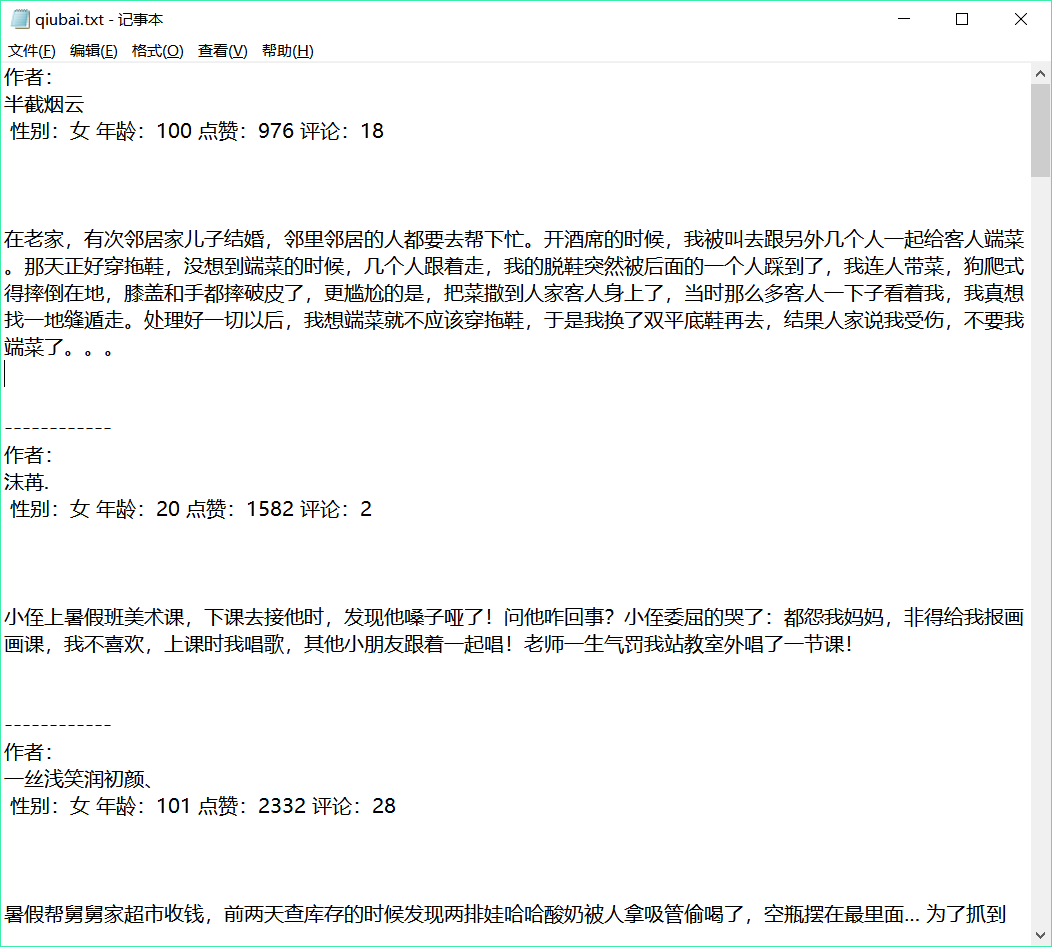
爬取糗百内容
GitHub 代码地址https://github.com/injetlee/Python/blob/master/qiubai_crawer.py
微信公众号:【智能制造社区】,欢迎关注。
本文目标
- 掌握爬虫的基本概念
- Requests 及 Beautiful Soup 两个 Python 库的基本使用
- 通过以上知识完成糗百段子抓取
爬虫基本概念
爬虫也称网页蜘蛛,主要用于抓取网页上的特定信息。这在我们需要获取一些信息时非常有用,比如我们可以批量到美图网站下载图片,批量下载段子。省去手工操作的大量时间。爬虫程序一般是通过模拟浏览器对相应URL发出请求,获取数据,并通过正则等手段匹配出页面中我们所需的数据。
在学习爬虫之前,最好到 w3school 去了解一下 HTML 标签的概念以及基本的 CSS 的概念。这会让我们更容易的理解如何获取页面中某个内容。
Requests 库基本介绍
Requests 是学习爬虫的一大利器。是一个优雅简单的 HTTP库。官网介绍如下:
Requests: HTTP for Humans
专门为人类使用的 HTTP 库。使用起来非常简单明了。
我们平时浏览网页的步骤是输入网址,打开。在 Requests 中是如下这样的,我们可以在 Python 交互式解释器中输入以下代码:
import requests
r = requests.get('https://www.qiushibaike.com/text/') # 打开网址,一般我们会设置 请求头,来更逼真的模拟浏览器,下文有介绍
r.text
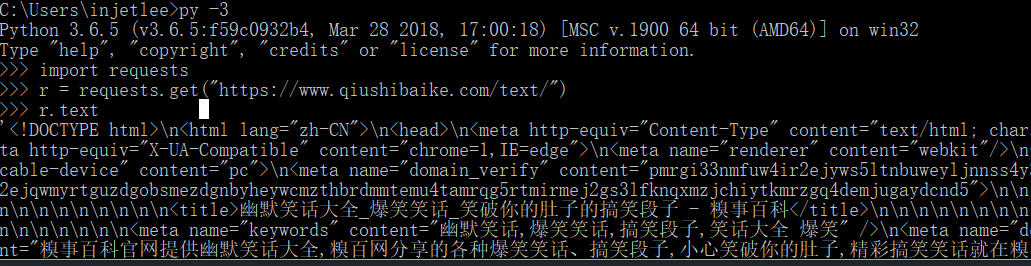
我门看到下面一堆的代码,其实就是网页的源代码(也可以在浏览器上右键查看页面源代码)。通过这几行代码我们就拿到了页面的所有信息,剩下的就是从页面中找到我们所需要的信息。
Beautiful Soup 库介绍
拿到网页信息后,我们要解析页面,通常来说我们有以下几种方式来解析页面,获取我们所需的信息。
