一些准备
在开始这个话题之前,我们有必要简单回顾一下 浏览器(webkit)的网页渲染过程(如果想要详细了解这个过程,可以戳我几年前写的一篇文章。):
我们知道,浏览器在渲染过程中,如遇到节点需要依赖其他资源(比如:图片、CSS、JavaScript、video等),浏览器会通过网络去加载它们。这其中大部分的资源是异步加载的,不会阻塞渲染,除了 JavaScript(未被标记为异步的方式)。
网页的加载和渲染依赖网络与资源加载,网页本身是一种资源,它所依赖的 js、css、图片、视频等也是资源。而资源的加载涉及网络和资源的缓存等机制,而且它们充斥着整个渲染过程。
一、资源
HTML 中支持的资源主要包括以下类型:
- HTML:HTML 页面,包括各种各样的 HTML 元素
- JavaScript:JavaScript 代码,可以内嵌在 HTML 文件中,也能以单独的文件存在
- CSS 样式表:CSS 样式资源,可内嵌在 HTML 文件中,也可以单独的单独文件形式存在
- CSS Shader
- 图片:各种编码格式的图片资源
- SVG:用于绘制 SVG 的 2D 矢量图形表示
- 视频、音频和字幕:多媒体资源和支持音视频的字幕文件(TextTrack)
- 字体文件:CSS3 引入的自定义字体文件
- XSL 样式表:使用 XSLT 语言编写的 XSLT 代码文件
在 webkit 内部,会使用不同的类去表示它们,其对应关系:
| 资源类型 | 内部表示类 |
| HTML | CachedRawResource |
| JavaScript | CachedScript |
| CSS 样式表 | CachedCSSStyleSheet |
| CSS Shader | CachedShader |
| 图片 | CachedImage |
| SVG | CachedSVGDocument |
| 字幕 | CachedTextTrack |
| 字体文件 | CachedFont |
| XSL 样式表 | CachedXSLStyleSheet |
以上内部表示类均继承自 CachedResource 类。 聪明的你一定发现了, 这些类名都是以 “Cached” 开头,这其实是考虑到效率问题二引入的缓存机制。所有对资源的请求都会先获取缓存中的信息,以决定是否向服务器发起资源请求。
二、资源缓存
资源的缓存机制是提高资源使用效率的有效方法。在 webkit 内部,它的基本思想是建立一个资源的缓存池(内存缓存),当需要请求资源时,会先从资源池中查找是否存在响应的资源。如果存在,则直接使用缓存池中的资源。如果不存在,则发送真正的请求加载资源,收到响应的资源后,webkit 会将其设置到上面提的到资源类中去。
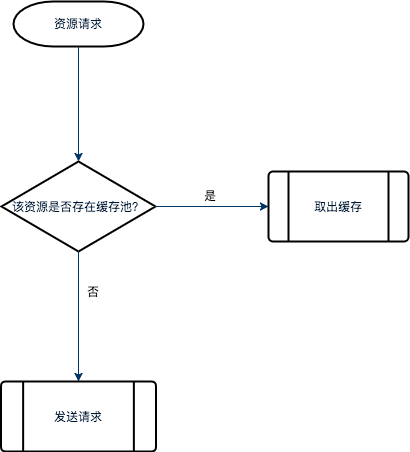
这些资源,在 webkit 内部是以 URL 作为 key 去查找的。因为 URL 是标记资源的唯一性的特征。
三、资源加载器
webkit 总共有 3 种资源加载器:
- 针对每种资源类型的特定加载器,该类资源加载器只加载某一种资源。其内部表示有:ImageLoader、FontLoader 等
- 资源缓存机制的资源加载器,特定资源加载器都共享它来插入和查找缓存资源。其内部表示为:CachedResourceLoader
- 通用资源加载器,当浏览器需要从文件系统或网络加载资源时,会使用该类加载器,但它只负责获取资源的数据,正因为如此,它也被所有的特定资源加载器所共享。其内部表示为:ResourceLoader
以 ImageLoader 这个特定资源加载器为例,大致可用下图描述:
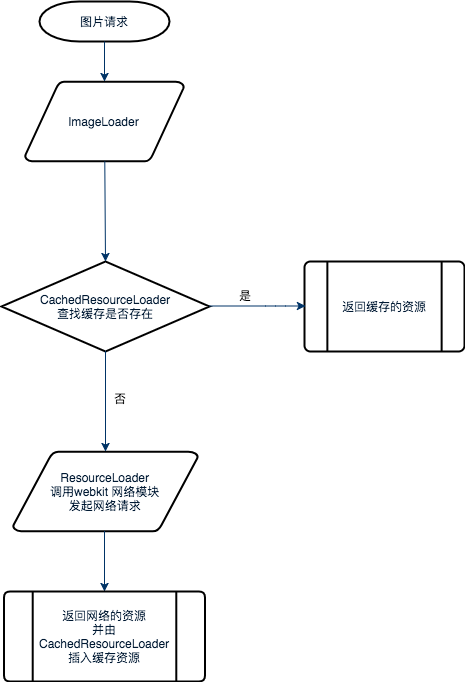
结合 chrome 浏览器调试工具,以访问百度首页为例,来观察百度 logo 的请求情况。为防止之前的缓存,采用 “清除缓存并硬性重新加载” 方式访问。表现如下:

再正常不过的 200, 没有 from * cache 标识意味着来源于网络。新开 tab, 再次访问百度首页:

发现在 size 列(倒数第二列)多了 “(from disk cache)” 字样。在此基础上(不关闭 tab),正常刷新该页面:

聪明的你一定发现 了原来 size 列的 “from disk cache” 变为了 “from memory cache”。顾名思义,两张图片的加载方式由从 磁盘缓存读取 变为了 从内存缓存读取。摘一段官网上的文档(文档地址):

简单翻译:Chrome 使用两种缓存:磁盘缓存和高速的内存缓存。内存缓存(memory cache)依附于渲染进程,我们可以大致认为一个渲染进程就等于一个 tab。
因此,“from memory cache” 只有在正常刷新的情况下,才会命中。这也解释了前面示例中新打开的 tab 访问百度首页,得到的是 “from disk cache”。
四、过程
经过前面的介绍,我们建立起了对 资源、资源缓存、资源加载器 的认知。接下来详细聊聊资源的加载过程。还是以图片加载为例:
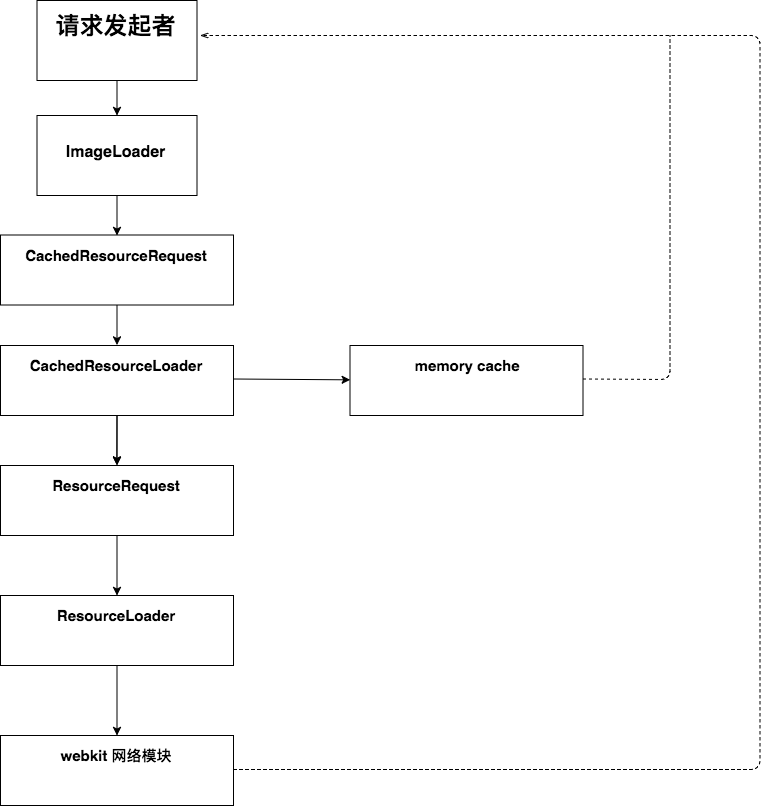
我们都知道,在网页加载时,如遇到 script 标签(未声明异步),会阻塞渲染。在这种情况下,webkit 会启动另外一个去遍历后面的 HTML 网页,收集需要的资源的 URL,然后发送请求,以此来避免阻塞。
回到资源缓存的话题,前面提到,在 webkit 内部是存在一个 “缓存池” 。为了保证在有限空间的缓存池内能够持续的插入新的缓存,它使用 LRU 算法来管理缓存。