下面是试验的主要步骤:
在上一篇文章中LZ已经介绍了,实验的环境和实验目的。
在本篇文章中主要介绍侧重于对Kettle ETL的相应使用方法,
在这里LZ需要说明一下,LZ成为了避免涉及索引和表连接等操作,
在数据库mysql中重新创建一个不带有索引和外键约束的 customers数据库表。
但数据集合不变。
所以在后文中国使用,mysql.customers来代替前篇文章中的test.customers。
下面的截图是使用Spoon工具来整体对这个流程的描述:
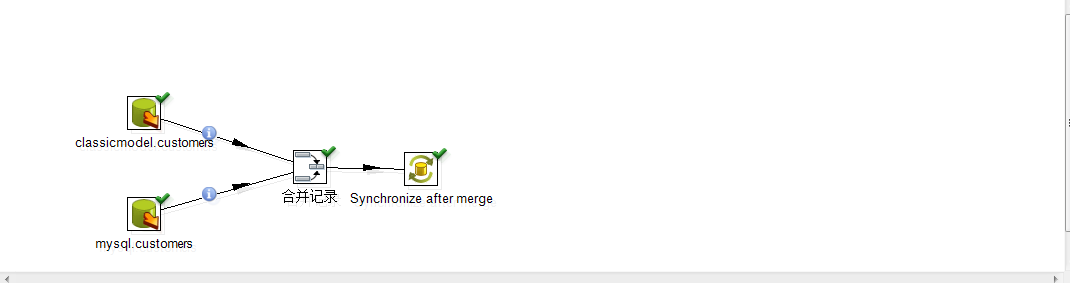
(图)
首先需要使用Kettle来建立两个对数据库数据源的连接:
如图所示: 其中我们所使用的:classicmodels.customers(数据库名.表名)
这张表对应的数据源连接名称是: MysqlConn1 创建数据源连接MysqlConn1如下图所示:
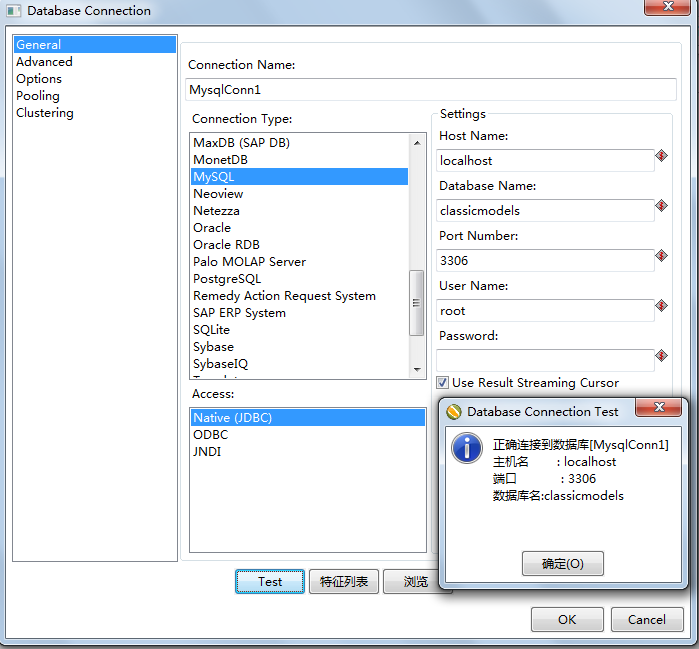
而需要与classicmodels.customers做数据同步的表mysql.customers(数据库名.表名) 这个对应的连接是:
MysqlConn2。 在Spoon中创建MysqlConn2的截图如下所示:
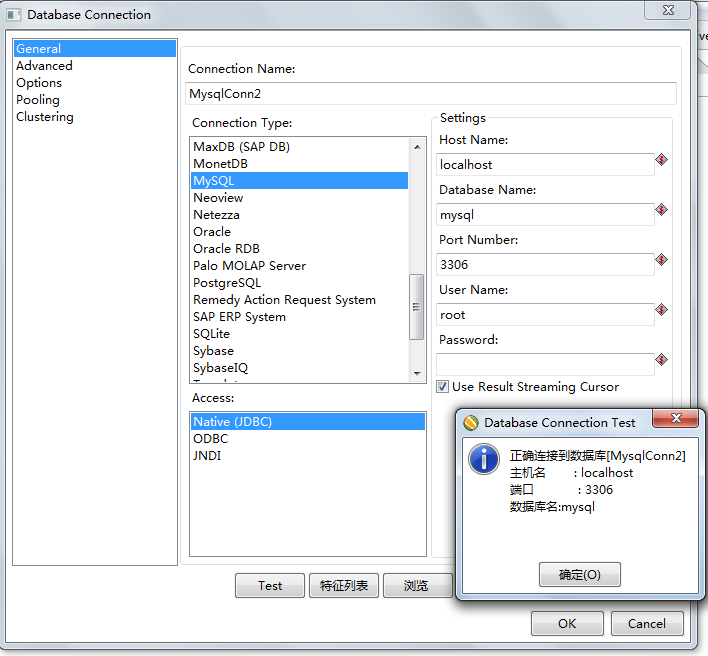
在创建数据库连接之后,需要在相应的transformation中 拽入表输入这一个step。
因为是关于不同数据库中的数据表做数据同步,
所以数据流的流动方向是,
从mysql.customers表中出来,
一一与classicmodels.customers表中的每个记录进行比较等等操作。
而它们来自于不同的数据源的两张表, 所以需要两个表输入(step),
每一个step对应的是kettle源码中的 不同的类,而你从工具栏中将相应的step拖到工作区间的时候,
实质上是完成了,对类对象的实例化操作。
为了方便记忆,把classicmodels.customers对应的那个表输入命名为 classicmodels.customers;
而把mysql.customers对应的那个表输入step重新命名为mysql.customers(这里命名是随意的,是为了方便记忆,
当然读者还可以根据个人的习惯,比如顺便标志出哪一个是 旧数据源,哪一个是新数据源,等等)
具体的操作如下图所示:
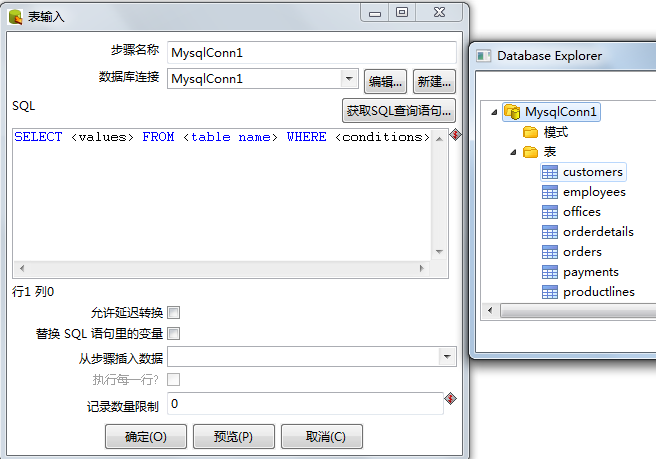
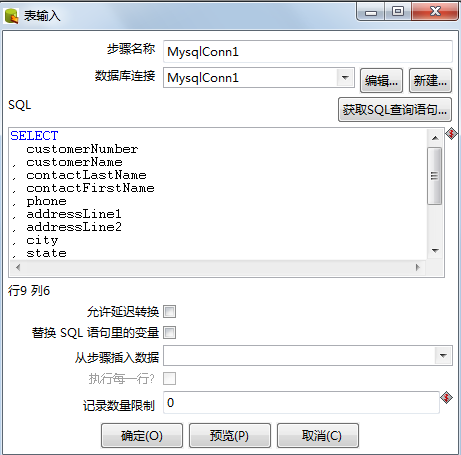
在这里仅选取针对于classicmodels.customers这一个表输出进行讲述(二者的设置过程是一样的):
在这里需要注意的是,首先应该从下拉菜单中选取与之对应的数据源连接,
然后千万不能忘到此仅仅完成的是对数据库的选取,
接下来需要点击“获取SQL查询语句”
一次来选取这个数据源主要是针对数据库的那个表进行抽取数据的。
然后呢,从核心对象工具栏中选择出来,合并记录的Step,
将其拖拽到对应的工作区域,并将俩个表输入step与之相连接
(hop指的是用于连接两个step的矢量连线)。
接下来就是根据实验要求对合并记录进行相应的设定,具体的操作请看截图:
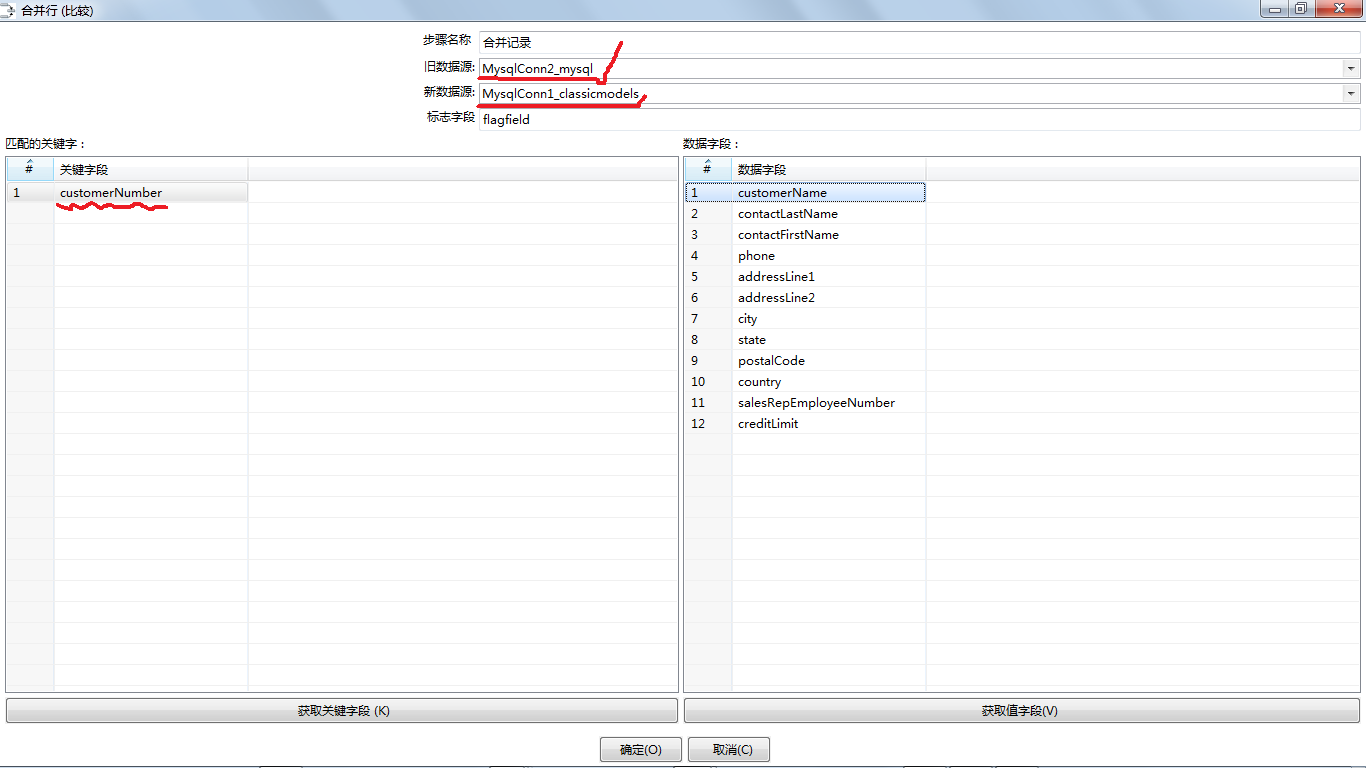
在这里面需要说明的是, 弹出窗口的第一个选项: 旧数据源应该是需要被同步的,就是里面的数据比较陈旧, 需要根据新数据源中的数据进行调整。
而新数据源,在实际的应用中指的是每天或是定期获取的最新数据所对应的数据源。
旧数据源通常是根据新数据源进行相应的增、删、改等一系列操作的。
对于所测试的数据,我是这样想的, 首先应该自己先想好,测试的情况应该大致分为几种情况。
然后根据相应的情况来自己来写一些少量的几条简单的数据集合。
进行测试, 待到得到想要的结果之后,这个时候基本上你的step设计已经完成了, 这样再在这个transformation上面来跑比较大的数据集的话就比较能考到结果了。
跑大的数据集
一个是可以找到一些你自己之前没有考虑到的情况,
二就是可以可以很容易看出来到底数据是在哪一个step的上面 耗费的时间比较长,
可以针对耗时比较长的step作相应的优化处理。
进行step替换或是其他的一些脚本什么的(抱歉,这里LZ暂时也不没有亲自试验验证)预先处理的方法。
其实提高同步数据效率它的主旨就是减少需要处理的数据,
所以在进行同步数据处理之前,
可以调用一些分支step来过滤或是删除一些重复的数据等等。
具体情况是需要具体的分析的。
这里需要说明一下的就是:Kettle中的合并记录这一个Step是这样的:
源库是不提供保存增删改信息的,
而Kettle会提供一种用于 对比输入的新旧两个数据源,
通过关键字进行逐个比较每条记录。
会根据具体的比对的出一下的四种返回值, 而且这四个返回值的类型是String字符串类型, 是的,没错,因为Kettle就是使用Java实现的,
所以一些变量直接与Java中的数据类型是直接对应的。
1、"identical":它对应的是关键字在新旧数据源中, 都是一致的,并且该关键字所在的记录的各个字段的域值相同的话,
则对旧数据源所对应的数据表不做任何处理。
2."changed":关键字在新旧数据源中都是存在的,但是关键字所对应的 记录的域值是不相同的,
这是要将旧数据源依照新数据源做更新操作。
3."new": 旧数据源所对应的数据表中没有与新数据源表中出现的关键字匹配的话,
则将该新数据源关键字对应的记录插入到旧数据源对应的数据表中。
4."deleted": 在旧数据源数据表中的关键字与新数据源表中的所有关键字都是不匹配的。
这种情况就需要把旧数据源中的该关键字对应的那条记录从旧数据源表中删除。
所需要进行匹配的关键字段是新旧记录源的主键所在字段, 而所要进行修改和更新的字段是旧数据库中的所有字段。
为了确保程序的正常进行, 可以先针对合并记录这个step先快速启动一下,
下图是启动合并记录之后,相应的返回值截图:


由于记录有点长,所以只截取了对应的changed、deleted、identical、 这四个所对应的字段。
刚刚好和设想的是一致的。(也就是说与LZ设计的数据表中的数据值,详情请看前一篇实验环境搭建,其实说不上是设计,就是简单修改几个数吧...呵呵)
而就像上面所讲述的一样,合并记录在执行之后返回{identical,changed,deleted,new}这四种String的值。
而后续的synchronize after merge 这个step会根据接收到的 这四种不同的String做出相应的对旧数据源的{增、删除、更新、或是不动} 这四种操作。
既然这一步得到了与设想一直的结果, 那么继续向下使能合并记录到同步数据之间的hop吧~
正如想象的一样, 数据被成功的从新数据源对应的classicmodel.customers中 同步到旧数据源对应的mysql.customers数据表中。
下图是整体的运行时间截图:
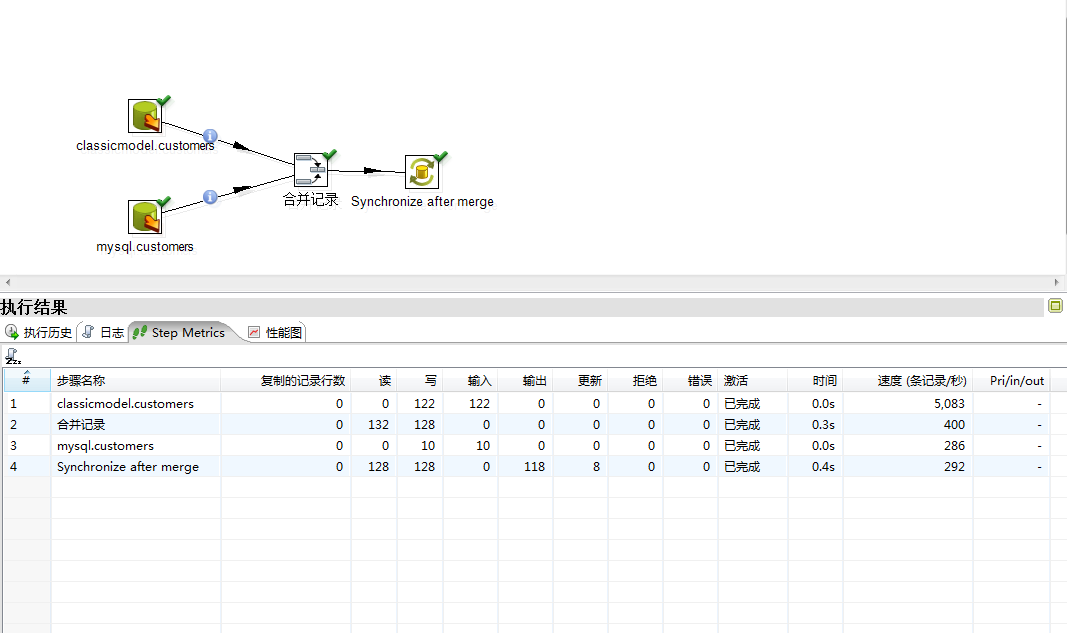
你看,mysql.customers对应写的是10条LZ改写的数据。
而classicmodel.customers对应的是我们从第三方下载的数据集合进行简化之后,
所得到的的数据集中的记录数目。
接下来将要实验的是,针对有索引和外键还有各种约束进行数据同步中所需要采用的方法。
其实,数据库中的数据表在实际的情况下,真的是各种关联,并且是牵一发而动全身的。
所以,还是继续学习吧,加油啦,米娜~