结对编程
一、博客开头
| 作业要求地址 | https://www.cnblogs.com/harry240/p/11524113.html |
|---|---|
| Github地址 | https://github.com/1517043456/WordCount.git |
| 结对伙伴博客 | https://www.cnblogs.com/xnch/ |
二、描述结对过程
三、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| .Estimate | .估计这个任务需要多少时间 | 400 | 600 |
| Development | 开发 | 300 | 350 |
| .Analysis | .需求分析(包括新技术学习) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 300 | 500 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | · 报告 | 30 | 60 |
| · Test Report | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| ·Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1370 | 1640 |
四、解题思路描述
本次项目的主要难点有三:
(1)、命令行程序传入指令的获取和将指令分解:
解决思路和方法:以命令行的形式运行程序,实际上在WordCount.exe的后面的指令就是主函数main中传入的参数,而这个参数是字符串数组,因此将可以将其直接使用,而单个类似于input.txt 这种指令的参数,可以直接从中获取,因为指令的形式是:【指令 参数】这样的形式。在传入的主函数中的字符串数组是按照顺序存储的,直接根据下表索引即可。(2)、将txt文件中的信息进行相应的处理,获得符合要求的单词形式:
解决思路和方法:毋庸置疑,对从txt文件中获取的数据流来分割为符合要求的单词形式应该使用正则表达式:
//用于分割筛选出每行的字母数字
string argex1 = "s[^0-9a-zA-Z]+";
//用于分割单词
string argex2 = "[a-zA-Z]{4,}[a-zA-Z0-9]";(3)、对于单词的计数和排序:
解决思路和方法:计数比较简单直接从List取得数据的个数就是单词数量。而统计单词对应的频率数则需要使用字典,键为单词,值为个数。
五、设计实现过程
1、需求分析
本次项目需要实现的主要功能:
- 命令行和指令的分解
- 文件的读取
- 字符统计
- 行数统计
- 单词数量统计、当个单词的统计
- 单词词频的统计和排序(输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词)
2、程序流程图
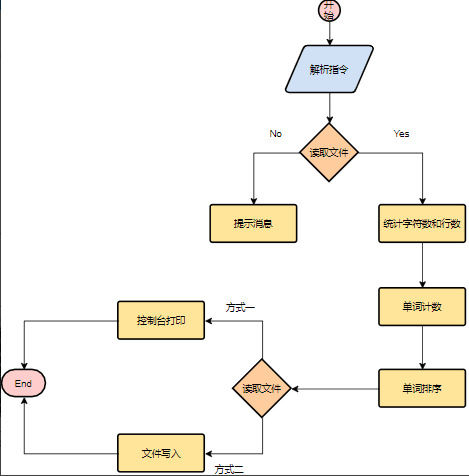
3、项目的类及其解决方案
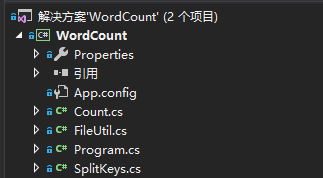
4、类结构和单元测试的设计
本次的单元测试要求尽可能多的覆盖到项目的每一个分支,因此每个类的方法应该足够的分离,也就是方法足够多,职责分明,同时满足耦合度低的要求。因此本次的类和方法的具体如下:
Program类:
主类, 只含有main函数。
SplitKeys类:
public void ActKeys(string[] keys)** 方法,分解主类传来的指令并调用指定的方法。
FileUtil类:
(1) getWordList方法,用于读入文件并在读的时候开始统计字符数和行数。
(2)public void printCountToFile(string result,string output)方法,用于将结果写入文件
Count类:
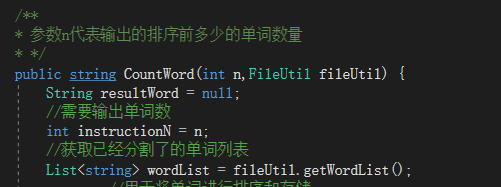
(1)public string CountWord(int n,FileUtil fileUtil),用于执行 -n 指令。统计单词数量以及单词频率,并排序。
(2)public string sumWord(int m,FileUtil fileUtil),用于执行-m指令,统计词组数量并转发结果。
5、代码规范和链接
本次代码的规范主要采用比较大众的一个规范,我们就在网上找了一份我们适合我们经常编写代码习惯且比较具体的代码规范。
代码规范链接
六、代码说明
- 1、指令解析
SplitKeys类,用于将从控制台获取到的指令进行解析,并根据不同指令调用不同功能,相当于整个项目的调度中心。
(1)指令获得和调用
//混合指令的使用
for (; i < keys.Length; i++) {
