ES - https://es.xiaoleilu.com/010_Intro/25_Tutorial_Indexing.html
这种类比让我对本来搜索的理解优点乱,稍微适应下
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
index/type/id -------不加ID自动生成生成
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
我们看到path:/megacorp/employee/1包含三部分信息:
| 名字 | 说明 |
|---|---|
| megacorp | 索引名 |
| employee | 类型名 |
| 1 | 这个员工的ID |
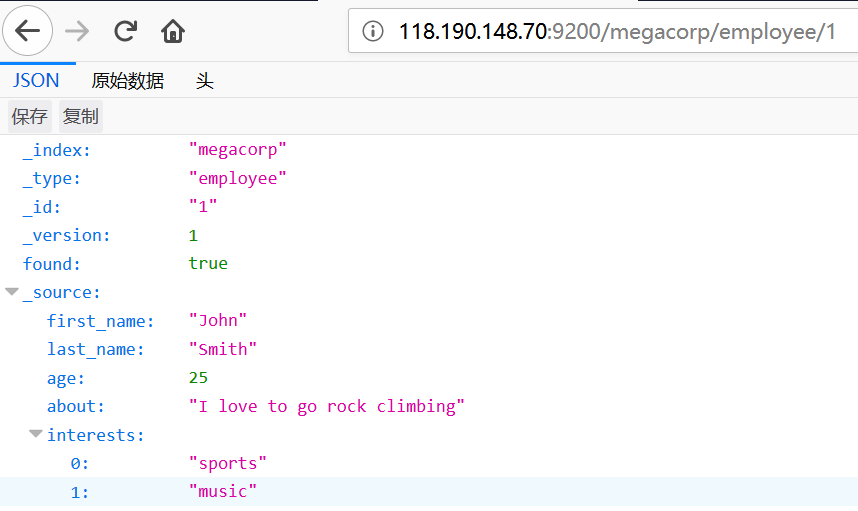
简单搜索 ?pretty是美化输出 / ?_source=first_name,about 查询某些字段 / /_source 只返回内容,不包含_index等字段 、 /_search?timeout=10ms
GET /megacorp/employee/_search?q=last_name:Smith
DSL搜索
GET /megacorp/employee/_search { "query" : { "match" : { "last_name" : "Smith" } } }
过滤器
GET /megacorp/employee/_search { "query" : { "filtered" : { "filter" : { "range" : { "age" : { "gt" : 30 } } }, "query" : { "match" : { "last_name" : "smith" } } } } }
全文检索、短语,高亮
GET /megacorp/employee/_search { "query" : { "match_phrase" : { "about" : "rock climbing" } }, "highlight": { "fields" : { "about" : {} } } }
聚合关系
GET /megacorp/employee/_search { "query": { "match": { "last_name": "smith" } }, "aggs": { "all_interests": { "terms": { "field": "age" } } } }
{ "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 0.2876821, "hits": [ { "_index": "megacorp", "_type": "employee", "_id": "2", "_score": 0.2876821, "_source": { "first_name": "Jane", "last_name": "Smith", "age": 32, "about": "I like to collect rock albums", "interests": [ "music" ] } }, { "_index": "megacorp", "_type": "employee", "_id": "1", "_score": 0.2876821, "_source": { "first_name": "John", "last_name": "Smith", "age": 25, "about": "I love to go rock climbing", "interests": [ "sports", "music" ] } } ] }, "aggregations": { "all_interests": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": 25, "doc_count": 1 }, { "key": 32, "doc_count": 1 } ] } } }
平均
"aggs" : { "avg_age" : { "avg" : { "field" : "age" } } }
集群
集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。任何节点都可以成为主节点。
做为用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
集群健康度分为
| 颜色 | 意义 |
|---|---|
green |
所有主要分片和复制分片都可用 |
yellow |
所有主要分片可用,但不是所有复制分片都可用 |
red |
不是所有的主要分片都可用 |
GET /_cluster/health
索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
分片可以是主分片(primary shard)或者是复制分片(replica shard)。你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
http://118.190.148.70:9200/megacorp/_settings
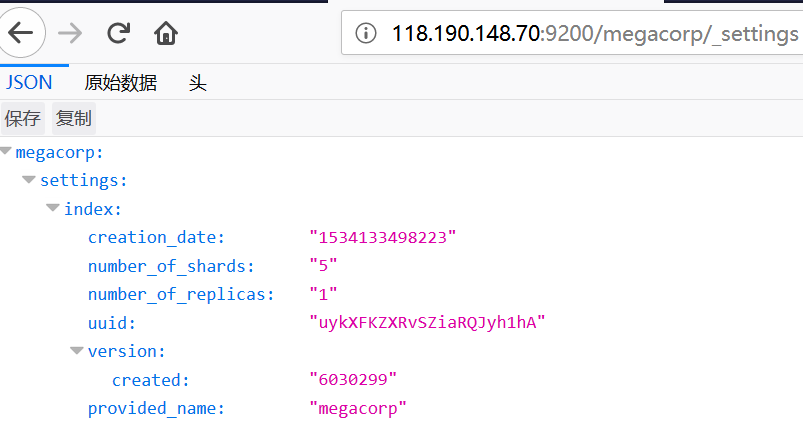
| 节点 | 说明 |
|---|---|
_index |
文档存储的地方 |
_type |
文档代表的对象的类 |
_id |
文档的唯一标识 |
批量
_bulk mget
复制策略
复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。
如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
/gb,us/user,tweet/_search
在索引gb和us的类型为user和tweet中搜索
/_all/user,tweet/_search
在所有索引的user和tweet中搜索 search types user and tweet in all indices
/_search?size=5&from=10
查询所有类型为tweet并在tweet字段中包含elasticsearch字符的文档:
GET /_all/tweet/_search?q=tweet:elasticsearch
下一个语句查找name字段中包含"john"和tweet字段包含"mary"的结果。实际的查询只需要:
+name:john +tweet:mary
返回包含"mary"字符的所有文档的简单搜索:
GET /_search?q=mary
_all field
name字段包含"mary"或"john"date晚于2014-09-10_all字段包含"aggregations"或"geo"
+name:(mary john) +date:>2014-09-10 +(aggregations geo)
Elasticsearch为对字段类型进行猜测,动态生成了字段和类型的映射关系。返回的信息显示了date字段被识别为date类型。_all因为是默认字段所以没有在此显示,不过我们知道它是string类型。
组合查询
{ "bool": { "must": { "match": { "email": "business opportunity" }}, "should": [ { "match": { "starred": true }}, { "bool": { "must": { "folder": "inbox" }}, "must_not": { "spam": true }} }} ], "minimum_should_match": 1 } }
{ "terms": { "tag": [ "search", "full_text", "nosql" ] } }
