20191230更新:
根据github上一位大神的作品,使用PyTorch框架,采用 Encoder-Decoder + Attention 方法重新完成image caption。当采用大小为3的Beam Search方式进行推理时,BLEU-4效果可以达到31%以上。在Flicker8K中随机抽几张图片试试效果,以下分别为原图和预测图。






可以看到语法和语义效果都很不错,直观感受比上次好太多。先占个坑,等有时间再把过程详细整理一下。
以下是2019年8月份记录
小白一个,刚刚费了老大的劲完成一个练手项目——image caption,虽然跑通训练,但是结果却惨不忍睹。于是贴上大神的作品,留待日后慢慢消化。顺便记录下自己踩坑的一些问题。
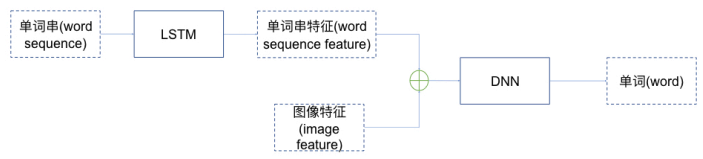
本次项目采用的模型结构如下。一路输入信息是利用VGG16提取的图像特征,另一路输入信息是利用LSTM提取的单词串特征,输出是预测的下一个单词。即模型的功能是,在给定图像特征和caption前面若干个单词的情况下,能预测出caption的下一个单词;所以循环若干次后即可得到一句完整的caption。采用的数据集是Flicker8K。
目前效果不怎么好,虽然BLEU4结果为17%,能完整输出一句话,但大部分只能识别出狗、草地等这种特别明显的特征,出现不少张冠李戴的描述,甚至于有些句子一直重复这些特征直到被截断,直观感受很不如意。暂认为可以从这几个方面进行改进:试试其他模型结构(比如Seq2Seq等),增加注意力机制,采用更大的数据集,网络调参。
问题目录
交叉验证
Bleu评价
迭代生成器问题(yield/next/send/generator)
Embedding层
模型保存与载入
LSTM层
keras中现成的模型及应用
模型的抽取、冻结、微调
文本预处理
图像预处理及归一化
交叉验证问题
提到交叉验证并非就特指k折交叉验证。交叉验证包括3种:简单交叉验证、k折交叉验证、留一交叉验证。
Bleu评价问题
生成器问题
yield、next、send:
- 有yield语句的函数,返回一个生成器对象;
- 调用next(g)或g.send()时才会正式执行该函数;
- 执行到yield语句时返回一个值,函数暂停,下一次调用时会接着这个断点继续执行;
- 项目中据此改写了图像生成器generator,使其每次返回多张图像信息,加快训练速度(每个epoch由700s缩减至220s)。
模型保存与载入问题
模型保存:
- 方法一:结构(存为json文件)+权重
model_json = model.to_json()
with open("model_architecture.json", "w") as f_obj:
f_obj.write(model_json)
model.save_weights("model_weights.h5")
- 方法二:直接保存模型
model.save('model.h5')
模型载入:
- 方法一:
model = keras.models.model_from_json(open('model_architecture.json').read())
model.load_weights('model_weight_epoch_1.h5')
- 方法二:
model = keras.models.load_model('CIFAR10_model_epoch_1.h5')
其他保存文件:
- np文件
np.save('bottleneck_features.npy', x_train_Dense) # 将提取出的特征保存在.npy文件中
train_data = np.load('bottleneck_features.npy')
- pickle库(参考)
pickle.dump(svm_classifier, open('svm_model_iris.pkl', 'wb')) #写入文件,需要二进制操作
model = pickle.load(open('svm_model_iris.pkl', 'rb'))
#下面还未见过应用
pickle.dumps(obj) #不需要写入文件中,直接返回一个序列化的bytes对象
pickle.loads(bytes_object) #直接从bytes对象中读取序列化的信息
Embedding问题
参考
main_input = Input(shape=(100,), dtype='int32', name='main_input')
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
- 任何layer均可以加name参数;
- Embedding层只能作为第一层;
- Input层到Embedding层,内部相当于已经进行onehot转换了,仅需要提供字典大小10000即可;
LSTM问题
LSTM重要参数:keras.layers.LSTM(units, activation='tanh',return_sequences=False, return_state=False),其中units为(a^{<t>})和(C^{<t>})的神经元个数。
LSTM中两个参数(return_sequences, return_state)的理解:
- 两者均默认为false,LSTM对象默认返回一个值,开启return_state后另外返回最后一个cell的隐态(a^{<t>})和(C^{<t>});
- keras中RNN和LSTM等模块没有参数V,要获得(hat y^{<t>}),则需要再接一个Dense层(才是ng课中真正的参数V)转化一下;
- 理解1
- 理解2
LSTM中参数activation和recurrent_activation,暂时理解成前者为求( ilde C)和(a)的激活函数,后者为求三大门的激活函数。(待验证。)
keras中现成的模型和应用
keras中自带了一些经典模型,比如VGG、ResNet、Inception等;并提供了这些模型的常见应用场景,比如利用ResNet50分类识别,利用VGG16提取图像特征,抽取模型中间层的输出来提取特征等等。(详见文档中Preprocessing模块的Applications。)
模型抽取、冻结、微调
模型抽取:(模型抽取参考)
- 获取层对象,以便获取其参数
- model.get_layer(name=None,index=None),或者model.layers[index]
- 获取模型输入
- model.input
- 例如:model = Model(inputs=model.input,outputs=model.get_layer(layer_name).output)
模型冻结:(模型冻结参考)
- 通过设置layer对象参数layer.trainable=False,或者模型参数model.trainable=False来控制;(注意layer和model这一参数冲突时默认顺序)
- 通过model.save()和load_model()方法载入的模型冻结时有问题,故推荐使用结构+权重分开的方式保存模型。(model.to_json() + model.save_weights())
模型fine-tune:模型微调参考【待消化】
文本预处理问题
text_to_word_sequence如何添加自定义过滤词?比如加's
- 目前解决:采用正则表达式先换掉's,再统一过滤掉。
三种常用函数:
- keras.preprocessing.text.text_to_word_sequence
- 将一句话打散成单词;输入是字符串,输出是单词列表;
- 参数:filter可以滤掉不必要的标点符号;lower默认转小写;split默认以空格划分;
- keras.preprocessing.text.Tokenizer
- 单词与编码的互换工具;
- 常用方法(注意输入输出格式):
- tokenizer.fit_on_texts(["今天 北京 下 雨 了", "我 今天 加班"])
- tokenizer.texts_to_sequences(["下 雨 我 加班", "北京 下雨"])
- keras.preprocessing.sequence.pad_sequences
- 填充序列至固定长度
- pad_sequences([[1,2,3],[4,5,6]],maxlen=10,padding='pre')
- 填充序列至固定长度
图像预处理及归一化问题
2.项目中利用VGG16提取图像特征前对图像预处理,为啥要把RGB转为BGR?这个VGG16训练时前处理是用BGR?
20191011注:keras.applications.vgg16.preprocess_input中根据不同的模式进行了通道互换(将RGB转为BGR)和通道零均值化(每个通道减去各自均值),源代码见D:Anaconda3Libsite-packageskeras_applicationsimagenet_utils.py。(至于为啥要由RGB转为BGR,推测可能是VGG16模型训练时候用了OpenCV,因为只有OpenCV用的BGR格式)