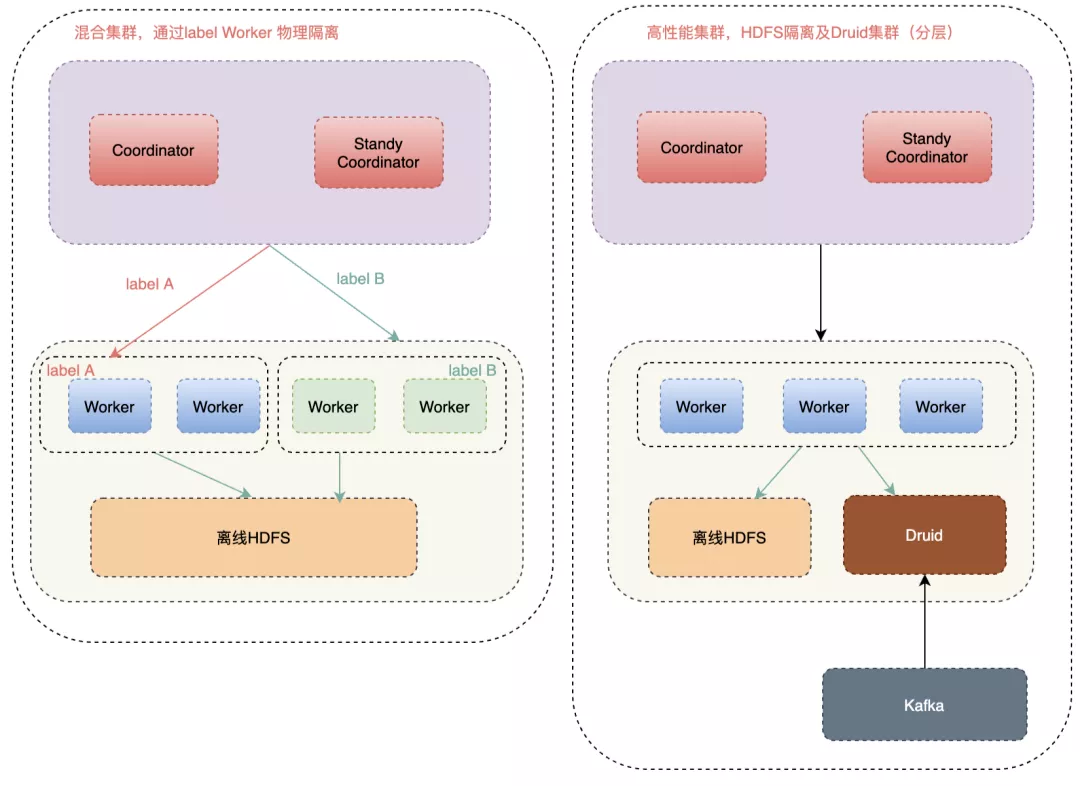
为了适配各个业务线,二次开发了 JDBC、Go、Python、Cli、R、NodeJs 、HTTP 等多种接入方式,打通了公司内部权限体系,让业务方方便快捷的接入 Presto 的,满足了业务方多种技术栈的接入需求。
Presto 接入了查询路由 Gateway,Gateway 会智能选择合适的引擎,用户查询优先请求 Presto,如果查询失败,会使用 Spark 查询,如果依然失败,最后会请求 Hive。在 Gateway 层,我们做了一些优化来区分大查询、中查询及小查询,对于查询时间小于 3 分钟的,我们即认为适合 Presto 查询,比如通过 HBO(基于历史的统计信息)及 JOIN 数量来区分查询大小,架构图如下:
在滴滴内部,Presto 主要用于 Ad-Hoc 查询及 Hive SQL 查询加速,为了方便用户能尽快将 SQL 迁移到 Presto 引擎上,且提高 Presto 引擎查询性能,我们对 Presto 做了大量二次开发。这些功能主要包括:
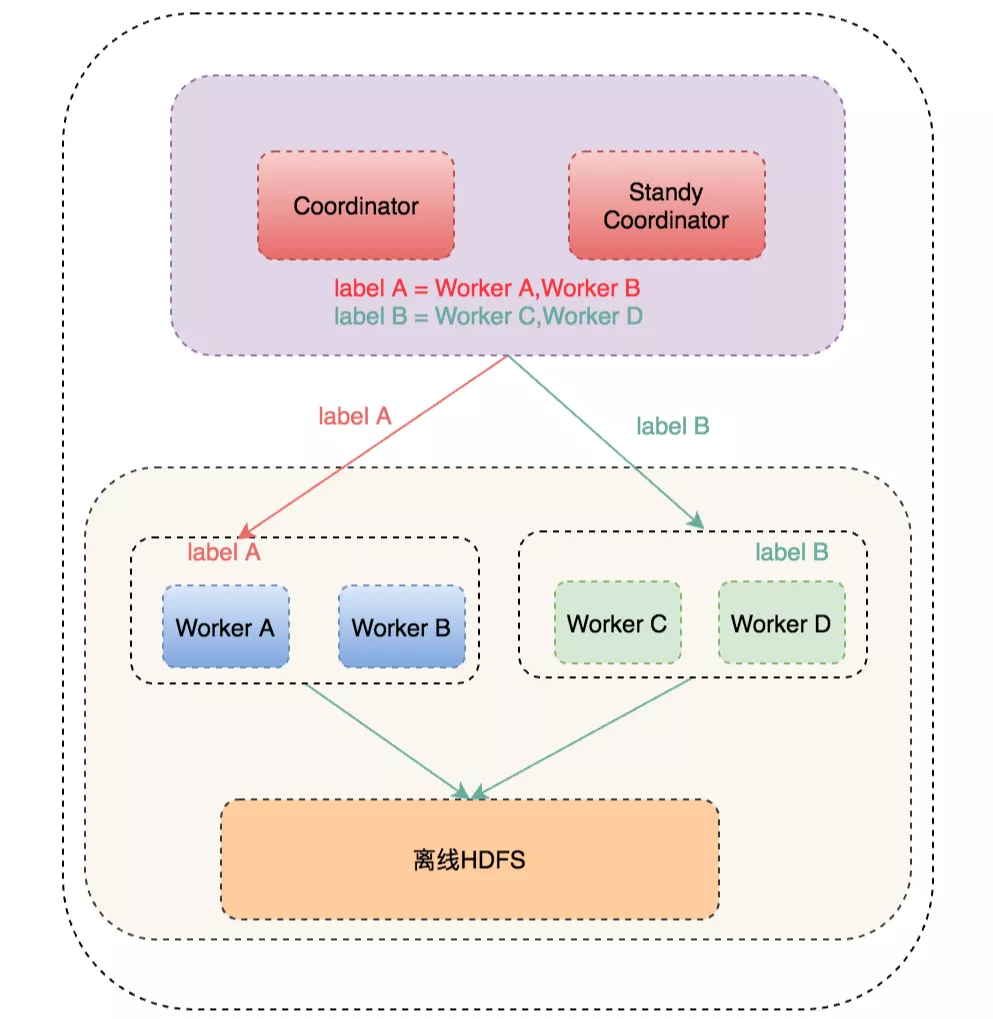
- Hive SQL 兼容
- 物理资源隔离
- 直连Druid 的 Connector
- 多租户等
Presto 在使用过程中会遇到很多稳定性问题,比如 Coordinator OOM,Worker Full GC 等。
滴滴给我们总结了 Coordinator 常见的问题和解决方法:
- 使用HDFS FileSystem Cache导致内存泄漏,解决方法禁止FileSystem Cache,后续Presto自己维护了FileSystem Cache
- Jetty导致堆外内存泄漏,原因是Gzip导致了堆外内存泄漏,升级Jetty版本解决
- Splits太多,无可用端口,TIME_WAIT太高,修改TCP参数解决
- Presto内核Bug,查询失败的SQL太多,导致Coordinator内存泄漏,社区已修复
而 Presto Worker 主要用于计算,性能瓶颈点主要是内存和 CPU。内存方面通过三种方法来保障和查找问题:
- 通过Resource Group控制业务并发,防止严重超卖
