为什么要有集合
面向对象语言对事物的体现都是以对象的形式体现,所以为了方便对多个对象的操作,就是对对象进行存储,集合就是存储对象最常用的一个方式。
数组与集合有什么不同
数组的长度是固定的,而集合的长度是可变的。
数组可以存储基本数据类型,而集合只能存储对象。
集合的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
什么是框架
框架(framework)是一个类的集,它奠定了创建高级功能的基础。框架包含很多超类,这些超类拥有非常有用的功能、策略和机制。框架使用者创建的子类可以扩展超类的功能,而不必重新创建这些基本的机制。
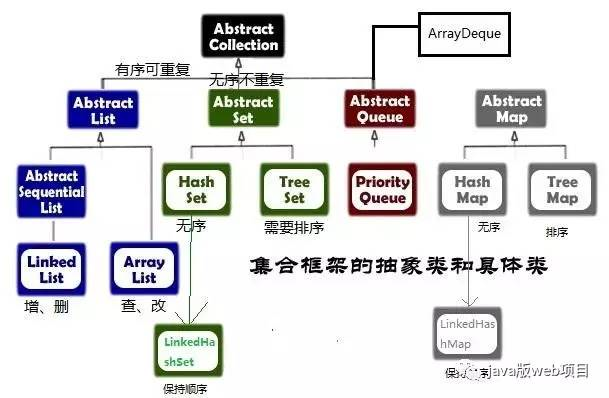
集合框架中的类结构图
集合框架中的接口结构图
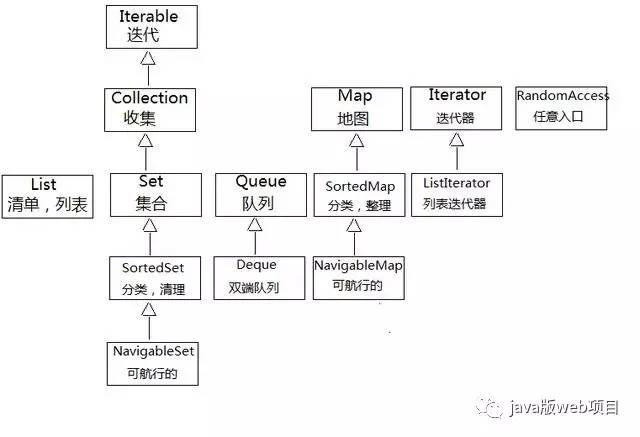
他是所有集合的共性接口类
常用的方法有
1、添加
boolean |
add(E e) 确保此 collection 包含指定的元素(可选操作)。 |
boolean |
addAll(Collection<? extendsE> c) 将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。 |
2、删除
boolean |
remove(Object o) 从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。 |
boolean |
removeAll(Collection<?> c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。 |
3、判断
boolean |
contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 |
boolean |
containsAll(Collection<?> c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 |
boolean |
isEmpty() 如果此 collection 不包含元素,则返回 true。 |
4、获取
int |
size() 返回此 collection 中的元素数。 |
Iterator<E> |
iterator() 返回在此 collection 的元素上进行迭代的迭代器。 |
5、其他
Object[] |
toArray() 返回包含此 collection 中所有元素的数组。 |
| <T> T[] | toArray(T[] a) 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。 |
boolean |
retainAll(Collection<?> c) 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。取2个集合中的元素交集 |
List与Set的特点
List
有序:存入和取出的循序一直。
可以存储重复对象。
添加或删除元素,其后面的元素后往后移动一位置或向前移动一位置。
元素都有索引
常用方法:
void |
add(int index,E element) 在列表的指定位置插入指定元素(可选操作)。 |
E |
remove(int index) 移除列表中指定位置的元素(可选操作)。(返回被删除的对象) |
E |
set(int index,E element) 用指定元素替换列表中指定位置的元素(可选操作)。(返回被修改的对象) |
E |
get(int index) 返回列表中指定位置的元素。 |
int |
indexOf(Object o) 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。 |
int |
lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。 |
List<E> |
subList(int fromIndex, int toIndex) 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。(左闭右开) |
List实际项目中常用的实现类
Vector:内部是数组数据结构,是同步的。(都不用了),增删查询都很慢。
ArrayList:内部是数组数据结构,是不同步的。(替代Vector的),查找元素的速度很快,增删慢。(因为存储的空间是连续的,所以查起来很快)。
LinkedList:内部是链表数据结构,是不同步的。增删元素速度很快,查询速度慢。
集合为什么大多都不同步?因为效率高。
Set
可以有序,可以无序,一般情况无序
不可以存储重复对象
元素没有索引,只能通过迭代器获取对象
循环数组
循环数组是一个有界集合,即容量有限。如果程序中要收集的对象数量没有上限,就最好使用链表来实现。
迭代器接口
Iterator(迭代器)接口
集合中的iterator()方法返回一个实现了Iterator接口的实例对象,可以用这个迭代器对象,依次访问集合中的元素。
Iterator接口中只有三种方法
如果达到了集合的末尾,next()方法将抛出NoSuchElementException异常。因此,在每次调用next()方法前都要做一下hasNext()的判断。
例如:
Collection<String> c = ...;
Iterator<String> iter = c.iterator();//获得c集合的迭代器
while(iter.hasNext()){
String element = iter.next();
System.out.print(element);
}
JDK1.5的新特性for each循环,它可以与任何实现了Iterable(迭代)接口的对象一起工作。其中只有一个方法Iterator<E> iterator();
next()方法
迭代器可以理解为是位于2个之间的,当调用next()方法的时候,迭代器向前移动一个位置,并返回刚刚越过的那个元素的引用。如图所示:
删除元素(remove()方法)和添加元素(add()方法)
Iterator接口的remove()方法将会删除上次调用next()方法时,返回的那个元素。示例代码如下:
package paly;
import java.util.Collection;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
public class WorkerTest {
public static void main(String[] args) {
LinkedList<String> ll1 = new LinkedList<String>();
Iterator<String> ll1Iterator = ll1.iterator();//Iterator没有add方法
