压缩列表是列表键和哈希键的底层实现之一。压缩列表是为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。
【压缩列表是一种数据结构,这种数据结构的功能是将一系列数据与其编码信息存储在一块连续的内存区域,这块内存物理上是连续的,逻辑上被分为多个组成部分,其目的是在一定可控的时间复杂读条件下尽可能的减少不必要的内存开销,从而达到节省内存的效果 ————大佬总结】
一.什么时候使用压缩列表?
两种情况:
当一个列表键只包含少量列表项,并且每个列表项要么是小整数值,要么就是长度比较短的字符串。
当一个哈希键只包含少量键值对,并且每个减值对的键和值要么是小整数值,要么就是长度表较短
二. 压缩列表的构成
一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或一个整数值。其就是一个字节数组(char *)。如图:

除了entryx外,一个压缩列表其它4部分是固定的。
Zlbytes:存储一个无符号整数,固定4个字节长度,用来存储压缩列表所占用的内存字节数。当对压缩列表进行内存重新分配时,不需要遍历整个列表来计算内存大小。
Zltail:存储一个无符号整数,固定4个字节长度,记录压缩列表尾节点距离起始地址有多少字节(偏移量),通过这个值,程序不需要遍历整个列表就可以确定表尾节点的地址。
Zllen:压缩列表包含的节点个数,固定两个字节长度,最大只能表示65535个节点,当节点数目超过65535个时,该值无效。需要遍历列表来计算节点的个数。
EntryX:列表节点,长度不定(长度由节点保存的内容决定),由列表节点紧挨着组成。
Zlend:压缩列表结尾标志,固定一个字节长度,固定值0xFF(十进制255)。
内存布局【压缩列表就是一块连续的内存区域】:

三,压缩列表的节点
每个压缩列表节点可以保存一个字节数组或一个整数值。结构如下图:
1. previous_entry_length
单位为字节,记录压缩列表中前一个节点的长度。那么程序可以通过指正运算,根据当前节点的起始地址来计算出前一个节点的起始地址。压缩列表的从表尾向表头遍历的操作就是使用这个原理。
如果前一个节点的长度小于254个字节,那么previous_entry_length长度为1个字节,前一个节点的长度就保存在这一个字节里
如果前一个节点的长度大于等于254个字节,那么previous_entry_length长度为5个字节,第一个字节设置为x0FE(十进制254),之后的四个字节保存前一个节点的长度
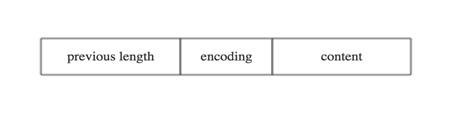
2. encoding
保存了节点的content的内容类型和长度,encoding类型一共有两种,一种是字节数组,一种是整数。
A,字节数组:
当保存字节数组时,编码长度有三种情况:
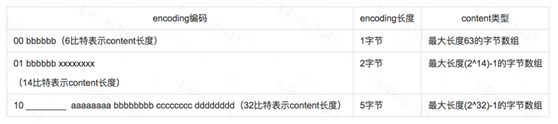
1字节:值的最高位00,content保存的值长度小于等于63字节
2字节:值的最高位01,content保存的值长度小于等于16383字节
5字节:值的最高位10,content保存的值长度小于等于4294967295字节
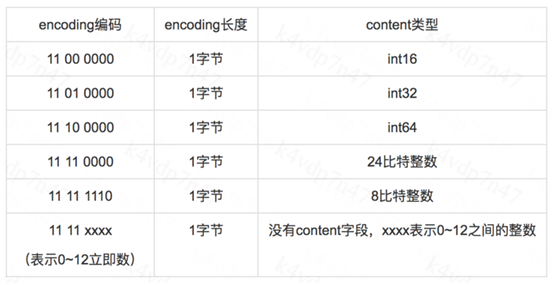
B,整数:
保存整数时,长度位一个字节,值的最高位用11开头
3. content
保存节点的值,节点的值可以是一个字节数组或整数,值的类型和长度由节点的encoding属性决定。
4. 总结:
我们发现encoding第一个字节的前2比特可以区分是字节数组(以及字节数组类型)还是整数;
是整数时,第3、4比特可以区分整数的类型;当content的前4个比特都是1时,后4个比特才能区分整数类型;
四,压缩列表的原理:
相信到这里,我们都明白了压缩列表的原理,压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
五,压缩列表的应用:
Redis中,不同的数据类型广泛地应用了压缩列表编码,整理如下表:

1. 问题思考
Redis为什么使用压缩列表?
使用压缩列表的好处是什么?
压缩列表的应用对与我们使用内存有没有什么启发?
2. 大佬的总结
Redis对于每种数据结构、无论是列表、哈希表还是有序集合,在决定是否应用压缩列表作为当前数据结构类型的底层编码的时候都会依赖一个开关和一个阈值,开关用来决定我们是否要启用压缩列表编码,阈值总的来说通常指当前结构存储的key数量有没有达到一个数值(条件),或者是value值长度有没有达到一定的长度(条件)。任何策略都有其应用场景,不同场景应用不同策略。为什么当前结构存储的数据条目达到一定数值使用压缩列表就不好?压缩列表的新增、删除的操作平均时间复杂度为O(N),随着N的增大,时间必然会增加,他不像哈希表可以以O(1)的时间复杂度找到存取位置,然而在一定N内的时间复杂度我们可以容忍。然而压缩列表利用巧妙的编码技术除了存储内容尽可能的减少不必要的内存开销,将数据存储于连续的内存区域,这对于Redis本身来说是有意义的,因为Redis是一款内存数据库软件,想办法尽可能减少内存的开销是Redis设计者一定要考虑的事情。
另外,经过仔细琢磨,我认为使用压缩列表的好处除了节约内存之外,还有减少内存碎片的作用,我把这种行为叫做"合并存储",也就是将很多小的数据块存储在一个比较大的内存区域,试想想,如果我们将要存储的数据都是很小的条目,我们为每一个数据条目都单独的申请内存,结果是这些条目将有可能分散在内存的每一个角落,最终导致碎片增加,这是一件令人头疼的事情。
六,参考资料:
书籍:《redis设计与实现》
博客:https://my.oschina.net/andylucc/blog/715325,https://segmentfault.com/a/1190000015296224,https://blog.csdn.net/u012658346/article/details/51321337