- 正则表达式
- 适用于简单数据的匹配,如果匹配内容较复杂,正则表达式写起来会很绕,同时页面内容稍微变化,正则就会失效
- Lxml
- Lxml 是专门用来解析 XML 格式文件的库,该模块用 C 语言编写,解析速度很快,和正则表达式速度差不多,但是提供了 XPath 和 CSS 选择器等定位元素的方法
- Beautiful Soup
- 这是一个 Python 实现的解析库,相比较于前两种来说,语法会更简单明了一点,文档也比较详细。唯一的一点就是运行速度比前两种方式慢几倍,当数据量非常大时相差会更多。
本文作为入门教程,就从 Beautiful Soup 入手,来学习一下匹配页面所需元素的方法。
假如有以下 HTML 内容 example.html
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>Page Title</title>
</head>
<body>
<div class='main-page'>
<ul class='menu-list'>
<li>首页</li>
<li>新闻</li>
<li>影视</li>
</ul>
</div>
</body>
</html>
我们通过 Beautiful Soup 来解析这个 html. 首先我们pip install beautifulsoup4安装这个库,并看一下简单使用。
>>>from bs4 import BeautifulSoup
>>>soup = BeautifulSoup('example.html', 'html.parser') #加载我们的html文件
>>>soup.find('div') # 找到 div 标签
'<div class="main-page">
<ul class="menu-list">
<li>首页</li>
<li>新闻</li>
<li>影视</li>
</ul>
</div>'
>>>soup.find_all('li') # 找到所有 li 标签
'[<li>首页</li>, <li>新闻</li>, <li>影视</li>]'
>>>for i in li:
print(i.text) #获取每个 li 标签的内容
'
首页
新闻
影视
'
详细的操作可以去看一下文档,文档非常详细,例子也很多,简单明了。
糗百爬虫代码
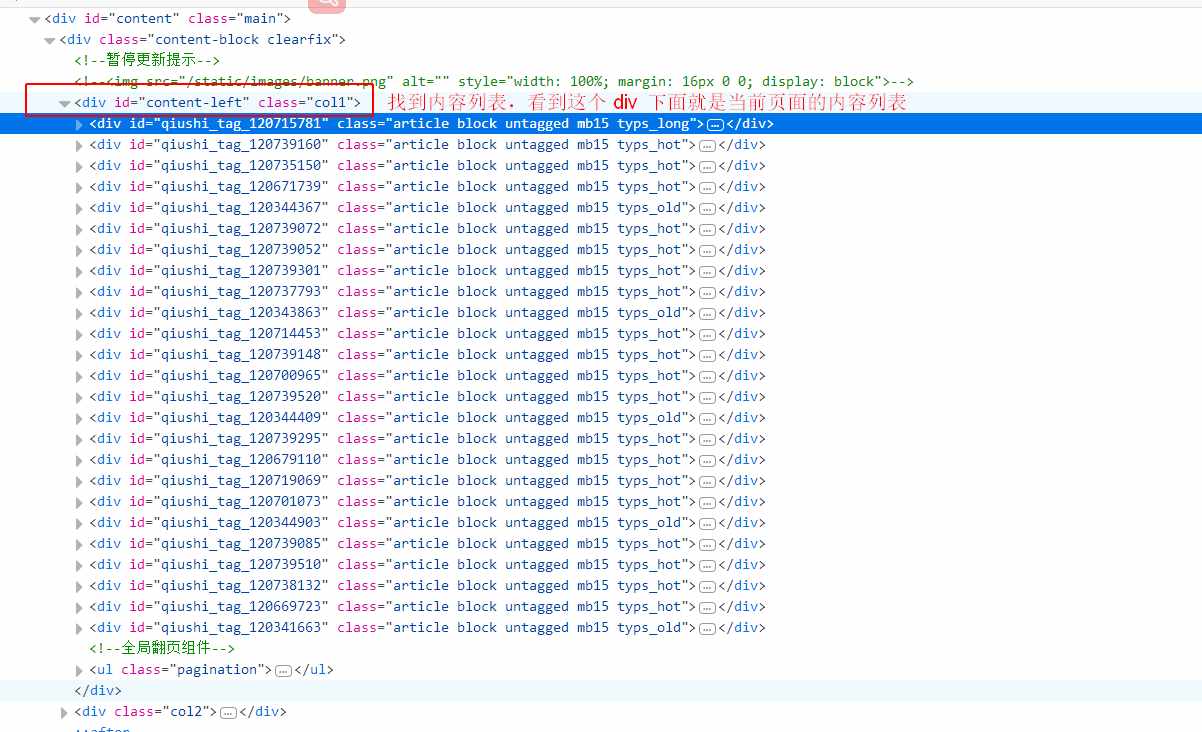
我们先爬取纯文本的内容 https://www.qiushibaike.com/text/ 爬取这个链接下的内容。我们把页面结构截图如下,我们要获取的信息,我用红色的方框进行了标注。
图一:
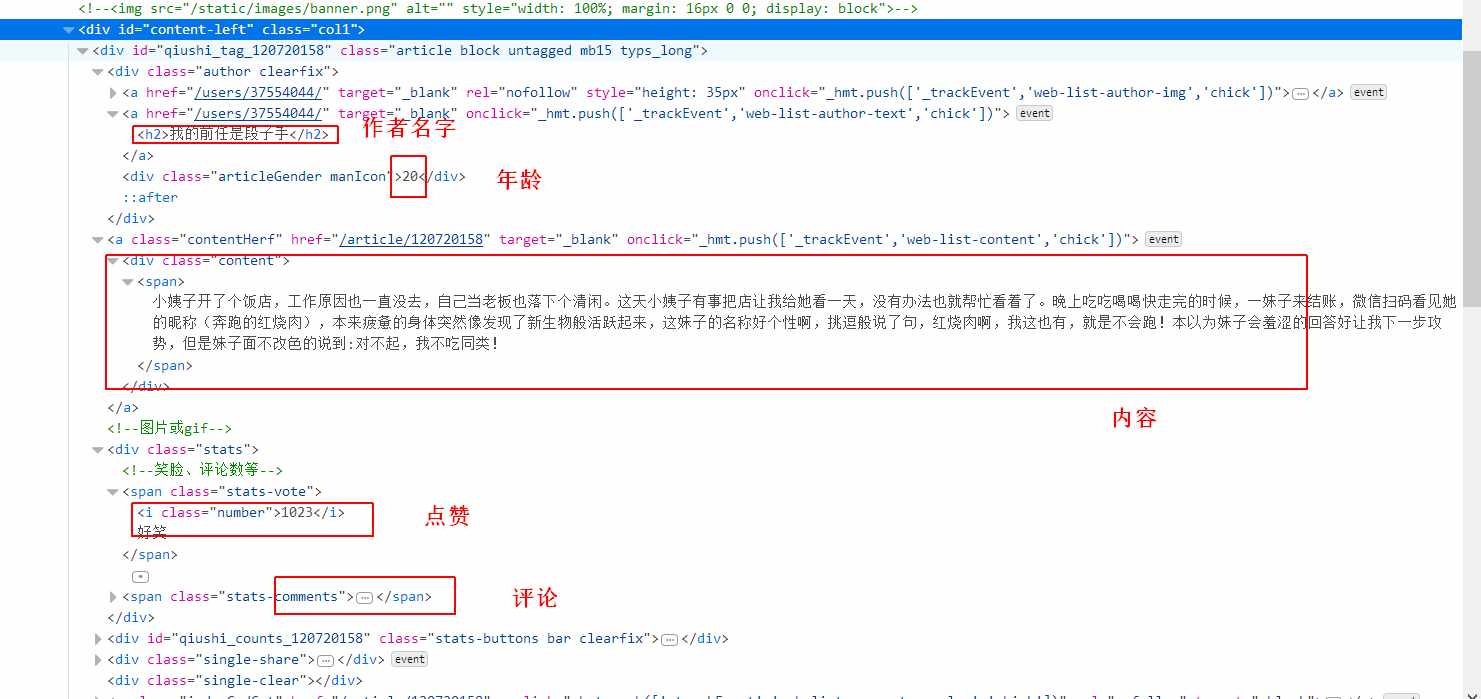
图二:
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"}
r = requests.get(url, headers=headers) # 增加headers, 模拟浏览器
return r.text
def get_content(html, page):
output = """第{}页 作者:{} 性别:{} 年龄:{} 点赞:{} 评论:{}
{}
------------
""" # 最终输出格式
soup = BeautifulSoup(html, 'html.parser')
con = soup.find(id='content-left') # 如图一红色方框
con_list = con.find_all('div', class_="article") # 找到文章列表
for i in con_list:
author = i.find('h2').string # 获取作者名字
content = i.find('div', class_='content').find('span').get_text() # 获取内容
stats = i.find('div', class_='stats')
vote = stats.find('span', class_='stats-vote').find('i', class_='number').string
comment = stats.find('span', class_='stats-comments').find('i', class_='number').string
author_info = i.find('div', class_='articleGender') # 获取作者 年龄,性别
if author_info is not None: # 非匿名用户
class_list = author_info['class']
if "womenIcon" in class_list:
gender = '女'
elif "manIcon" in class_list:
gender = '男'
else:
gender = ''
age = author_info.string # 获取年龄
else: # 匿名用户
gender = ''
age = ''
save_txt(output.format(page, author, gender, age, vote, comment, content))
def save_txt(*args):
for i in args:
with open('qiubai.txt', 'a', encoding='utf-8') as f:
f.write(i)
def main():
# 我们点击下面链接,在页面下方可以看到共有13页,可以构造如下 url,
# 当然我们最好是用 Beautiful Soup找到页面底部有多少页。
for i in range(1, 14):
url = 'https://qiushibaike.com/text/page/{}'.format(i)
html = download_page(url)
get_content(html, i)
if __name__ == '__main__':
main()
运行代码后,我们会得到 'qiubai.txt'文件,打开后如下所示