充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库
三大产品: JDBC、PROXY、SIDECAR
功能要点:
- 数据分片
- 单据单表的问题:B+树索引深度增加,磁盘io增多性能下降;高并发请求集中引发性能问题;不可伸缩;运维操作备份恢复等难度增大
- 核心流程:SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并
- 解析器:词法解析和语法解析,变更Druid -> 自研SQL半理解解析器,仅提炼分片关注上下文 -> ANTLR解析器
- 路由解析:
-
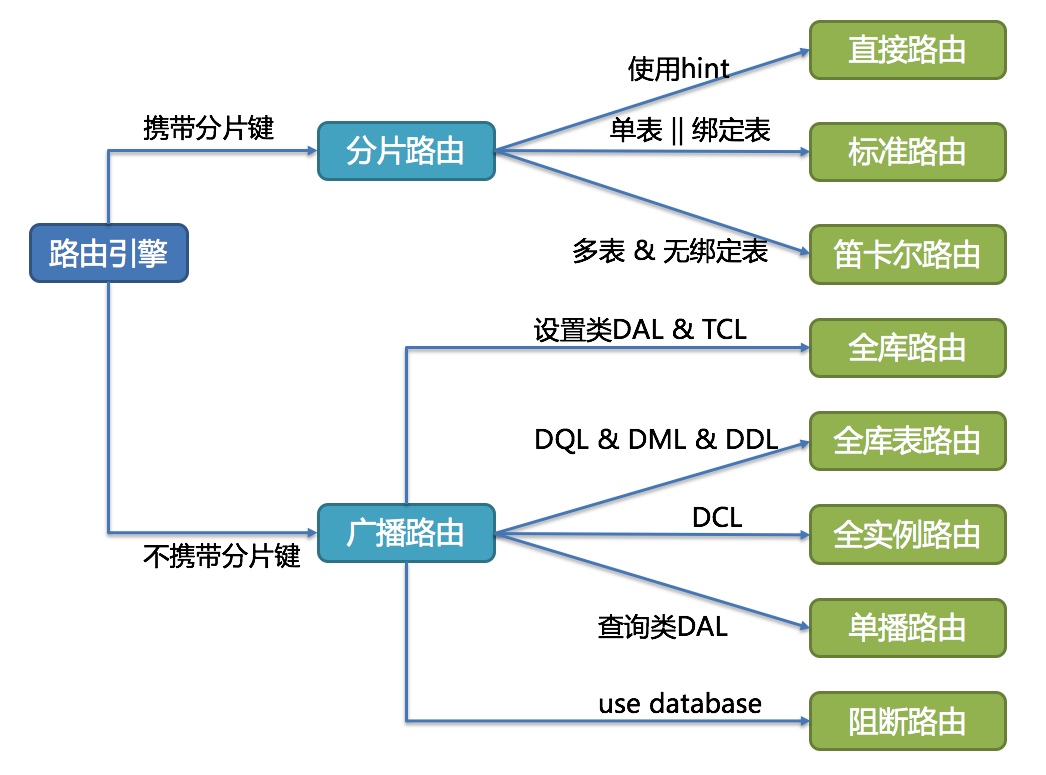
- 例: 全库路由(set autocommit =0)全实例路由(create user xxx@xxx identified by 'xx')单播路由(describe t_order);阻断路由(use order_db)
- 改写引擎:
- 正确性改写(分表表名改写,补列(结果归并时,需要根据
GROUP BY和ORDER BY的字段项进行分组和排序,但如果原始 SQL 的选择项中若并未包含分组项或排序项,则需要对原始 SQL 进行改写; avg聚合;insert自增主键),分页修正(1,2;0,3),批量拆分(insert多个,按库表拆分)) - 优化改写(单点优化(路由单点,不走任何合并逻辑),流式归并(以结果集游标下移进行结果归并))
- 正确性改写(分表表名改写,补列(结果归并时,需要根据
- 执行引擎
- 连接模式(连接模式(单一连接串行处理,多库情况每个库一个连接,这种情况下无法保存游标,只能走内存归并),内存限制模式(每张表一个连接并发处理,sql符合流式归并的就流式归并))
- 选择逻辑:在 maxConnectionSizePerQuery 允许的范围内,当一个连接需要执行的请求数量大于 1 时,意味着当前的数据库连接无法持有相应的数据结果集,则必须采用内存归并; 反之,当一个连接需要执行的请求数量等于 1 时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采用流式归并;在创建执行单元时,以原子性的方式一次性获取本次 SQL 请求所需的全部数据库连接,杜绝了每次查询请求获取到部分资源的可能,仅针对内存限制模式时才进行资源锁定。在使用连接限制模式时,所有的查询结果集将在装载至内存之后释放掉数据库连接资源,因此不会产生死锁等待的问题

- 归并引擎
- 从功能划分
- 遍历归并:多个数据集合并为一个单链表
- 排序归并:将每个结果集的当前值进行比较并放入优先级队列,每次获取下一条数据时只需要将队列顶端的结果集游标下移,并根据新游标重新进入优先级排序队列找到自己的位置
- 分组归并:流式分组归并要求 SQL 的排序项与分组项的字段以及排序类型(ASC 或 DESC)必须保持一致,否则只能通过内存归并才能保证其数据的正确性,流式分组跟上面差不多,区别是一次操作一组+聚合
- 分页归并: 除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此 ShardingSphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存;
- 聚合归并:max/min/sum/count/avg(sum+count)
- 从结构划分
- 流式归并
- 指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种
- 内存归并
- 需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回
- 装饰者归并
- 对所有的结果集归并进行统一的功能增强,目前装饰者归并有分页归并和聚合归并
- 流式归并
- 从功能划分
- 相关概念:
- 绑定表:关联表按照相同的规则路由,不产生关联查询时的笛卡尔关系,例:
t_order表和t_order_item表,均按照order_id分片 - 广播表:所有分片数据源中都存在且相同表结构,例小的字典表
- 绑定表:关联表按照相同的规则路由,不产生关联查询时的笛卡尔关系,例:
- 分布式事务
- XA协议两阶段提交
- Atomikos
- Bitronix
- Narayana
- Seata At
- XA协议两阶段提交
- 读写分离(一主多从)
- 同一线程且同一个库连接内,如果有一个写操作,则整体走主库
- 事务中走主库
- 分布式治理
- 数据源、规则、策略配置信息集中化、动态化 (zk/etcd/apollo/nacos...)
