在进行数据流转换之前,我们先介绍一下使用场景:以IISLOG为依据,进行网站点击率分析(IP & PV 分析),具体需求如下:
(1)分析一段时间内,网站点击率的变化趋势。同时还需要知道各个周未、各个节假日网站的流量情况。
(2)分析一天内,各时段(以小时为单位)网站的压力情况。
(3)了解网站客户群分别来自哪些国家,哪些地区。
为了实现这些需求,我们建立了如下的数据模型,请看:


 代码
代码
GO
--建立事实表
CREATE TABLE [dbo].[IISLog](
[lngID] [bigint] NOT NULL,
[lngShopID] [int] NULL,
[lngDateID] [int] NULL,
[lngTimeID] [int] NULL,
[csDateTime] [datetime] NULL,
[lngIpID] [int] NULL,
[cIP] [varchar](30) NULL,
[csUriStem] [varchar](1000) NULL,
[csUriQuery] [varchar](1000) NULL,
[scStatus] [varchar](30) NULL,
[UserAgent] [varchar](255) NULL,
[lngReferer] [int] NULL,
[csReferer] [varchar](1000) NULL,
[csRefererKPI] [varchar](1000) NULL,
[lngFlag] [int] NULL
) ON [PRIMARY]
--IP库
CREATE TABLE [dbo].[dimIP](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[ipSegment] [nvarchar](20) NULL,
[strCountry] [varchar](20) NULL,
[strProvince] [varchar](20) NULL,
[strCity] [varchar](50) NULL,
[strMemo] [varchar](100) NULL,
CONSTRAINT [PK_ID] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
--日期
CREATE TABLE [dbo].[dimDate](
[lngDateID] [int] NOT NULL,
[lngYear] [int] NULL,
[strMonth] [varchar](10) NULL,
[dtDateTime] [datetime] NULL,
[strQuarter] [varchar](10) NULL,
[strDateAttr] [varchar](10) NULL,
[strMemo] [varchar](50) NULL,
CONSTRAINT [PK_dimDate] PRIMARY KEY CLUSTERED
(
[lngDateID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
--时间
CREATE TABLE [dbo].[dimTime](
[lngTimeID] [int] NOT NULL,
[lngHour] [int] NULL,
[strHour] [varchar](10) NULL,
[strTimeAttr] [varchar](10) NULL,
[strMemo] [varchar](50) NULL,
CONSTRAINT [PK_dimTime] PRIMARY KEY CLUSTERED
(
[lngTimeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
下面,我们就一步一步地介绍,如何进行数据流转换,以达到上面的需求。
(一)、"条件性拆分(Conditional Split )"。相当于Sql 语句的Where 条件。这或许是所有数据流转换任务的第一步,为了减少后续处理的数据量,为了提高系统性能,先过滤掉不需要的记录。前面讲过,IisLog 文件包括有各式各样的记录,而对本例需求来说,为了准确计算IP、PV数据,我们将如何过滤呢?
(1)、筛选出纯网页浏览记录。即*.aspx、*.htm(本网站只有这两种类型的网页文件)文件记录。
(2)、筛选出请求成功的记录(sc-Status=200)。
打开上一篇文件的SSIS Solution,切换到数据流Tab,从左边工具箱中,打开“数据流转换”,找到“条件性拆分(Conditional Split)”组件,拖到数据流面板上,然后将“平面文件源”组件下的绿色箭头拖到“条件性拆分”组件上,双击“条件性拆分”组件,打开“条件性拆分转换编辑器”,如图:
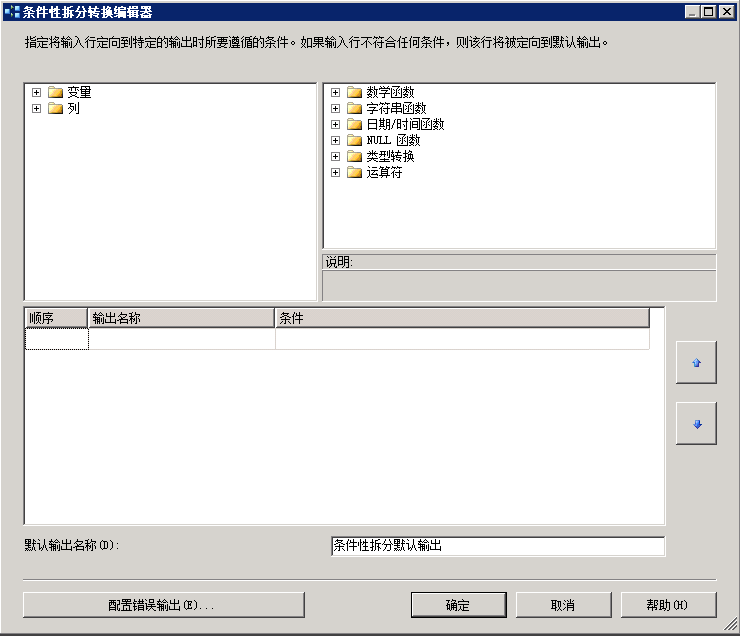
在这个窗口,有系统变量、数据源列、系统函数这些资源可供使用。我们为了筛选出纯网页浏览记录,需要从列cs_uri_stem中找到以.aspx、.htm、“/” 结尾的页面链接。请分别在上图列表的“输出名称”栏位,输入“Form Records”,在条件表达式栏位输入:
然后筛选请求成功的记录,其表过式为:
最后将两个表达式组合起来,即为:
如图所示:
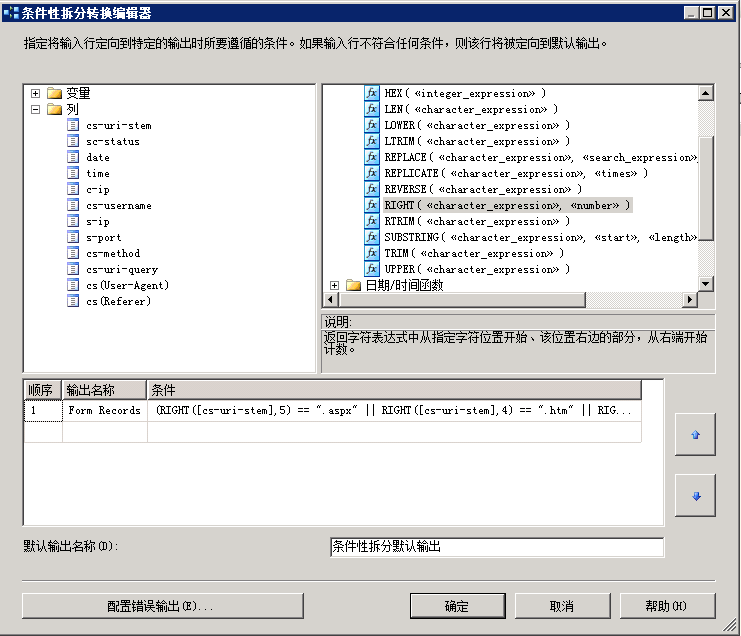
点击确定.数据过滤就算大功告成了。
(二)、派生列(Derived Column),相当于SQL语句中的计算列,即根据其它列,按照一定的计算公式,派生出一个新列。在此例中,有三种情况需要用到派生列:
(1)日期列,从log文件导入的日期、时间,为两个独立的字符串(varchar),而数据库中的对应字段为Datetime 型,如果要想建立一种映射,则需要根据log 文件的Date 、time 字段,派生出一个Datetime 型的字段。
(2)时间段,同理log 文件中的Time 为一字符串,需要取出其中的“小数(hour),才能与dimTime 中的lngHour 相匹配。
(3)IP,我们想根据客户IP,确定他所在国家、省市、地区。要达到这一需求,我想并不需要IP完全匹配,只要IP的前三段匹配,就可以确定了(没有考证过,个人感觉而已,如不妥,请指正),所以需要派生出一个ipSegment =IP的前三段,以此映射他所在的地区。
同理,从工具箱中,将“派生列”组件拖到“条件拆分”组件的下方,再将“条件拆分”组件下方的绿色箭头拖到“派生列”组件上,系统会弹出一窗口,要求选择条件拆分的的输出名称,如图:
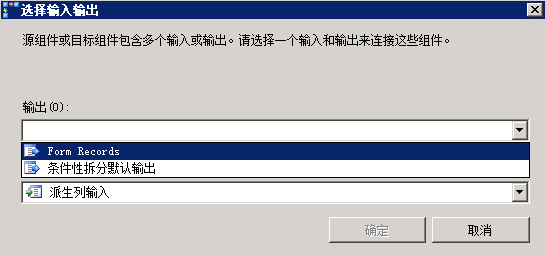
从下拉列表框中选择“Form Records”,点击确定。
然后再双击“派生列”组件,打开“派生列转换编辑器”,如图:
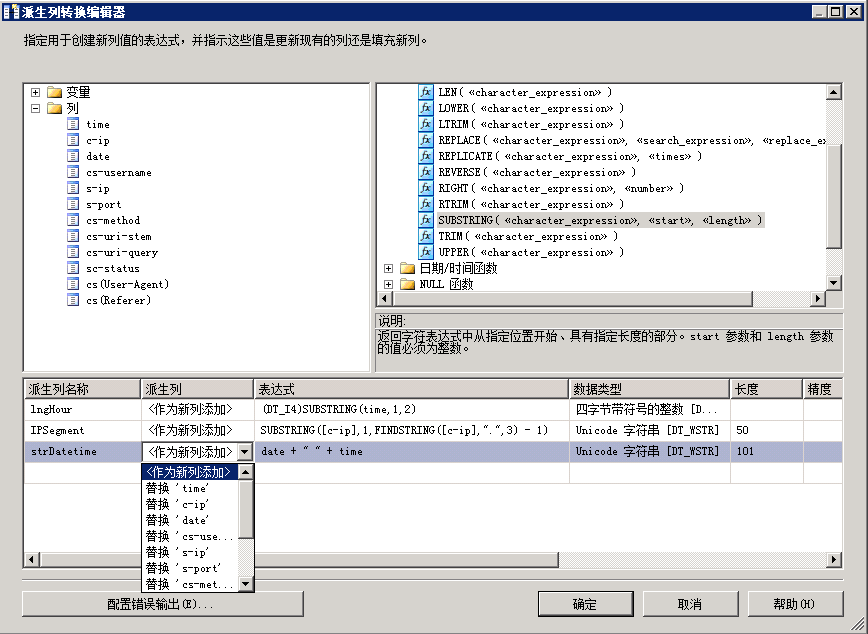
这个窗口太眼熟了吧,那不是前面讲的“条件性拆分编辑窗口”吗?是的,非常类似,我就不罗嗦了,按图上要求,输入派生列名称,选择派生类型,输入表达式,后面的数据类型、数据长度、精度等属性,将根据派生表达式自动生成,一般是不允许修改的。
(三)、数据类型转换。在Integration Services 中,数据类型匹配要求是相当严格的,尤其是后面要讲的查找(Lookup)组件,数据类型必须绝对匹配,才能Join ,否则将不成功。
Integration Services 中的数据类型,它为了兼容多种数据源(比如平面文件、MssQL、ORACLE、DB2、MYSQL等),在形式上它不同于前面说的任何一种数据源的数据类型,一旦数据进入Integration Services 包中的数据流中时,数据流引擎就会将这些列的数据转换为Integration Services 的数据类型,前面介绍的“条件性拆分”、“派生列”中的表达式,都是对这种Integration Services类型的数据进行操作。所以如果后面要应用到查找(Lookup)组件,就必须要对这种数据类型进行转换,才可以与查找源(关系型数据库中的表或视图)的列匹配。具体操作为:
从工具箱中,将“数据转换”组件拖到窗口上,将上一组件(派生列)组件下面的绿色箭头拖此组件上,双击打开“数据转换组件”,如图:
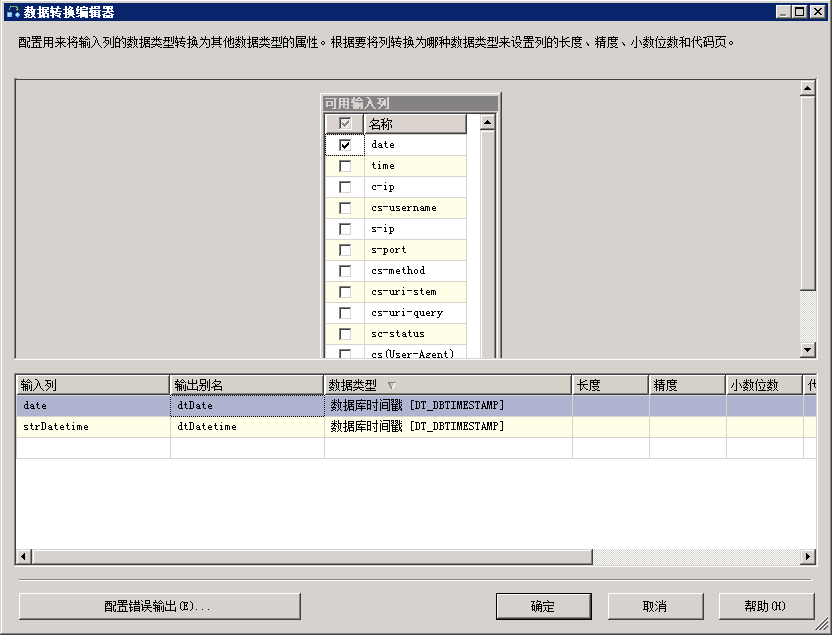
勾选要进行数据类型转换的列:Date,strDatetime,将它们转换MSSQL的Datetime 类型。
特别说明一下,Integration Services数据类型与其它关系型数据库的数据类型之间的关系是比较复杂,如果凭空猜想,很难找到它们之间的对应关系,请参考Microsoft 说明文档,那里面有非常详细的说明。Integration Services 数据类型