{ "range": { "age": { "gte": 20, "lt": 30 } } }
{ "bool": { "must": { "term": { "folder": "inbox" }}, "must_not": { "term": { "tag": "spam" }}, "should": [ { "term": { "starred": true }}, { "term": { "unread": true }} ] } }
{ "multi_match": { "query": "full text search", "fields": [ "title", "body" ] } }
{ "bool": { "must": { "match": { "title": "how to make millions" }}, "must_not": { "match": { "tag": "spam" }}, "should": [ { "match": { "tag": "starred" }}, { "range": { "date": { "gte": "2014-01-01" }}} ] } }
GET /_search { "query": { "filtered": { "filter": { "bool": { "must": { "term": { "folder": "inbox" }}, "must_not": { "query": { <1> "match": { "email": "urgent business proposal" } } } } } } } }
GET /_search { "query" : { "filtered" : { "filter" : { "term" : { "user_id" : 1 }} } }, "sort": { "date": { "order": "desc" }} }
GET /_search?sort=date:desc&sort=_score&q=search
PUT /my_index { "settings": { "analysis": { "char_filter": { "&_to_and": { "type": "mapping", "mappings": [ "&=> and "] }}, "filter": { "my_stopwords": { "type": "stop", "stopwords": [ "the", "a" ] }}, "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "html_strip", "&_to_and" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stopwords" ] }} }}}
GET /my_index/my_type/_search { "query": { "match": { "title": { "query": "quick brown dog", "minimum_should_match": "75%" } } } }
GET /my_index/my_type/_search { "query": { "bool": { "should": [ { "match": { "title": "brown" }}, { "match": { "title": "fox" }}, { "match": { "title": "dog" }} ], "minimum_should_match": 2 <1> } } }
GET /_search { "query": { "bool": { "should": [ { "match": { <1> "title": { "query": "War and Peace", "boost": 2 }}}, { "match": { <1> "author": { "query": "Leo Tolstoy", "boost": 2 }}}, { "bool": { <2> "should": [ { "match": { "translator": "Constance Garnett" }}, { "match": { "translator": "Louise Maude" }} ] }} ] } } }
dis_max查询(Disjuction Max Query)。Disjuction的意思"OR"(而Conjunction的意思是"AND"),因此Disjuction Max Query的意思就是返回匹配了任何查询的文档,并且分值是产生了最佳匹配的查询所对应的分值
{ "query": { "dis_max": { "queries": [ { "match": { "title": "Brown fox" }}, { "match": { "body": "Brown fox" }} ] } } }
tie_breaker参数会让dis_max查询的行为更像是dis_max和bool的一种折中。它会通过下面的方式改变分值计算过程:
- 1.取得最佳匹配查询子句的_score。
- 2.将其它每个匹配的子句的分值乘以tie_breaker。
- 3.将以上得到的分值进行累加并规范化。
通过tie_breaker参数,所有匹配的子句都会起作用,只不过最佳匹配子句的作用更大。
提示:tie_breaker的取值范围是0到1之间的浮点数,取0时即为仅使用最佳匹配子句(译注:和不使用tie_breaker参数的dis_max查询效果相同),取1则会将所有匹配的子句一视同仁。它的确切值需要根据你的数据和查询进行调整,但是一个合理的值会靠近0,(比如,0.1 -0.4),来确保不会压倒dis_max查询具有的最佳匹配性质。
{ "multi_match": { "query": "Quick brown fox", "type": "best_fields", <1> "fields": [ "title", "body" ], "tie_breaker": 0.3, "minimum_should_match": "30%" <2> } }
{ "multi_match": { "query": "Quick brown fox", "fields": [ "*_title", "chapter_title^2" ] <1> } }
GET /my_store/_analyze { "field": "productID", "text": "XHDK-A-1293-#fJ3" }
best_fields 、 most_fields 和 cross_fields (最佳字段、多数字段、跨字段)。
From:
{ "dis_max": { "queries": [ { "match": { "title": { "query": "Quick brown fox", "minimum_should_match": "30%" } } }, { "match": { "body": { "query": "Quick brown fox", "minimum_should_match": "30%" } } }, ], "tie_breaker": 0.3 } }
To:
{ "multi_match": { "query": "Quick brown fox", "type": "best_fields", "fields": [ "title", "body" ], "tie_breaker": 0.3, "minimum_should_match": "30%" } }
GET /my_index/address/_search { "query": { "regexp": { "postcode": "W[0-9].+" } } }