System.out.println(ll1Iterator.hasNext());//返回false
ListIterator<String> listIterator = (ListIterator<String>) ll1.iterator();
// ll1Iterator.next();//报错
listIterator.add("zhangfan1");//向ll1集合中添加东西
listIterator.add("zhangfan2");//向ll1集合中添加东西
listIterator.add("zhangfan3");//向ll1集合中添加东西
listIterator.add("zhangfan4");//向ll1集合中添加东西
listIterator.add("zhangfan5");//向ll1集合中添加东西
myIterator(ll1);
// System.out.println(listIterator.hasNext());//迭代器里面没有东西
// listIterator.remove();//这里报错
// ll1Iterator.remove();//这里报错,估计要重新再次获得迭代器吧
// ll1Iterator.next();
listIterator = ll1.listIterator();//重新获得迭代器
System.out.println("将迭代器想右移动一位置:"+listIterator.next());//------位置一
listIterator.remove();//结果zhangfan1被删除了------位置二
// listIterator.remove();//这里报错,因为迭代器,在位置二的时候,已经把它越过的前一元素给删除了,现在这里没有元素,所以不能删除
// 现在删除zhangfan3
// 由于在位置一的时候迭代器向后越过了一位置,返回的是zhangfan1,而zhangfan1在位置二的时候被删除,现在要删除zhangfan3就要在向后越过2元素
myIterator(ll1);
listIterator.next();
listIterator.next();
listIterator.remove();//删除zhangfan3
System.out.println("删除zhangfan3以后");
myIterator(ll1);
}
public static void myIterator(Iterable a){//Collection
Iterator<String> temp = a.iterator();
while (temp.hasNext()) {
System.out.println(temp.next());
}
}
}
运行结果:
false
zhangfan1
zhangfan2
zhangfan3
zhangfan4
zhangfan5
将迭代器想右移动一位置:zhangfan1
zhangfan2
zhangfan3
zhangfan4
zhangfan5
删除zhangfan3以后
zhangfan2
zhangfan4
zhangfan5
Collections类
static<T> int |
binarySearch(List<? extendsComparable<? super T>> list, T key) 使用二分搜索法搜索指定列表,以获得指定对象。 |
1、返回int,如果有要找的key就返回,key所在的位置。
2、返回int,如果没有要找的key就返回负数,并带添加次key值的插入点,并且插入进去后,数组还是拍好序列的,里面是-min-1,所以用得到的负数+1,取正就是插入点的索引
static<T> int |
binarySearch(List<? extends T> list, T key,Comparator<? super T> c) 使用二分搜索法搜索指定列表,以获得指定对象。 |
1、根据自定义比较器,进行比较,Comparator是一个接口,其中的比较方法要程序员自己实现。
Arrays类
static<T> List<T> |
asList(T... a) 返回一个受指定数组支持的固定大小的列表。 |
LinkedList<E>类
链表(相关类:List、LinkedList<E>、Iterator<E>、ListIterator<E>、Iterable<T>)
在数组和数组列表中,有很大的一个缺陷,就是每次添加非队列末尾的一个元素时,其后面的元素都要向后移一位置,或每次删除非队列末尾的一个元素时,其后面的元素都要向前移动一个位置。这就是其添加和删除的效率不高。而链表很好的解决了这一问题。
在Java程序设计语言中,所有链表实际上都是双向链接的。即每个结点还存放着指向前驱结点的引用。如下图所示:
删除一个元素:
链表和泛型集合的重要区别是:链表是一个有序集合。
LinkedList<E>的add()方法是将元素添加到集合的末尾,但常常要添加到其他元素的中间,用Iterator<E>接口的子接口ListIterator<E>实现添加的功能,还可以向前查询元素
示例代码:
package paly;
import java.util.Collection;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
public class WorkerTest {
public static void main(String[] args) {
LinkedList<String> ll1 = new LinkedList<String>();
Iterator<String> ll1Iterator = ll1.iterator();//Iterator没有add方法
System.out.println(ll1Iterator.hasNext());//返回false
ListIterator<String> listIterator = (ListIterator<String>) ll1.iterator();
// ll1Iterator.next();//报错
listIterator.add("zhangfan1");//向ll1集合中添加东西
listIterator.add("zhangfan2");//向ll1集合中添加东西
listIterator.add("zhangfan3");//向ll1集合中添加东西
listIterator.add("zhangfan4");//向ll1集合中添加东西
listIterator.add("zhangfan5");//向ll1集合中添加东西
ll1.add("zhangfan6");//调用的是LinkedList的add方法,那它还在zhangfan5的后面
System.out.println("----------------添加zhangfan6");
myIterator(ll1);
// 现在在zhangfan4和zhangfan5之间添加3个元素看看效果
listIterator =ll1.listIterator();//重新获得迭代器