(四)、查找(Lookup),类似于Sql 中的Left Join 、Right Join ,一般可以实现两方面的功能:(1)输出匹配的项;(2)、输出无匹配项,这个功能在ETL中应用是相当频泛的,如果善加利用,可以实现很多功能。前面两种数据流转换(派生列、数据类型转换)都是为Lookup 铺路搭桥的。在这个例子,有三个列需要查找,IP、Date、Time。只要一切准备工作就绪,Lookup 就容易多了。
将“查找(Lookup)”组件拖到窗口中,连接上一组件的绿色箭头,双击打开“查找转换编辑器”,如图:
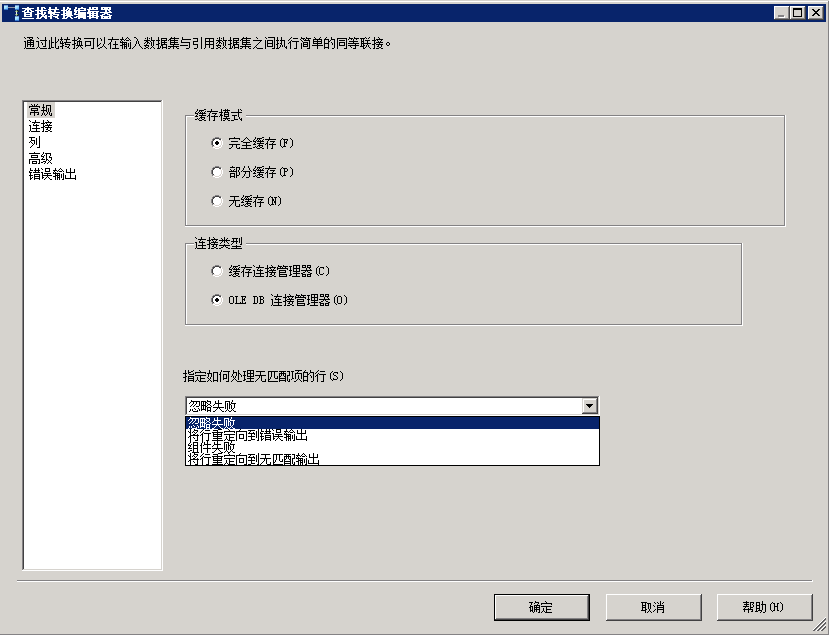
这可比以前的编辑器,复杂一些了吧,其实也并没有那么可怕,如果一般用用,很多地方都按Default 设置,那也是很容易的。但是ETL的性能,在这一步是蛮关键的。首先看缓存模式:
完全缓存:是指在查找转换前,先把引用数据集,完全缓存在内存中,供以后查找时用。
部分缓存:在执行“查找转换”时生成引用数据集,并将有匹配的数据行加载到缓存中,没有匹配的数据行则丢弃。
无缓存:在执行“查找转换”的过程中生成引用数据集,但不加载入缓存。
通过上面的解释,利弊已经很明显了,不同的情况,可能需要不同的处理策略,自已权衡吧。
连接类型,实际上也很清楚了,就不多说了。
指定如何处理无匹配的行:这一选项非常重要,共有四个选项:
忽略失败:就是说遇到无匹配的项,忽略,程序继续执行。
将行定位到错误输出:无匹配的记录,通过错误数据流路径(红色箭头)输出,供以后人手分析处理。
组件失败:如果遇到无匹配的项,组件立即失败,程序停止执行。
将行定位到无匹配输出:输出无匹配的记录集。此选项通常用于查找是否有新的记录产生,如果有新记录出现,则导入,已有匹配的记录集忽略。本例中,IP查找将会用这一选项,如果遇到一个新IP,则插入到数据仓库中,否则,就则忽略此记录,不再重复插入了。
选择“连接”,如图:
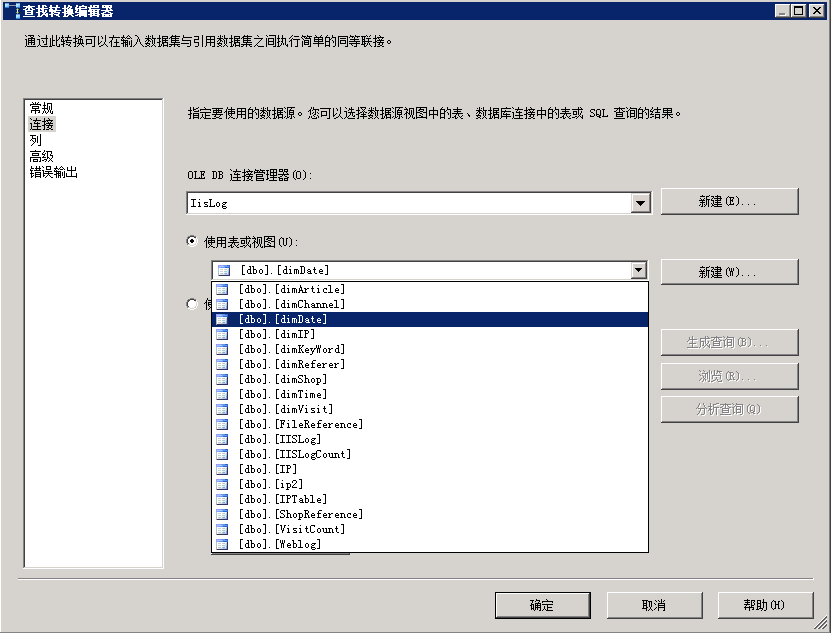
选择连接管理器IisLog,在表或者视图拉列框中选择“dimDate“。
切换到“列”,将[可用输入列]中的“dtDate”拖到[可用查找列]的“dtDatetime”,两个字段间w会连一条直线,表示相互建立连接关系,前面说过,如果这两列的数据类型不一致,这种关系将无法建立。最后在“可用查找列”中勾选“lngDateID”,作为输出。点击确定,lngDateID 的查找就完成了。
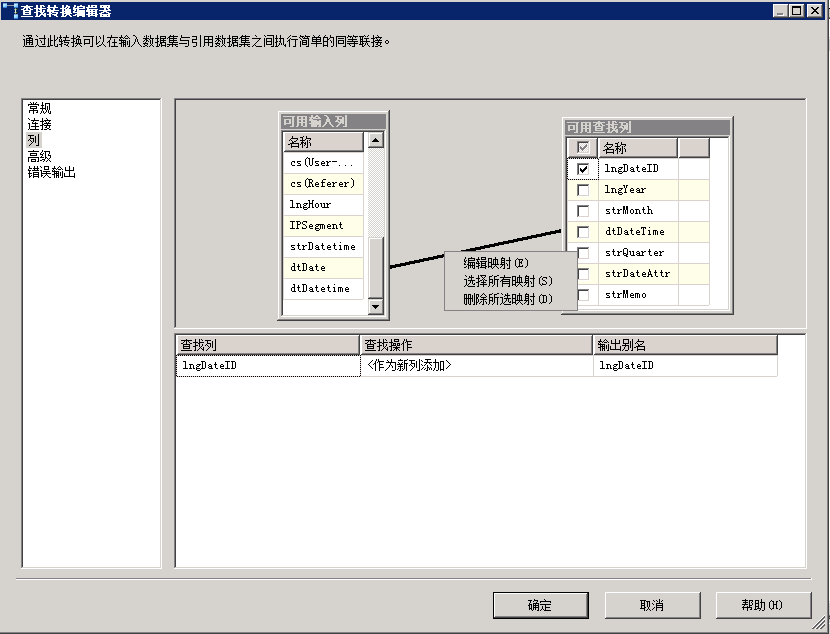
其它两个,有兴趣的朋友可以自动手试试,看能否成功。
这样,数据转换就算完成了,最后接着上课的数据流目标,将源列与目标映射起来,如图:
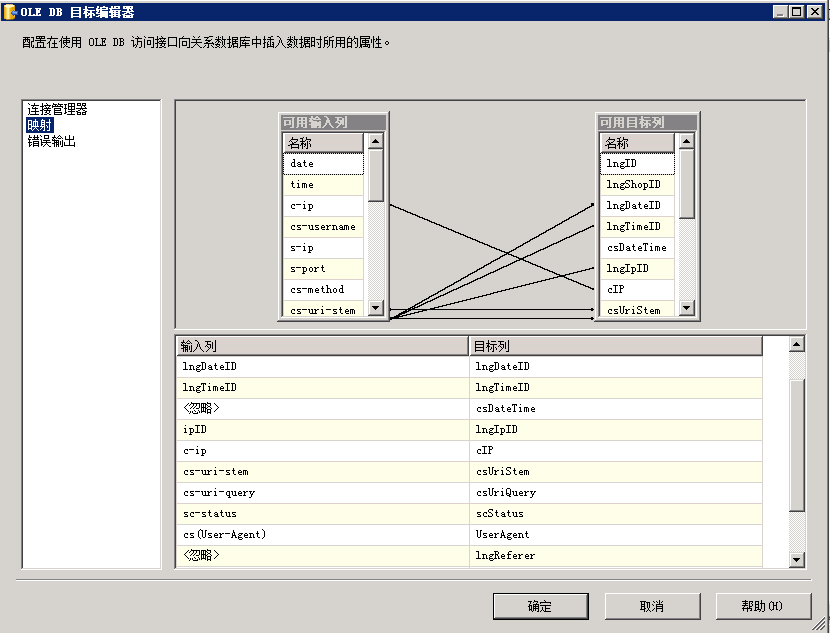
点击“运行”,梦想中的绿色境界,就出现了。

源码下载:IisLog 源码下载