if (keys[i].Equals("-i")&&keys[i+1]!=null)
{
fileUtil.Filepath = keys[i+1];
}
if (keys[i].Equals("-m"))
{
m = int.Parse(keys[i + 1]);
}
if (keys[i].Equals("-n"))
{
n = int.Parse(keys[i + 1]);
}
if (keys[i].Equals("-o"))
{
o = keys[i + 1];
}
}
当然这里也可以使用Directionary来以键值对的形式进行存储,即Directionary<stirng,string>中,存入<-i,input.txt>指令,这样应该是十分标准的控制台指令存储形式,不过可能会加大代码的复杂性。
(2)、实例化两个类,以便于调用功能。
FileUtil fileUtil = new FileUtil();
Count count = new Count();
- 2、文件的读入和写出
文件的读入和写出由FileUtil类进行,将txt文件读入,并在读入的过程中进行简单的字符数和行数的统计以及单词的分割,最终返回一个处理过后的单词链表,以及键最终结果进行写入txt文件。
(1)、文件的读入和字符数和行数的统计
try
{
StreamReader sr = new StreamReader(this.Filepath, Encoding.Default);
//用于存储读取后的单词
List<string> wordList = new List<string>();
//用于分割筛选出每行的字母数字
string argex1 = "\s*[^0-9a-zA-Z]+";
//用于分割单词
string argex2 = "[a-zA-Z]{4,}[a-zA-Z0-9]*";
//读取一行
string readLine;
while ((readLine = sr.ReadLine()) != null) {
CountChar += readLine.Length;
CountLine++;
string[] wordArray = Regex.Split(readLine, argex1);
foreach (string word in wordArray) {
if(Regex.IsMatch(word,argex2))
wordList.Add(word);
}
}
sr.Close();
return wordList;
}
在读入的时候进行字符数的统计和行数的统计,提高了效率。
这里用到的两个正则表达式:
//用于分割筛选出每行的字母数字
string argex1 = "\s*[^0-9a-zA-Z]+";
//用于分割单词
string argex2 = "[a-zA-Z]{4,}[a-zA-Z0-9]*";
(2)、将结果写入文件
try
{
string txtfile = output;
StreamWriter sw = new StreamWriter(txtfile);
sw.Write(result);
sw.Flush();
sw.Close();
Console.WriteLine(output+"文件写入完毕!");
}
catch (Exception e)
{
Console.WriteLine("文件写入失败!");
}
- 3、单词的相关统计和排序
(1)、单词和对应词频统计
public string CountWord(int n,FileUtil fileUtil) {
String resultWord = null;
//需要输出单词数
int instructionN = n;
//获取已经分割了的单词列表
List<string> wordList = fileUtil.getWordList();
//用于将单词进行排序和存储
Dictionary<string, int> keyValuePairs = new Dictionary<string, int>();
foreach (string word in wordList) {
if (keyValuePairs.ContainsKey(word))
{
keyValuePairs[word]++;
WordCount++;
}
else {
keyValuePairs[word] = 1;
WordCount++;
}
}
(2)、排序
var queryResults = from ni in result//字典序排序
orderby ni
select ni;
foreach (var item in queryResults)
{
resultWord += item.ToString()+"
";
}
这里使用的是.NET3.0提供的字典排序。
4、结果截图:
(1)、控制台结果截图:

(2)、output.txt文件输出截图。


七、单元测试结果
(1)初步测试
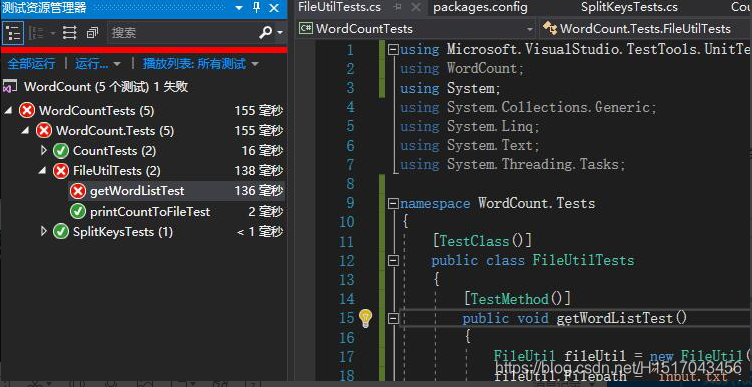
(2)、更据结果测试结果后更正后:

八、性能改进
本次性能分析,主要是从算法入手和设计入手。首先在初步完成项目后,我们就进行了一次项目性能分析,来查看哪里的优化效率和算法。
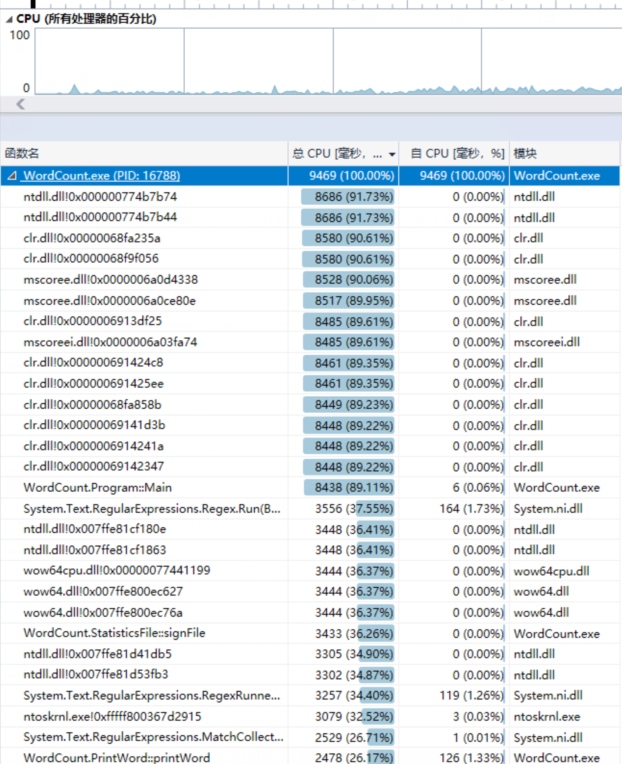
可见,当我们为了完成功能,将所有代码写到一起时,有的代码重复率十分高,消耗也大,耦合度也大。因此我们进行了相应的优化和改进。
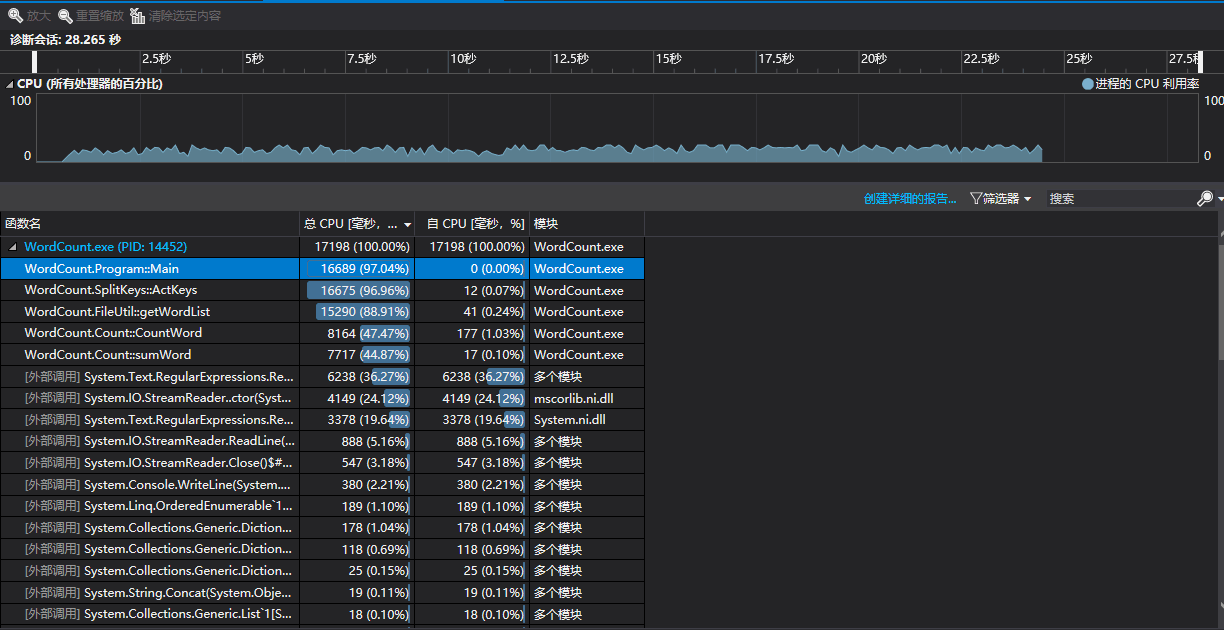
当我们将代码进行整理后,代码的重复率下降,耦合性降低,同时也通过注入对象的方式减少了类实例化的开销。
八、总结
本次结对编程,和自己的老搭档兼室友许自欢一起进行的。整个过程还算和和谐。他经常给我指出问题,当遇到问题时总是及时的给出一个解决方案。两个人去完成一个项目,无论是前期查阅相关资料还是后期的编码,都更加的快速和有效。当出现问题时,两个人一起解决,不同的思考方式总是想到很多方法,很快的将问题解决掉。结对编程刚开始时,的确有点不适应,一个人在编程的时候另外一个人有点迷惑不知道干嘛,因为不太习惯对方的编程方式和写法,但是到了后面熟悉后速度和效率就提高了。

九、关于性能分析的改进
根据邹老师的提问,我们更改了测试的方式拼接了10多本英文小说,获得了一个29411k的txt文件来测试,在这个测试文件中的字符数达到了:29437257个。

同时我们发现了消耗最大的方法是ActKeys()和getWordList(),前一个方法消耗很大应该是因为它作为一个指令调用的主要分发点,写了很多循环和判断,导致消耗很大。而后者这是读取文件并且判断统计字符数、函数和将分割的单词加入到链表中的方法,因此它开销很大,而后面几个的开销显著减小,是因为我们在getWordList()方法执行后返回给它们的是处理好的List,而这种数据结构减少了其他方法对于单词的处理消耗,同时我们用这种以一个很大的文件来测试程序性能的方式也体现了我们对性能改进的解决方案即将类实例化一次然后传给其他类使用的优点。