System.out.println("-------------迭代器刚刚越过的元素:"+listIterator.next());//不知道迭代器现在的位置在哪,打印出来看看
listIterator.next();//越过zhangfan2
listIterator.next();//越过zhangfan3
listIterator.next();//越过zhangfan4,现在迭代器在zhangfan4和zhangfan5之间
listIterator.add("zhangfan7");
listIterator.add("zhangfan8");
listIterator.add("zhangfan9");
myIterator(ll1);
System.out.println("--------------向前查询元素:"+listIterator.previous()+"下一个index:"+listIterator.nextIndex());
System.out.println("--------------向前查询元素:"+listIterator.previous()+"前一个index:"+listIterator.previousIndex());
System.out.println("--------------向前查询元素:"+listIterator.previous()+"前一个index:"+listIterator.previousIndex());
System.out.println("--------------向前查询元素:"+listIterator.previous()+"前一个index:"+listIterator.previousIndex());
}
public static void myIterator(Iterable a){//Collection
Iterator<String> temp = a.iterator();
while (temp.hasNext()) {
System.out.println(temp.next());
}
}
}
LinkedList也提供了get(int i)方法来查询元素,但是效率极其低下。
面试题:10、 有100个人围成一个圈,从1开始报数,报到14的这个人就要退出。然后其他人重新开始,从1报数,到14退出。问:最后剩下的是100人中的第几个人?
package paly;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.ListIterator;
/**
* 10、 有100个人围成一个圈,从1开始报数,报到14的这个人就要退出。然后其他人重新开始,
* 从1报数,到14退出。问:最后剩下的是100人中的第几个人?
*
* @author Terry
* @date 2014-6-9
*
*/
public class Test10 {
static int howPoeple = 5674;
int indexRecord = 0;//索引记录
static final List<People> circlePeople = new ArrayList<People>();//圆圈
static LinkedList<People> linkedList = new LinkedList<People>();
/**
* @param args
*/
public static void main(String[] args) {
//看了运行结果,感觉不对,先做其他的,然后回来用面向对象的方式对比看看
begin(346);
counOffByLinkedList(howPoeple,346);
System.out.println("最后剩下"+howPoeple+"人中的第"+linkedList.getFirst().getNumber()+"人");
}
/**
* 测试重新获得迭代器,迭代器位置会变成第一个不,结果会还原
*/
public static void test(){
for (int i = 0; i < 5; i++) {
People people = new People();
people.setNumber(i);
linkedList.add(people);
}
ListIterator<People> li = linkedList.listIterator();
System.out.println(li.hasNext());
for (int i = 0; i < 5; i++) {
System.out.println(li.next().getNumber());
}
li = linkedList.listIterator();
System.out.println("------"+li.next().getNumber());
}
/**
* 用LinkedList来实现
* @param size:有多少人
* @param index:第几个人开始报数
*/
public static void counOffByLinkedList(int size,int index){
for (int i = 1; i < size+1;i++) {
People people = new People();
people.setNumber(i);
linkedList.add(people);
}
beginCountin(linkedList,index);
}
/**
* 开始报数方法
* @param index,第几个人开始报数
*/
public static void beginCountin(List list,int index){
ListIterator<People> listIterator = list.listIterator(index);
beginCountin(listIterator);
}
public static void beginCountin(ListIterator listIterator ){
/**
* 报数1-14
*/
for (int i = 0; i < 14; i++) {
if(listIterator.hasNext()){
listIterator.next();//报数
}else{
listIterator = linkedList.listIterator();//重新迭代
if(listIterator.hasNext()){
listIterator.next();//报数
}
}
}
if(linkedList.size()>2){
listIterator.remove();
beginCountin(listIterator);
}
if(linkedList.size()>1){
listIterator.remove();
}
}
/**
* 人们开始报数,每报到14,报到14的那个人退出,其他人继续报数
