自然语言处理中的负样本挖掘 (分类与排序任务中如何选择负样本)
1 简介
首先, 介绍下自然与处理中的分类任务和排序任务的基本定义和常见做法, 然后介绍负样本在这两个任务中的意义.
1.1 分类任务
输入为一段文本, 输出为这段文本的分类, 是自然语言处理最为常见,应用最为广泛的任务. 意图识别, 语义蕴含和情感分析都属于该类任务.
深度学习没有大火之前, 主要做法是手工特征+XGBoost(也可以是逻辑斯蒂), 效果的好坏主要看工程师对业务理解的程度和手工特征的质量.
有了深度学习后, 多是将文本映射为字词向量, 然后通过CNN或LSTM做语义理解, 最后经过全连接层获取分类结果.
BERT问世后, 分类变得更为无脑, 拿到CLS后接全连接层就行了. 当然这是基本做法, 实际使用必须根据业务需求对算法和训练方式做相应修改.

1.2 排序任务
输入为一组样本, 输出每个样本的排名. 搜索引擎就主要使用了这类技术. 排序任务主要用到的技术是Learn To Rank(LTR), 随着深度学习在图像领域的光速落地, 出现了各种类似的研究方向, 比如 Metric Learning, Contrastive Learning, Representation Learning等. 其实这些研究方向本质都是比较类似的, 即让模型学会度量样本之间的距离. 大名鼎鼎的Triplet Loss本质上就是LTR中的Pair-Wise.
此类任务做法也是五花八门, 各种奇淫巧计, 有兴趣的朋友可以专门去看资料. 我只说一下我在LTR中的若干经验:
- 别把排序任务当分类, 这两个在本质上是不一样的
- 排序任务不管怎么折腾, 最后训练的还是一个打分模型, 而分值只需用来比较大小, 不需要有实际意义(这个还要看具体使用的算法). 所以本人比较喜爱Triplet Loss, 在我看来它直接表现了排序任务的本质.
- 两个样本先表征再计算分值, 速度快效果差; 两个样本直接送入模型算分值,效果好, 速度慢.

1.3 负样本的重要性
在上述两个任务中, 都不可避免的使用到负样本. 比如分类任务中的短文本相似度匹配, 语义不相关的文本对就是负样本, 排序任务中, 排名靠后的样本对就可以看作是负样本. 正负样本又有如下两个类别:
Easy Example (简单样本): 即模型非常容易做出正确的判断.
Hard Example (困难样本): 即模型难以做出正确的判断, 训练时常会给模型带来较大损失.
相较于简单样本, 困难样本更有价值, 它有助于模型的快速学习到边界, 也加快了模型收敛速度.
在实际情况中, 正样本基本上是被确定好的, 也不太好再去扩充和修改. 但是负样本有非常大的选择空间, 比如在搜索任务中, 用户点击的Document理解为正样本, 那么该页面的其余文档就全是负样本了. 训练模型时, 显然不能全部采用这些负样本, 因此Hard Negative Example Mining (选取困难负样本) 就变得非常重要!
2 负样本选择方法
2.1 基于统计度量的负样本选择方法
计算候选负样本的一些统计度量值并以此为标准选取负样本. 比如在短文本匹配任务中, 选取和目标样本集合相似度值较高的样本作为负例, 这种类型的负例可以让模型尽可能学习文本所表示的语义信息, 而不是简单学习字面意思. 试想在一个语义匹配任务中, 所有负样本都是随机生成的, 毫无章法的汉字组合, 那么模型定能快速收敛, 然而在实际生产中毫无用处.
在搜索任务中, 可以使用TF-IDF, BM25等方法检索出top-k作为负例, 注意要保证训练数据和测试数据分布一致, 如果你的模型在整个搜索框架中需要为全量文档打分排序, 那么除了top-k作为负例, 还需随机采样一些作为负例, 毕竟见多才能识广.
2.2 基于模型的负样本选择方法
2.1小节的方法太过朴素, 该方法选出的负样本未必就是最能主导模型梯度更新方向和大小的样本. 因此一个简单的做法就是用训练好的模型预测所有的负样本, 找出预测错的或者产生较大loss的样本作为优质负样本, 然后再去训练模型, 不断迭代优化模型. 整体流程如下图:
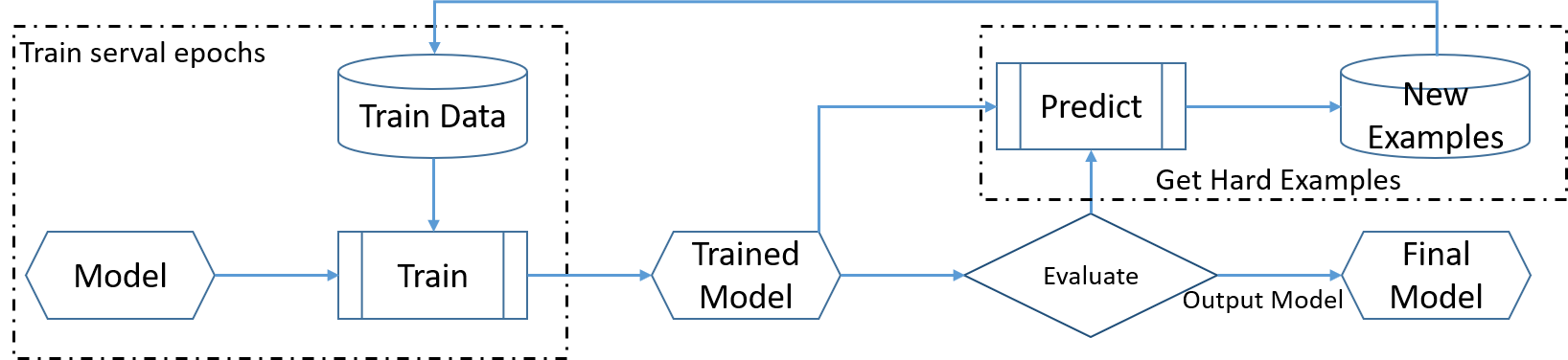
该方法逻辑上没有问题, 使用效果也不错, 但是最大的问题时时间消耗太过严重, 每训练若干轮就要在所有负样本上预测一次找到最有价值的负样本, 这对于深度学习而言太耗时了. 所以本人有两个解决方案, 一是不要用模型预测所有负样本, 预测一部分负样本就行, 这算是一个折中方案. 第二个方法是与此有些类似, 名字叫做OHEM(Online Hard Example Mining, 在线困难样本挖掘), 在每次梯度更新前, 选取loss值较大的样本进行梯度更新. 该方法选取负样本是从一个Batch中选择的, 自然节省了时间. 该方法是为目标检测提出的, 在NLP领域能否适用还需要看实战效果.
3 基于loss的改进
除了选择优质负样本, 还可以考虑在损失函数上做改进, 让模型自动提高困难样本的权重.
3.1 Focal Loss
Focal Loss对交叉熵损失函数进行了改进。该损失函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
首先来看一下二分类上的交叉熵损失函数:
简单化简后:
这个公式相比大家非常熟悉了, 我就不再赘述.
Focal Loss对该损失函数做了简单修改, 具体公式如下:
Focal Loss的作者建议alpha取0.25, gamma取2, 其实通过和CELoss的对比就可以发现, Focal Loss主要对损失值做了进一步的缩放, 使得难以区分的样本会产生更大的损失值, 最终是模型的梯度大小和方向主要由难分样本来决定.
下图是Focal Loss的测试结果, 效果还是令人满意的.

3.2 Gradient Harmonizing Mechanism(GHM)
Focal Loss 会过度关注难分类样本, 真实数据集往往会有很多噪音, 这容易导致模型过拟合.
与Focal Loss类似, GHM同样会对损失值做一个抑制,只不过这个抑制是根据样本数量来的, 梯度小的样本数比较大,那就给他们乘上一个小系数,梯度大的样本少乘以一个大的系数。不过这个系数不是靠自己调的,而是根据样本的梯度分布来确定的. 具体公式可以参考原论文, 这里就不再贴公式了, 到目前未知还没有听说有用在NLP上的, 效果如何也要看实战了.
4 训练方式的改进
第二节和第三节都是针对优质样本的探索, 其实可以换个角度思考, 就让模型见到足够多的负例, 只要硬件足够强大, 你可以模型学习所有的负例, 颇有一种大力出奇迹的感觉. 因此可以尝试改变训练方式让模型见到更多的负样本, 此类方法很想LTR中的List-Wise.
4.1 一个Batch的样本都作为负样本
以短文本匹配任务为例, 假设输入的一个batch是 (a1,b1), (a2,b2), (a3,b3), (a4,b4), 每一对样本都是相似的, 可以把剩余其他样本都作为负样本, 比如对于a1而言b2, b3, b4都是负样本, 这样可以在没有增大batch_size大小的情况下让模型学到更多负样本. 具体损失函数既可以是二分类的交叉熵损失函数, 也可以当成多分类损失函数来优化, 即把(a1,b1), (a1,b2), (a1,b3), (a1,b4)的相似度值作为logit送入多分类损失函数, 在这个例子中, 是四分类任务, 标签是0(a1和b1的相似度值应该最大).
如果要使用该方法记得确保每个batch中其他样本可以作为负样本! 如果a1和b4也是相似, 那么训练数据就存在噪声了.
此种类型的方法在NLP领域已有使用, 效果还算可以, 有兴趣的朋友可以在自己的任务上试一试. SimBERT(一个通用句向量编码器)就是基于此类方法训练的, 美团在微软阅读理解比赛取得第一名的算法也和此类似. "没有增大batch_size大小的情况下让模型学到更多负样本", 这句话算是第四节的核心了
4.2 MOCO
MOCO方法算是一种经典的图像预训练方法, 它是自监督的, 基于表征学习, 类似于NLP里的Bert. MOCO的一大创新就是让模型一次见到海量负例(以万为单位), 那么存在的问题就是计算量会爆炸, 每一个step 都要多计算上万次, 就像是把4.1中的batch_size变成一万一样, 时间是吃不消的. 为了解决这个问题, MOCO创建了负例队列, 不会一次计算所有负例的表征, 而是缓慢更新这个队列中的一部分负例, 即先进队列的先被更新, 这样是减少了计算量, 但是在计算损失函数时使用到的大部分负例表征是过时的, 因此MOCO使用动量方法来更新模型参数, 具体过程可以看下面的伪代码:
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
logits = cat([l_pos, l_neg], dim=1)这一行代码就是把正样本的点积值和负样本的点积值在最后一维进行拼接. f_k.params = m*f_k.params+(1-m)*f_q.params该行代码是对模型参数进行动量更新. 如果没有一定的Pytorch基础还是比较难看懂的, 建议大家去读一读论文以便加深理解.
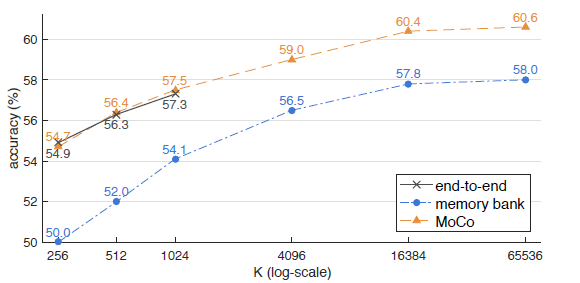
下图是MOCO的性能评估, 可以看出MOCO性能优于其他同类方法, 且负例队列数量越大效果越好. 该方法本人已经在NLP领域相关任务上做过尝试, 效果不错, 有兴趣的可以在自己任务上试一试.
5 总结
天下没有免费的午餐, 很多方法只有亲自试了才知道是否有效. 建议大家多去看测试结果, 基于真实数据分析思考算法的优化方向. 本文所讲的方法也是抛砖引玉, 希望各位大佬可以贡献更多的方法.
NLP被称作是人工智能皇冠上的明珠, 但是截至目前未知还未看到这颗明珠大放异彩. 本文介绍的方法几乎全部来源于图像领域, 想一想还是挺失望的. 学科之间思想方法都是相通的, 希望在以后能看到更多在NLP研究上的创新.
最后感谢各位阅读, 希望能帮到你们.
文章可以转载, 但请注明出处:
6 参考文献
- OHEM: Training Region-based Object Detectors with Online Hard
Example Mining - S-OHEM: Stratified Online Hard Example Mining for Object Detection
S-OHEM - A-Fast-RCNN: Hard positive generation via adversary for object
detection - Focal Loss: Focal Loss for Dense Object Detection
- GHM: Gradient Harmonized Single-stage Detector
- MOCO: Momentum Contrast for Unsupervised Visual Representation
Learning - https://zhuanlan.zhihu.com/p/60612064
- https://www.cnblogs.com/rookiechenv587/p/11973078.html