- 数据库状态、接入方服务动态管理(可操作zk节点进行从库禁用,实例熔断)
- 监控一体化 opentracing/skywalking
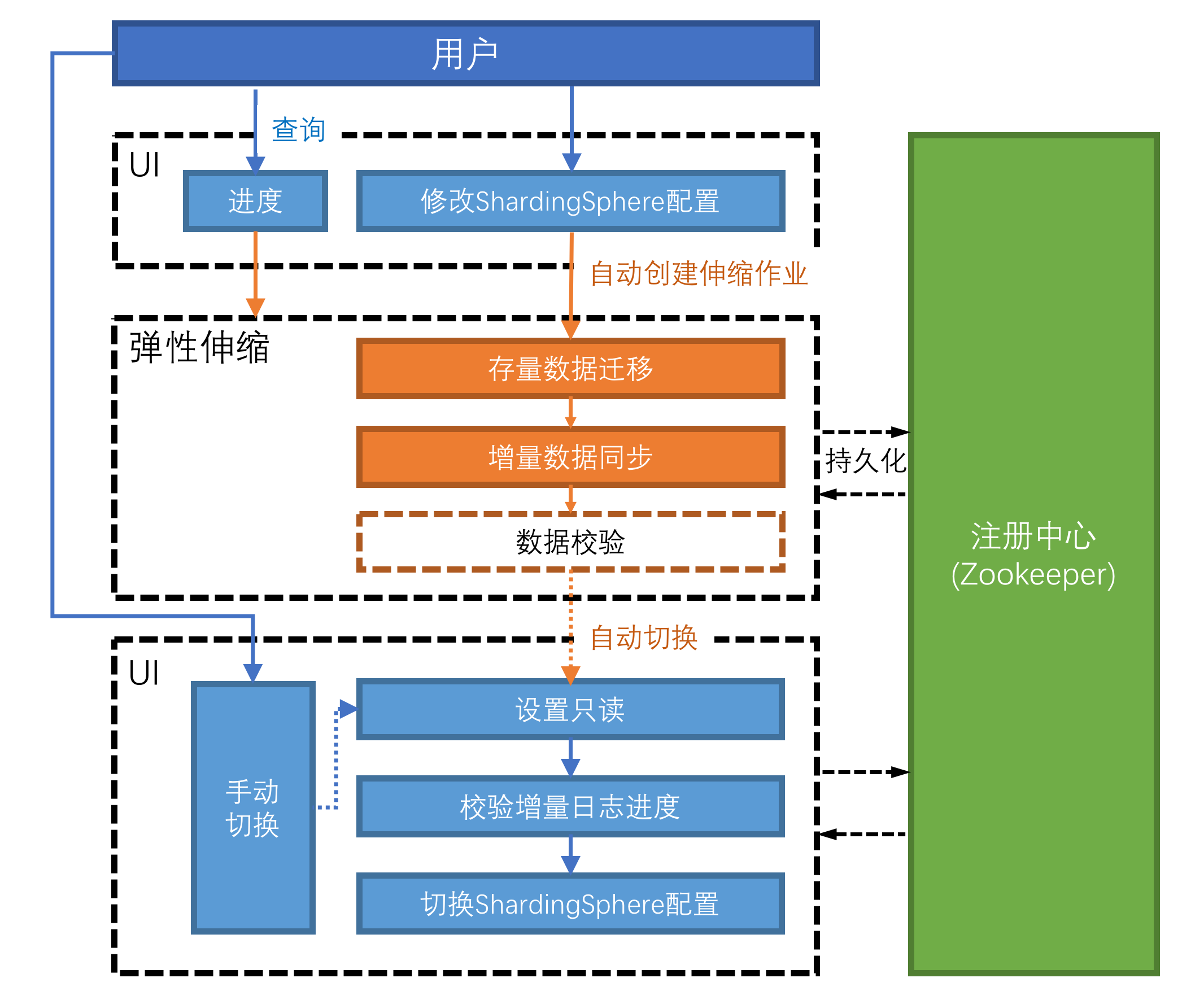
- 弹性伸缩
- 数据加密
- 对用户输入的 SQL 进行解析,并依据用户提供的加密规则对 SQL 进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。 在用户查询数据时,它仅从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户
- 哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行SQL编写(logicColumn)
- 影子压测
- 通过解析 SQL,根据配置文件中用户设置的影子规则,对传入的 SQL 进行路由并改写,删除影子字段与字段值
- Dist SQL 可以像操作数据库一样操作 Apache ShardingSphere,使其从面向开发人员的框架和中间件转变为面向运维人员的基础设施产品
- RDL(Resource & Rule Definition Language)负责资源和规则的创建、修改和删除
- RQL(Resource & Rule Query Language)负责资源和规则的查询和展现
- SCTL(ShardingSphere Control Language)负责Hint、事务类型切换、分片执行计划查询等增量功能的操作
- Other