* @param index 取值 index>=0 index<howPoeple,位置index的人第一个报数
*/
public static void countOff(int index){
List<People> people = Test10.circlePeople;
if(people.size()==3){//这里是给debug用的,用来快速到达错误的地方
System.out.println();
}
for (int i = 0; i < 14; i++) {
if(index==people.size()){//index = poeples.size()-1,表示数组中的最后一个人了,index==poeples.size()
// 表示应该是最后一个人的下一个人,也就是返回到第一个人了
index = 0;//又从第一个人开始
}
// People temp = poeples.get(index);//这个人报数,喊完过后,后一个位置的人报数。辅助思考用的
if(i == 13){//代表着要退出一个人了,从1开始报数报,这是第14次报数,前面==13因为索引是从0开始的
if(people.size()>2){//圈里的人数有3人以上
/**
* 代表着数组中的第一个人要退出,然后他后面的人和最后一个人牵手,
* 最后一个人的右边是第二个人,第二个人的左边是最后一个人
*/
if(index == 0){
if(people.size() == 1){//如果圈里面只剩下一个人就不退出了
break;
}
People me = people.get(index);//要退出的人
People lastPeople = people.get(people.size()-1);
People afterMe = people.get(index + 1);
lastPeople.setRightPeople(afterMe);
afterMe.setLeftPeople(lastPeople);
people.remove(me);
System.out.println(people.size()+"::index="+index);
countOff(index);//这里本想index++;的,但是ArrayList元素删除的时候,被删元素的后面元素都会向前移一个位置
}
/**
* 代表着数组中的最后一个人要退出,然后他前面的人和第一个人牵手,
* 第一个人的左边是他前面的人,他前面的人的右边是第一个人
*/
if(index == people.size()-1){
if(people.size() == 1){//如果圈里面只剩下一个人就不退出了
break;
}
People me = people.get(index);//要退出的人
People firstPeople = people.get(0);
People beforeMe = people.get(people.size()-1-1);
firstPeople.setLeftPeople(beforeMe);
beforeMe.setRightPeople(firstPeople);
people.remove(me);
index = 0;//最后一个元素都移除了,他后面没有元素了,所以要从0开始
System.out.println(people.size()+"::index="+index);
countOff(index);
}
//做到这里发现,单独people对其中的左右people交换的时候,可以封装成一个方法,那代码量将会少很多
if(people.size() == 1){//如果圈里面只剩下一个人就不退出了
break;
}
People me = people.get(index);//要退出的人
People afterMe = people.get(index + 1);
People beforeMe = people.get(index - 1);
afterMe.setLeftPeople(beforeMe);
beforeMe.setRightPeople(afterMe);
people.remove(me);
System.out.println(people.size()+"::index="+index);
countOff(index);
}else{
people.remove(index);
}
}
index ++;//每报一次数,数组索引往后移一位置
}
}
/**
* 第一个人和其他2人牵手的方式
* 第一个人和其他2人牵手,他的左边是最后一个人,他的右边是第二个人
*/
public static void fasePeople(int i){//为了方便,这里用static好了,多花点内存,就多花点了,不管那么多了
List<People> temp = Test10.circlePeople;
// if(i == 0){
People me = temp.get(i);
People leftPeople = temp.get(temp.size()-1);
People rightPeople = temp.get(i+1);
me.setLeftPeople(leftPeople);
me.setRightPeople(rightPeople);
// }
}
/**
* 最后一个人和其他2人牵手的方式
* 最后一个人和其他2人牵手,他的左边是倒数第二的人,他的右边是第一个人
*/
public static void lastPeople(int i){
List<People> temp = Test10.circlePeople;
// if(i == temp.size()-1){
People me = temp.get(i);
People leftPeople = temp.get(i-1);
People rightPeople = temp.get(0);
me.setLeftPeople(leftPeople);
me.setRightPeople(rightPeople);
// }
}
/**
* 第二个人和第二个以后的人和其他2个人牵手,他的左边是他前面的那个人,他的右边是他后面的那个人
*/
public static void secondAndOtherPeople(int i){
List<People> temp = Test10.circlePeople;
People me = temp.get(i);
People leftPeople = temp.get(i-1);
People rightPeople = temp.get(i+1);
me.setLeftPeople(leftPeople);
me.setRightPeople(rightPeople);
}
/**
* 开始
* @param index,0-howPoeple之间
*/
public static void begin(int index){
Test10 test10 = new Test10();
// TODO Auto-generated method stub
