html_json用于从网页里提取json数据。
这里用新浪读书的书讯举个例子,手把手写一个html_json信息源。
打开新浪读书的首页,可以看到页面下方有最新、书讯、童书、小说等几个Tab,这里我们提取书讯的内容。
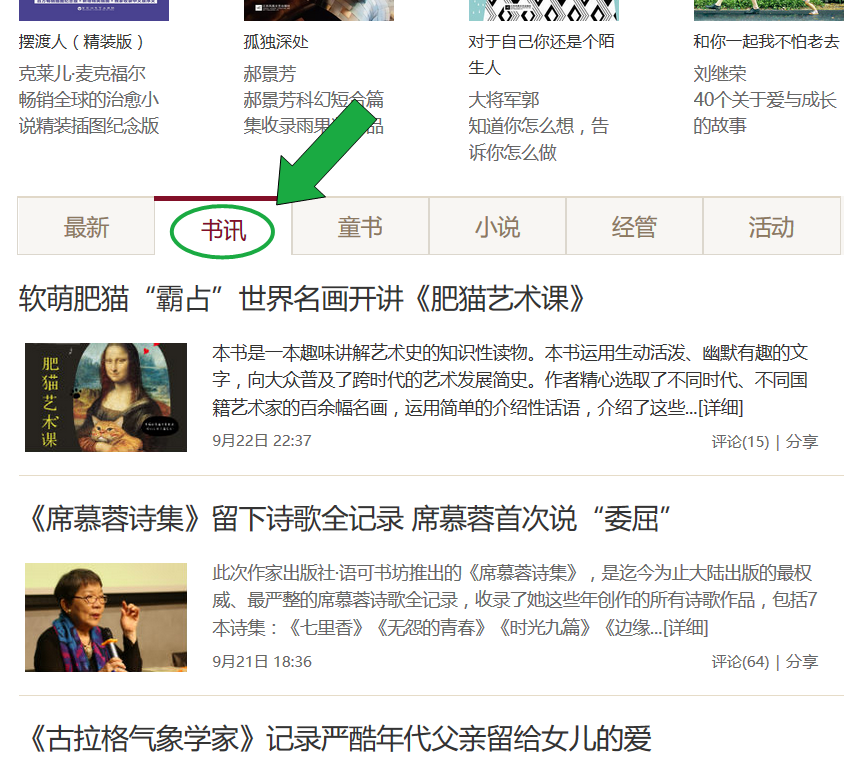
查看页面的源码,找不到书讯的内容。
这是因为网站使用了json技术:额外加载了json对象、并通过javascript把json的内容显示在页面上。
那么,怎么找到json在哪儿呢?
我用的是Firefox浏览器,按Ctrl+Shift+J调出“浏览器控制台”。别的浏览器也有类似的调试工具。
为了过滤掉无关的信息,在右上角的过滤里填上“sina”,这样没出现sina的内容会被过滤掉。

然后刷新新浪读书的首页,可以看到加载了大量文件,有图片、有.css、有.js、有.html,我们要找的json就在其中。
经过一番辨认,这6个文件的可能性很大,数量正好对应网页上的6个Tab:
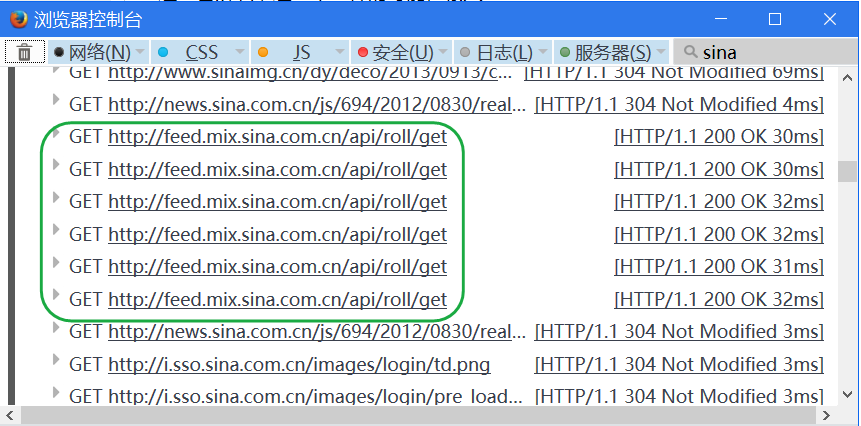
我们来进行确认。右键点击第2个,把链接复制出来,是这个链接:
http://feed.mix.sina.com.cn/api/roll/get?callback=jsonp1474707033326&pageid=8&lid=156&num=20&page=1
打开这个链接,可以看到,这是一条很简单的javascript语句,但其中嵌入了一个很大的json对象。
try{jsonp1474707033326({"result":{"status":{"code":0,"msg":"succ"},"timestamp":"Sat Sep 24 16:58:35 +0800 2016","top":[],"pdps":[],"cre":[],"total":415,"end":1472633552,"start":1474555033,"lid":156,"rtime":1474707515
...省略中间的部分...