- 通过JVM调优,解决一些常见内存问题,如Young GC Exhausted
- 善用MAT工具,发现内存瓶颈
Presto 在有赞的应用
有赞在Presto上主要用来进行以下业务支持:
- 数据平台(DP)的临时查询: 有赞的大数据团队使用临时查询进行探索性的数据分析的统一入口,同时也提供了脱敏,审计等功能。
- BI 报表引擎:为商家提供了各类分析型的报表。
- 元数据数据质量校验等:元数据系统会使用 Presto 进行数据质量校验。
- 数据产品:比如 CRM 数据分析,人群画像等会使用 Presto 进行计算。
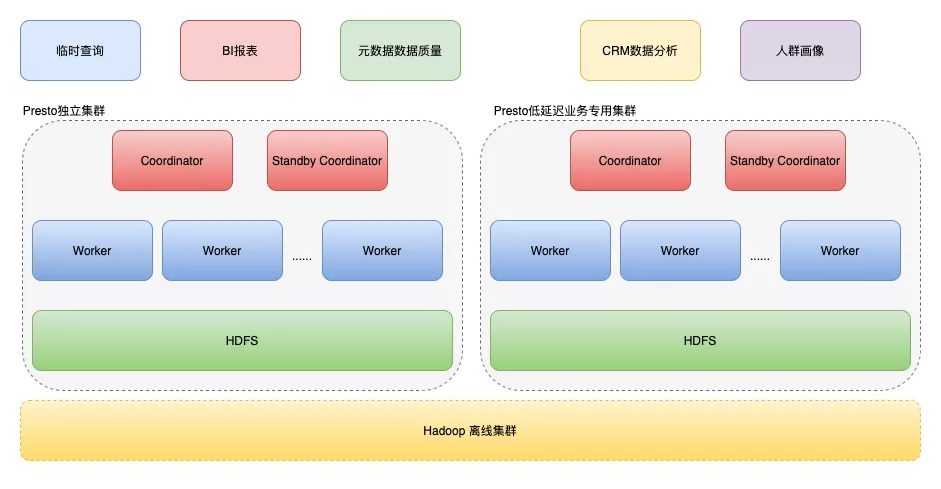
当然,有赞在使用Presto的过程中也经历了漫长的迭代:
- 第一阶段: Presto 和 Hadoop 混合部署
- 第二阶段: Presto 集群完全独立阶段
- 第三阶段: 低延时业务专用 Presto 集群阶段
在第二阶段的资源隔离主要还是靠 Resource Group,但是这种隔离方式相对比较弱,不能提供细粒度的隔离,任务之间还是会互相影响。此外,不同业务的 sql 类型,查询数据量,查询时间,可容忍的 SLA,可提供的最优配置都是不一样的。有些业务方需要一个特别低的响应时间保证,于是有赞给这类业务部署了专门的集群去处理。
部署在这个集群上的业务要求低延时,通常是 3 秒内,甚至有些能够达到 1 秒内,而且会有一定量的并发。不过这类业务通常数据量不是非常大,而且通常都是大宽表,也就不需要再去 Join 别的数据,Group By 形成的 Group 基数和产生的聚合数据量不是特别大,查询时间主要消耗在数据扫描读取时间上。同样也提供了资源完全独立,具有本地 HDFS 的专用 Presto 集群给这类业务方去使用。此外,会为这种业务提供深度的性能测试,调整相应的配置,比如将 Task Concurrency 改成 1,在并发量高的测试场景中,反而由于减少了线程间切换,性能会更好。
最后,有赞在使用Presto的过程中发生的主要问题包括:
- HDFS 小文件问题
HDFS 小文件问题在大数据领域是个常见的问题。数仓 Hive 表有些表的文件有几千个,查询特别慢。Presto 下面这两个参数限制了 Presto 每个节点每个 Task 可执行的最大 Split 数目:
node-scheduler.max-splits-per-node=100
node-scheduler.max-pending-splits-per-task=10
- 多个列 Distinct 的问题
简单的说,正常的优化器应该使用 grouping sets 去将多个 group by 整合到一起来提升性能:
SELECT a1, a2,..., an, F1(b1), F2(b2), F3(b3), ...., Fm(bm), F1(distinct c1), ...., Fm(distinct cm) FROM Table GROUP BY a1, a2, ..., an
转换为
SELECT a1, a2,..., an, arbitrary(if(group = 0, f1)),...., arbitrary(if(group = 0, fm)), F(if(group = 1, c1)), ...., F(if(group = m, cm)) FROM
SELECT a1, a2,..., an, F1(b1) as f1, F2(b2) as f2,...., Fm(bm) as fm, c1,..., cm group FROM
SELECT a1, a2,..., an, b1, b2, ... ,bn, c1,..., cm FROM Table GROUP BY GROUPING SETS ((a1, a2,..., an, b1, b2, ... ,bn), (a1, a2,..., an, c1), ..., ((a1, a2,..., an, cm)))
GROUP BY a1, a2,..., an, c1,..., cm group
GROUP BY a1, a2,..., an
但是很遗憾,Presto并没有实现这样的功能。以上就是有赞在使用Presto的一些经验。
总结
小编在学习Presto的过程中和其他的OLAP一样,也是通过漫长的文档搜索,官网摸索主键精进的,事实上在任何一门新技术的使用过程中大家都会遇到各种各样的问题,如果利用现在有的资料解决问题就是考验我们的时候了。
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章