上一节中,我们采用了一个自定义的网络结构,从头开始训练猫狗大战分类器,最终在使用图像增强的方式下得到了82%的验证准确率。但是,想要将深度学习应用于小型图像数据集,通常不会贸然采用复杂网络并且从头开始训练(training from scratch),因为训练代价高,且很难避免过拟合问题。相对的,通常会采用一种更高效的方法——使用预训练网络。
预训练网络的使用通常有两种方式,一种是利用预训练网络简单提取图像的特征,之后可能会利用这些特征进行其他操作(比如和文本信息结合以用于image caption,或者简单的进行分类);另一种是对预训练的网络进行裁剪和微调,以适应自己的任务。
第一种方式训练代价极低,因为它就是简单提取个特征,不涉及训练;缺点是保存提取出来的特征需要占用一定空间,且无法使用图像增强(而图像增强对于防止小型数据集的过拟合非常重要)。第二种方式可以使用图像增强,但训练代价也会大幅增加。(当然相对于从头训练来说,使用预训练网络的训练代价肯定要低得多。)
这一节中我们以VGG16提取图像特征为例,展示第一种使用方式。该案例接着上一个例子,使用同样的数据集,利用keras中自带的VGG16模型提取图像特征,然后以这些图像特征为输入,训练一个小型分类器。
import numpy as np
from keras.applications.vgg16 import VGG16
#实例化一个VGG16卷积基
#输入维度根据需要自行指定,这里仍然采用上一个例子的维度,卷积基的输出是(None,4,4,512)
conv_base = VGG16(include_top=False, input_shape=(150,150,3))
#conv_base.summary()
###############单纯用VGG16卷积基直接提取特征,不使用图像增强####################
import os
from keras.preprocessing.image import ImageDataGenerator
#定义提取图像特征的函数
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
#输入:文件路径,样本个数
#返回:指定个数的样本特征,以及对应的标签
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator: #分别为(20,150,150,3) (20,)
features_batch = conv_base.predict(inputs_batch) #(20,4,4,512)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count: #读取了指定样本个数后即退出
break
return features, labels
#分别提取训练集、验证集、测试集的图像特征
train_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small rain'
validation_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-smallvalidation'
test_dir = r'D:KaggleDatasetsMyDatasetsdogs-vs-cats-small est'
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
#将各自的图像特征展平,作为后续Dense层的输入
assert train_features.shape == (2000, 4, 4, 512)
assert validation_features.shape == (1000, 4, 4, 512)
assert test_features.shape == (1000, 4, 4, 512)
train_features = train_features.reshape(2000, 4*4*512)
validation_features = validation_features.reshape(1000, 4*4*512)
test_features = test_features.reshape(1000, 4*4*512)
###################定义并训练一个小型分类器#########################
from keras.models import Model
from keras.layers import Input, Dense, Dropout
input = Input(shape=(4*4*512,))
X = Dense(256, activation='relu')(input)
X = Dropout(0.5)(X)
X = Dense(1, activation='sigmoid')(X)
model = Model(inputs=input, outputs=X)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
H = model.fit(train_features, train_labels,
validation_data=(validation_features, validation_labels),
epochs=30, batch_size=64, verbose=1)
#######################训练结果可视化############################
import matplotlib.pyplot as plt
acc = H.history['acc']
val_acc = H.history['val_acc']
loss = H.history['loss']
val_loss = H.history['val_loss']
epoch = range(1, len(loss) + 1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
fig.subplots_adjust(wspace=0.2)
ax[0].plot(epoch, loss, label='Train loss') #注意不要写成labels
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epoch')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epoch')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
plt.show()
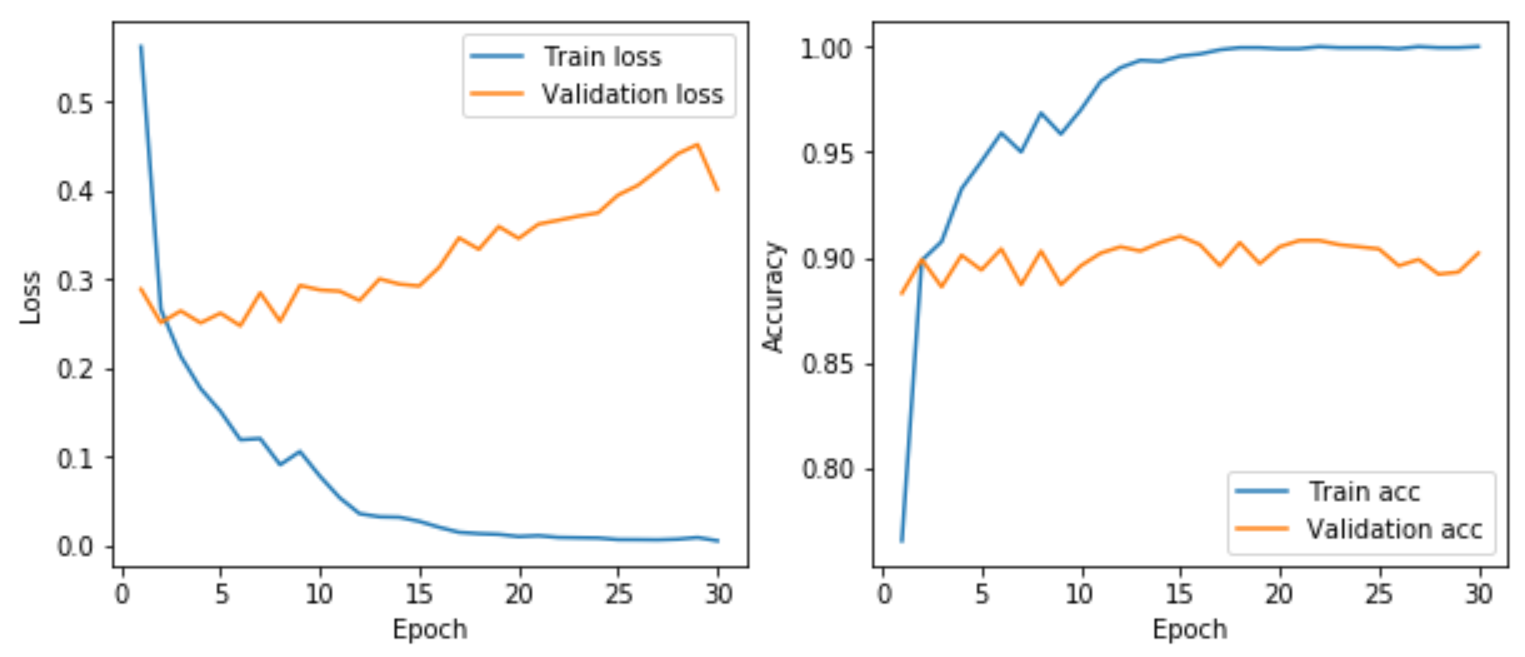
训练结果如下所示。可以看出,相对于上一个从头开始训练的猫狗分类任务,很轻松的就把验证集准确率由82%提高到90%左右,更重要的是,现在还没有使用重量级武器——图像增强。下一节,我们会使用第二种更常用更高效的方式——模型微调。