
发表时间:2016(AAAI2016)
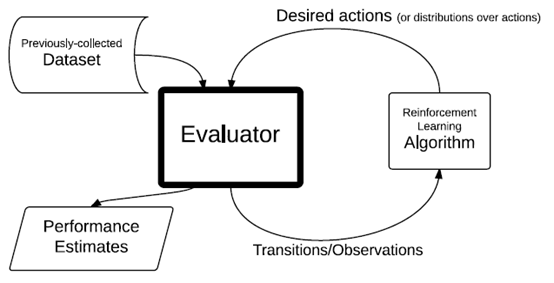
文章要点:通常大家做offline评估的时候都是去评估一个训好的fixed的策略,这篇文章就说我想在offline的setting 下去评估一个算法好不好。根据这个出发点,大致思路是先根据收集的data去弄一个evaluator出来,然后RL算法去和这个evaluator交互,交互的过程既是policy更新的过程,也是评估的过程。文章一共提出了三个算法,第一个就是直接采样动作,然后和evaluator交互并更新。第二个是用rejection sampling来修正估计,然后用接收的样本来更新policy。第三个是在episode上做rejection sampling,而不是在单个样本上。
总结:这个setting离我有点远,看不大明白在干啥,也不懂contribution在哪。
疑问:其实我是不太明白这个paper的点在哪,不清楚这个evaluation能用到哪。而且实验部分的比较是比哪个evaluation的方式更准吗?但是好像也没提在哪个RL算法上比的,只说了evaluation的比较对象是model based approach。搞不懂呀,罢了罢了。