//howPoeple个人站在一起//这里可以用享元模式
for (int i = 1; i < test10.howPoeple+1; i++) {
People people = new People();
people.setNumber(i);
test10.circlePeople.add(people);
}
//howPoeple个人手拉手围成一个圆圈
for (int i = 0; i < test10.howPoeple; i++) {
// 第一个人和其他2人牵手,他的左边是最后一个人,他的右边是第二个人
if(i == 0){
fasePeople(i);
continue;
}
// 最后一个人和其他2人牵手,他的左边是倒数第二的人,他的右边是第一个人
if(i == circlePeople.size()-1){
lastPeople(i);
continue;
}
// 第二个人和第二个以后的人和其他2个人牵手,他的左边是他前面的那个人,他的右边是他后面的那个人
secondAndOtherPeople(i);
}
countOff(index);
System.out.println("最后剩下"+howPoeple+"人中的第"+Test10.circlePeople.get(0).getNumber()+"人");
}
}
class People{
private int number;//自己的编号
private People leftPeople;//左边的人
private People rightPeople;//右边的人
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public People getLeftPeople() {
return leftPeople;
}
public void setLeftPeople(People leftPeople) {
this.leftPeople = leftPeople;
}
public People getRightPeople() {
return rightPeople;
}
public void setRightPeople(People rightPeople) {
this.rightPeople = rightPeople;
}
}
HashTable类
散列表hash table,可以快速地查找所需要的对象。散列表为每个对象计算一个整数,称为散列码(hash code).
hashcode的作用:
首先,想要明白hashCode的作用,你必须要先知道Java中的集合。
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。
前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。
那么这里就有一个比较严重的问题了:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?
这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。
也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希(Hash)实际上是个人名,由于他提出一哈希算法的概念,所以就以他的名字命名了。
哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。
初学者可以这样理解,hashCode方法实际上返回的就是对象存储的物理地址(实际可能并不是)。
这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。
如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,
就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。
所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
所以,Java对于eqauls方法和hashCode方法是这样规定的:
1、如果两个对象相同,那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同,上面说的对象相同指的是用eqauls方法比较。
当然可以不按要求去做了,但会发现,相同的对象可以出现在Set集合中。同时,增加新元素的效率会大大下降。
示例代码:
String a = new String("BBC");
String b = "bbc";
String c = new String();
String d = "bbc";
System.out.println(a.hashCode());
System.out.println(b.hashCode());
System.out.println(c.hashCode());
System.out.println(d.hashCode());
运行输出:
65539
97315
0
97315
在Java中,散列表用链表数组实现。每个列表被称为桶。想要查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。例如:
如果某个对象的散列码为76268,并且有128个桶,对象应该保存在第108号桶中(76268%128=108)。或许会很幸运,在这个桶中没有其他元素,此时将元素直接插入到桶中就可以了。当然,有时候会遇到桶被占满的情况,这也是不可能避免的。这种现象被称为散列冲突。这时,需要用新对象与捅中的所有对象进行比较,查看这个对象是否已经存在。
TreeSet类
TreeSet类是一个有序不重复集合,它每次添加元素的时候都会进行比较,然后再按顺序添加,所以添加的速度很慢。它的底层数据结构是二叉树。
它有2中排序的方式:一种是,添加的元素自身可以排序,实现了Comparable
另一种是,你给TreeSet定义一个比较器(Comparator),TreeSet根据Comparatro的
int |
compare(T o1,T o2) 比较用来排序的两个参数。 |
来进行比较。当两种排序都存在是优先用给定的比较器进行比较。
示例代码:
SortedSet<String> sorter = new TreeSet<String>();
sorter.add("dbc");
sorter.add("BBC");
sorter.add("bbc");
sorter.add("cbc");
sorter.add("abc");
for (String string : sorter) {
System.out.println(string);
}
运行结果:
BBC
abc
bbc
cbc
dbc
TreeSet(Comparator<? super E> comparator)
boolean addAll();