
发表时间:2020(NeurIPS 2020)
文章要点:目前主流的offline RL的方法都是model free的,这类方法通常需要将policy限制到data覆盖的集合范围里(support),不能泛化到没见过的状态上。作者提出Model-based Offline Policy Optimization (MOPO)算法,用model based的方法来做offline RL,同时通过给reward添加惩罚项(soft reward penalty)来描述环境转移的不确定性(applying them with rewards artificially penalized by the uncertainty of the dynamics.)这种方式相当于在泛化性和风险之间做tradeoff。作者的意思是,这种方式允许算法为了更好的泛化性而承担一定风险(policy is allowed to take a few risky actions and then return to the confident area near the behavioral distribution without being terminated)。具体做法就是,先根据data去学一堆状态转移函数,这个函数是一个用神经网络表示的关于状态和reward的高斯分布
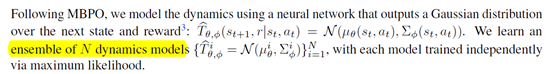
有了这个之后,就要在原始reward上添加penalty,添加方式是找这堆dynamics里面最大的协方差的范数,然后reward变成
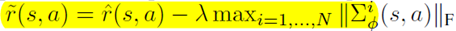
然后model和reward都有了,就直接上强化算法就好了,文章里用的是SAC。

总结:虽然中间推了几个公式,说了一下bound,但是最后落实下来其实就是在reward上加了一个uncertainty的penalty的估计,而且作者也说了this estimator lacks theoretical guarantee。就主要还是看效果吧。
疑问:reward penalty里面的F应该是矩阵的Frobenius范数吧?