"comment_reply":"1","comment_show":"1","comment_total":"2","praise":"0","dispraise":"0"}]}});}catch(e){};
把最前面的try{jsonp1474707033326(和最后面的);}catch(e){};去掉,剩下的中间部分就是一个json字符串了。
复制这个json字符串,把它粘贴到http://www.bejson.com/网站,对其进行格式化,可以清晰地查看它的结构,并且确认这就是我们要找的书讯的内容。
result.data是一个列表,列表的每个元素就是一条书讯的数据。

下面是result.data里的一条数据(为了版面简洁,去掉了一部分内容),用蓝色标记出我们感兴趣的内容,分别是:
title,标题
url,网址
ctime,发布时间
summary,摘要;intro,介绍。
有的数据summary为空,但intro不为空,这是网站的设计,所幸把这两个都提取出来。
{"intime": "1474557864", "categoryid": "1", "intro": "“软萌”肥猫“霸占”世界名画, 还用“傲娇”猫语解读艺术发展? 一本《肥猫艺术课》带你徜徉世界艺术画廊, 告诉你“有猫的名画,才是真迹”。", "mediaid": "0", "ctime": "1474555033", "author": "", "stitle": "《肥猫艺术课》", "images": [ { "u": "http://www.sinaimg.cn/book/2016/0922/U21P112DT20160922223234.jpg", "w": 450, "h": 476, "t": "《肥猫艺术课》 [俄]斯韦特拉娜簠靟坟娃 袁天添 北京联合出版公司" }, { "u": "http://www.sinaimg.cn/book/2016/0922/U21P112DT20160922223418.jpg", "w": 500, "h": 363, "t": "米开朗基罗,《创造肥猫亚当》" } ], "keywords": "肥猫,名画,艺术",
"title": "软萌肥猫“霸占”世界名画开讲《肥猫艺术课》",
"summary": "本书是一本趣味讲解艺术史的知识性读物。本书运用生动活泼、幽默有趣的文字,向大众普及了跨时代的艺术发展简史。作者精心选取了不同时代、不同国籍艺术家的百余幅名画,运用简单的介绍性话语,介绍了这些名画的时代背景和馆藏地点,是一本简单的“名画艺术史”讲解书。",
"productid": "0", "url": "http://book.sina.com.cn/news/b/2016-09-22/2237819373.shtml", },
已经明白了,于是写这样一个信息源(.xml文件),内用绿色注释说明几个要点:
<source> <name>新浪书讯</name> <comment>新浪图书,书讯。</comment> <link>http://book.sina.com.cn/</link> <worker>html_json</worker> <data> <url> http://feed.mix.sina.com.cn/api/roll/get?callback=jsonp1436772833418&pageid=8&lid=156&num=20</url> <!-- 要把网址里出现的&转义成& --> <re flags='DOTALL'> <!-- 用正则表达式去掉首、尾的javascript语句,提取json字符串到1号捕获组 --> <![CDATA[ ^try{w+( (.*) );}catch(e){};$ ]]> </re> <block> <block_path>'result', 'data'</block_path> <!-- block_path是抵达数据列表的路径。如果路径中有列表,可以使用不加引号的数字作为列表索引 --> <title>'title'</title> <!-- 以下分别提取各项数据 --> <url>'url'</url> <summary>'summary'</summary> <temp>'intro'</temp> <pub_date>'ctime'</pub_date> </block> </data> <callback> <!-- 后处理代码:把unix时间戳转换成时间字符串;当summary为空时使用intro作为摘要 --> <![CDATA[ info.pub_date = unixtime(info.pub_date) info.summary = info.summary or info.temp info.temp = 0 ]]> </callback> </source>
测试一下,成功:
