要使用自己的信息源,从行为上说有两个步骤:1、写一个xml文件(定义信息源,这一步略复杂,点击这里有一些示例)
2、把这个信息源的id写入一个或多个用户的.txt文件(启用信息源,这一步极简单)
定义信息源的意义在于:
把各种来源不同、形式不同的信息,导入到InfoPi的信息处理框架内。
这个框架很简单,即:一条信息有5+1个字段,全部为字符串类型。
5个字段是title(标题)、url(链接)、author(作者/出处)、summary(摘要)、pub_date(发布时间)。
1个字段是suid(信息源范围内的唯一标识),它像身份证号,作用是确保一条信息不会被重复记录,请确保它在信息源范围内的唯一性。
详见《运行机制》一文的数据库设计部分。
可能有的网友看后觉得很麻烦。InfoPi是很严谨、灵活的,在保证严谨、灵活的前提下,操作已经很简化了。
建议先了解InfoPi的运行机制,主要是数据库设计那部分,了解机制后所谓的麻烦就是枝叶。
也欢迎提意见,指出哪些地方写的不清楚、需要补充。
目录:
- 信息源简介
- rss_atom的使用
- html_re的使用
- callback回调代码的使用
- 测试自己定制的信息源
- 自带的几个例子
- 经验 && 小技巧 (动手操作前看一下)
信息源简介
信息源,就是对信息来源的定义。InfoPi会根据信息源去获取信息,获取后会返回一个列表,列表通常包含一条或多条信息,列表也可为空。
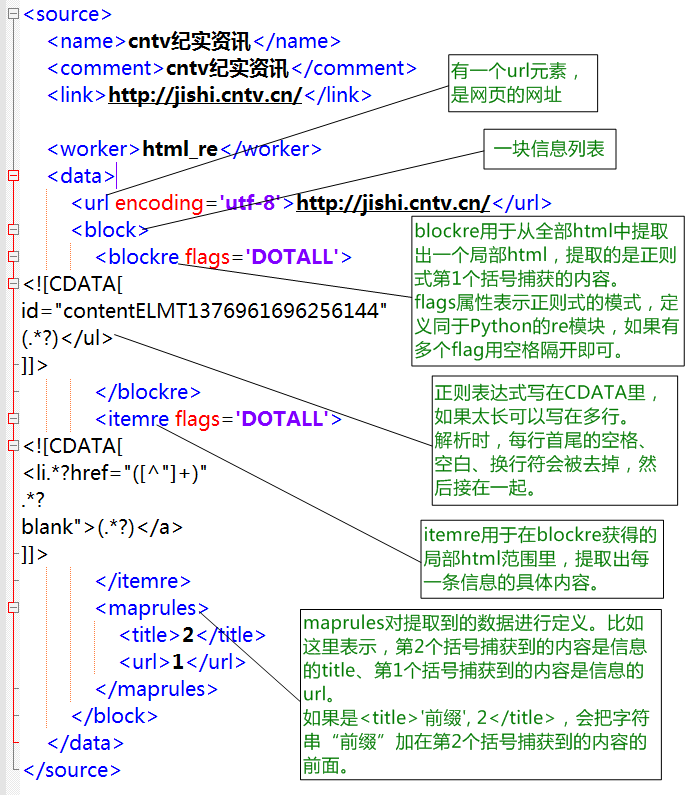
一个信息源的具体形式是一个xml文件,下图说明了该文件的总体结构。

总体而言,分为三部分:
- name、comment、link。分别是信息源的名字、备注、链接,这些内容主要是给人看的,name会作为信息的默认作者/出处。
- worker、data。worker是一个函数,用于获取特定类型的信息。data是驱动worker工作的数据。
- callback回调代码,里面可以有一小段Python程序代码,对每条信息进行后处理。如果不需要进行后处理可以没有callback。
InfoPi自带了5个worker,本文讲解前2个的用法,因为这2个比较常用:
- rss_atom。处理RSS、ATOM,常用于订阅博客。
- html_re。用正则表达式提取html(网页)里的信息。
- html_re_rev。和html_re用法完全相同,区别是最终获得一个逆顺序的列表。
- html_json。用于从html里提取json信息,详细用法见此文。
- pypi。从Python官方的pypi获得第三方模块的更新信息。
下面对前2个worker的用法进行分别讲解。
rss_atom的使用
这个worker的用法很简单,只要在data里创建一个url元素,在里面填上RSS或ATOM的网址就可以了,如图:

有些web服务器不发送RSS、ATOM文件的编码,或者发送的是错误的编码。这时给url元素加个encoding属性,在里面指明编码即可:
<url encoding='utf-8'>http://whis.cssn.cn/sjs/sjs_sjgdzgs/</url>
(如果嫌麻烦,可以安装自动检测编码的模块,见此文)
信息源的<url>标签也支持errors属性,用法和Python解码的errors参数相同:
<url errors='strict'> 这是默认值,表示对解码错误零容忍,将引发一个异常
<url errors='ignore'> 忽略解码错误
<url errors='replace'> 解码出错时用?替换
encoding属性和errors属性可以同时使用。
(errors属性仅2015.05.23以后版本才有)
rss_atom默认使用信息源的name作为每条信息的author,如果想使用feed自身提供的出处,增加一个use_feed_author空标签就可以了,如下图。这适用于聚合类的feed。

html_re的使用
html_re用正则表达式从网页里提取信息。
html_re的总体结构是这样的:

具体见此图
在maprules里,可以进行字符串拼接,用下图的author举例:
信息的author = '天涯-' + 第1个括号捕获的内容
要拼接的内容用逗号隔开,单引号内是字符串,单独的数字表示第几个括号捕获的内容。
假如第1个括号捕获的内容是煮酒论史,那么拼接后的author就是天涯-煮酒论史。

在有些网页,提取出的url链接是相对路径,并不是完整路径。
这时,可以按上图的方式拼接出完整的url,也可以用下图的方式自动拼接url。

感兴趣的信息可能分布于同一个页面的不同位置,这时使用多个block即可,程序会依次处理。
备注1:可以安装regex模块,这是一个更强大的正则表达式引擎,在处理复杂情况时更方便,参看详细介绍。
备注2:有极个别网页,在浏览器里看到的html源码和直接下载的html源码不一样,这时请以后者为提取目标。
备注3:个别网页,信息是在某个js或json文件里面,这时先用浏览器的调试器定位该文件,然后从该文件提取。
备注4:Python正则表达式的常用标识(flags属性):
| 含义 | 简写 | 全写 |
| 忽略大小写模式 | I | IGNORECASE |
| 多行模式 | M | MULTILINE |
| .号包含换行符 | S | DOTALL |
callback回调代码的使用
callback回调代码是一小段Python程序代码,InfoPi会在获取信息后调用它,用于对每条信息进行后处理。
每条信息会被作为变量info传入回调代码,可以对其任意处理。
比如,这是删掉author以“娱乐八卦”为结尾的信息:

以下是传入callback回调代码的几个变量:
| 名称 | 类型 | 用法 |
| info | 一条信息 |
info对象有如下属性(汉字为说明):title 标题、url 链接、author 作者出处、summary 摘要、pub_date 发布日期、suid 唯一标识符、temp 一个临时变量。 要想了解这些属性的涵意,请参看此文的数据库设计部分:http://www.cnblogs.com/infopi/p/3974717.html 例: info.author = '天涯-' + info.author 这是给信息的出处添加“天涯-”前缀。 |
| posi | 整数 |
表示这条信息在整个列表中的位置,第一条信息的位置为0。 例: if posi > 4: info.temp = 'del' 只保留列表的前5条信息,其余删除。 仅2015.06.14b以后版本才有 |
| funcs | 一个对象 |
包含各种便利函数,仅2017.1.16a以后版本才有 |
几个小窍门:
1、代码要写在CDATA里,缩进方式同Python。(严格缩进,且空格和TAB不能混用)
2、如果想删除某一条信息,给info变量的temp属性赋值'del'即可: info.temp = 'del' 。
3、严格来说,这是一段回调代码,而非一个回调函数,所以不要在callback里使用return语句。
4、在一个获取列表内,各条信息的callback代码共用一个变量空间,因此可以创建、使用跨单条信息的变量。
5、如果回调代码仍然无法满足对信息处理的要求,可以自己写一个worker。
测试自己定制的信息源
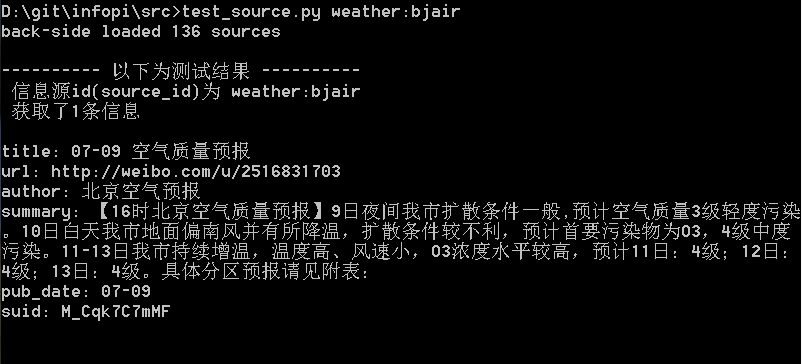
在infopi的src目录下,有个test_source.py程序,用于测试某个信息源能否正常工作。
这里测试weather:bjair,把它作为唯一参数执行就可以了:
(输入test_source.py的时候可以使用TAB自动补全,即:只要输入test然后按TAB键,会自动补全文件名。)
自带的几个例子
这里有一些共享的信息源,点击Download按钮下载即可。
自带的演示配置demo_cfg.zip里有一些例子,请看admin.txt的结尾部分:
# health:fzhh 演示了如何订阅普通博客
# jilupian:cctv9 演示了html_re如何在一个页面里解析两个以上block的内容
# bbs:tyhr 演示了信息源如何继承父信息源的内容,适用于同一个模块生成的多个页面
# 3c:rasppi 演示了如何使用callback回调代码生成更有效的suid
# bbs:tyhome 演示了如何在callback回调代码里删除特定信息
# update:flask 演示了如何使用自定义worker
经验 && 小技巧
1、可以在日常使用的电脑上安装一个InfoPi(最好和树莓派的版本一致),用test_source.py测试自定义的信息源能否正常工作。
2、看看示例配置的admin.txt文件,里面有一些使用上的讲解。
3、记不住xml文件的结构?可以复制一个示例xml文件,改改内容。
4、存放xml文件的目录名和xml的文件名会作为信息源ID的组成部分,确定后尽量不要改动,所以起名前多思量一下。为了确保跨平台使用,建议目录名、文件名全部用小字字母。详细介绍见此文的目录结构一段。
5、rss_atom和html_re会自动把提取到的字符串里的html标签去掉。
6、要修改服务器的配置,按这个顺序:下载配置zip文件 -> 解压zip -> 修改配置 -> 打包zip -> 上传zip。
7、不建议使用windows自带的记事本,推荐使用开源的文本编辑器Notepad++。