1. 前言
在博客里介绍了ShuffleWrite关于shuffleMapTask如何运行,输出Shuffle结果到Shuffle_shuffleId_mapId_0.data数据文件中,每个executor需要向Driver汇报当前节点的Shuffle结果状态,Driver保存结果信息进行下个Task的调度。
2. StatusUpdate消息
当Executor运行完Task的时候需要向Driver汇报StatusUpdate的消息
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) { val msg = StatusUpdate(executorId, taskId, state, data) driver match { case Some(driverRef) => driverRef.send(msg) case None => logWarning(s"Drop $msg because has not yet connected to driver") } }
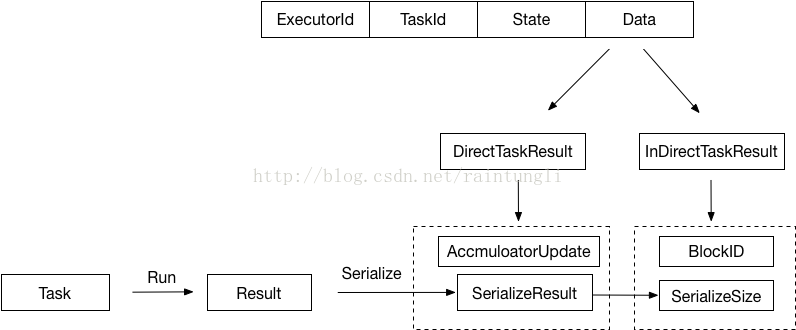
整个结构体中包含了
- ExecutorId: Executor自己的ID
- TaskId: task分配的ID
- State: Task的运行状态
LAUNCHING, RUNNING, FINISHED, FAILED, KILLED, LOST
- Data: 保存序列化的Result
2.1 Executor端发送
在Task运行后的结果,Executor会将结果首先序列化成ByteBuffer封装成DirectTaskResult,再次序列化DirectTaskResult成ByteBuffer,很显然序列化的结果的大小会决定不同的传递策略。在这里会有两个筏值来控制
- 最大的返回结果大小,如果超过设定的最大返回结果时,返回的结果内容会被丢弃,只是返回序列化的InDirectTaskResult,里面包含着BlockID和序列化后的结果大小
spark.driver.maxResultSize
- 最大的直接返回结果大小:如果返回的结果大于最大的直接返回结果大小,小于最大的返回结果大小,采用了保存的折中的策略,将序列化DirectTaskResult保存到BlockManager中,关于BlockManager可以参考前面写的BlockManager系列,返回InDirectTaskResult,里面包含着BlockID和序列化的结果大小
spark.task.maxDirectResultSize
- 直接返回:如果返回的结果小于等于最大的直接返回结果大小,将直接将序列化的DirectTaskResult返回给Driver端
val serializedResult: ByteBuffer = { if (maxResultSize > 0 && resultSize > maxResultSize) { logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " + s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " + s"dropping it.") ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize)) } else if (resultSize > maxDirectResultSize) { val blockId = TaskResultBlockId(taskId) env.blockManager.putBytes( blockId, new ChunkedByteBuffer(serializedDirectResult.duplicate()), StorageLevel.MEMORY_AND_DISK_SER) logInfo( s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)") ser.serialize(new IndirectTaskResult[Any](blockId, resultSize)) } else { logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver") serializedDirectResult } }
2.2 Driver端接收
Driver端处理StatusUpdate的消息的代码如下:
case StatusUpdate(executorId, taskId, state, data) => scheduler.statusUpdate(taskId, state, data.value) if (TaskState.isFinished(state)) { executorDataMap.get(executorId) match { case Some(executorInfo) => executorInfo.freeCores += scheduler.CPUS_PER_TASK makeOffers(executorId) case None => // Ignoring the update since we don't know about the executor. logWarning(s"Ignored task status update ($taskId state $state) " + s"from unknown executor with ID $executorId") } }
scheduler实例是TaskSchedulerImpl.scala
if (TaskState.isFinished(state)) { cleanupTaskState(tid) taskSet.removeRunningTask(tid) if (state == TaskState.FINISHED) { taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData) } else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) { taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData) } }
statusUpdate函数调用了enqueueSuccessfulTask方法
def enqueueSuccessfulTask( taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer): Unit = { getTaskResultExecutor.execute(new Runnable { override def run(): Unit = Utils.logUncaughtExceptions { try { val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match { case directResult: DirectTaskResult[_] => if (!taskSetManager.canFetchMoreResults(serializedData.limit())) { return } // deserialize "value" without holding any lock so that it won't block other threads. // We should call it here, so that when it's called again in // "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value. directResult.value(taskResultSerializer.get()) (directResult, serializedData.limit()) case IndirectTaskResult(blockId, size) => if (!taskSetManager.canFetchMoreResults(size)) { // dropped by executor if size is larger than maxResultSize sparkEnv.blockManager.master.removeBlock(blockId) return } logDebug("Fetching indirect task result for TID %s".format(tid)) scheduler.handleTaskGettingResult(taskSetManager, tid) val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) if (!serializedTaskResult.isDefined) { /* We won't be able to get the task result if the machine that ran the task failed * between when the task ended and when we tried to fetch the result, or if the * block manager had to flush the result. */ scheduler.handleFailedTask( taskSetManager, tid, TaskState.FINISHED, TaskResultLost) return } val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]]( serializedTaskResult.get.toByteBuffer) // force deserialization of referenced value deserializedResult.value(taskResultSerializer.get()) sparkEnv.blockManager.master.removeBlock(blockId) (deserializedResult, size) } // Set the task result size in the accumulator updates received from the executors. // We need to do this here on the driver because if we did this on the executors then // we would have to serialize the result again after updating the size. result.accumUpdates = result.accumUpdates.map { a => if (a.name == Some(InternalAccumulator.RESULT_SIZE)) { val acc = a.asInstanceOf[LongAccumulator] assert(acc.sum == 0L, "task result size should not have been set on the executors") acc.setValue(size.toLong) acc } else { a } } scheduler.handleSuccessfulTask(taskSetManager, tid, result) } catch { case cnf: ClassNotFoundException => val loader = Thread.currentThread.getContextClassLoader taskSetManager.abort("ClassNotFound with classloader: " + loader) // Matching NonFatal so we don't catch the ControlThrowable from the "return" above. case NonFatal(ex) => logError("Exception while getting task result", ex) taskSetManager.abort("Exception while getting task result: %s".format(ex)) } } }) }
在函数中,反序列化的过程是通过线程池里的线程来运行的,Netty的接收数据线程是不能被堵塞(同时还接受着别的消息),反序列化是耗时的任务,不能在Netty的消息处理线程中运行。
2.2.1 DirectTaskResult处理过程
- 直接反序列化成DirectTaskResult,反序列化后进行了整体返回内容的大小的判断,在前面的2.1中介绍参数:spark.driver.maxResultSize,这个参数是Driver端的参数控制的,在Spark中会启动多个Task,参数的控制是一个整体的控制所有的Tasks的返回结果的数量大小,当然单个task使用该筏值的控制也是没有问题,因为只要有一个任务返回的结果超过maxResultSize,整体返回的数据也会超过maxResultSize。
- 对DirectTaskResult里的result进行了反序列化。
2.2.2 InDirectTaskResult处理过程
- 通过size判断大小是否超过spark.driver.maxResultSize筏值控制
- 通过BlockManager来获取BlockID的内容反序列化成DirectTaskResult
- 对DirectTaskResult里的result进行了反序列化
最后调用handleSuccessfulTask方法
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info)
回到了Dag的调度,向eventProcessLoop的队列里提交了CompletionEvent的事件
def taskEnded( task: Task[_], reason: TaskEndReason, result: Any, accumUpdates: Seq[AccumulatorV2[_, _]], taskInfo: TaskInfo): Unit = { eventProcessLoop.post( CompletionEvent(task, reason, result, accumUpdates, taskInfo)) }
处理eventProcessLoop队列的event是在DAG的线程处理的,在这里我们不讨论DAG的任务调度。
2.3 MapOutputTracker
MapOutputTracker是当运行完ShuffleMapTask的时候,ShuffleWrite会生成Shuffle_shuffleId_mapId_0.data、index文件,Executor需要将具体的信息返回给Driver,当Driver进行下一步的Task运算的时候,Executor也需要获取具体Shuffle数据文件的信息进行下一步的action算子的运算,结构的保存、管理就是通过MapOutputTracker跟踪器进行追踪的。

2.3.1 RegisterMapOutput
Execute端
在ShuffleMapTask中运行后会生成一个MapStatus,也就是上图的Map0结构,ComressedMapStatus、HighlyCompressedMapStatus这里的两个区别主要是增对Partition1...的size long的压缩,但这里的压缩算法并不准确比,如CompressedMapStatus的算法:
def compressSize(size: Long): Byte = { if (size == 0) { 0 } else if (size <= 1L) { 1 } else { math.min(255, math.ceil(math.log(size) / math.log(LOG_BASE)).toInt).toByte } }
求Log1.1(size)的整数转为byte,也就是支持最大1.1^255=35G左右
为何不需要计算精准的尺寸?
还记得前面博客里提到的Shuffle_shuffleId_mapId_reduceId.index文件么,这里才是精准的位置,当读取本地文件的时候,并不使用MapStatus里的Size
Size有何用?
有存在别的Execute获取别的Execute的Shuffle结果文件,此时的size是获取文件的大概位置。
MapStatus是ShuffleMapTask运行的结果,被序列化成DirectTaskResult中的value,通过StatusUpdate消息传递
Driver端
DAG线程调度处理CompletionEvent的事件
private[scheduler] def handleTaskCompletion(event: CompletionEvent) { ............ case smt: ShuffleMapTask => val shuffleStage = stage.asInstanceOf[ShuffleMapStage] updateAccumulators(event) val status = event.result.asInstanceOf[MapStatus] val execId = status.location.executorId logDebug("ShuffleMapTask finished on " + execId) if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) { logInfo(s"Ignoring possibly bogus $smt completion from executor $execId") } else { shuffleStage.addOutputLoc(smt.partitionId, status) } if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) { markStageAsFinished(shuffleStage) logInfo("looking for newly runnable stages") logInfo("running: " + runningStages) logInfo("waiting: " + waitingStages) logInfo("failed: " + failedStages) // We supply true to increment the epoch number here in case this is a // recomputation of the map outputs. In that case, some nodes may have cached // locations with holes (from when we detected the error) and will need the // epoch incremented to refetch them. // TODO: Only increment the epoch number if this is not the first time // we registered these map outputs. mapOutputTracker.registerMapOutputs( shuffleStage.shuffleDep.shuffleId, shuffleStage.outputLocInMapOutputTrackerFormat(), changeEpoch = true) clearCacheLocs() if (!shuffleStage.isAvailable) { // Some tasks had failed; let's resubmit this shuffleStage // TODO: Lower-level scheduler should also deal with this logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name + ") because some of its tasks had failed: " + shuffleStage.findMissingPartitions().mkString(", ")) submitStage(shuffleStage) } else { // Mark any map-stage jobs waiting on this stage as finished if (shuffleStage.mapStageJobs.nonEmpty) { val stats = mapOutputTracker.getStatistics(shuffleStage.shuffleDep) for (job <- shuffleStage.mapStageJobs) { markMapStageJobAsFinished(job, stats) } } submitWaitingChildStages(shuffleStage) } }
当处理shuffleMapTask的结果的时候,mapOutputTracker.registerMapOutputs进行了MapOutputs的注册
protected val mapStatuses = new ConcurrentHashMap[Int, Array[MapStatus]]().asScala def registerMapOutputs(shuffleId: Int, statuses: Array[MapStatus], changeEpoch: Boolean = false) { mapStatuses.put(shuffleId, statuses.clone()) if (changeEpoch) { incrementEpoch() } }
在Driver端保存了一个Map是以ShuffldId为Key的MapStatus的数组
2.3.2 获取MapStatus
在ResultTask中,通过获取反序列化的ShuffledRDD,在Fetch Shuffle数据文件的时候
val blockFetcherItr = new ShuffleBlockFetcherIterator( context, blockManager.shuffleClient, blockManager, mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition), // Note: we use getSizeAsMb when no suffix is provided for backwards compatibility SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024, SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
通过getMapSizesByExecutorId获取ShuffledId所对应的MapStatus
def getMapSizesByExecutorId(shuffleId: Int, startPartition: Int, endPartition: Int) : Seq[(BlockManagerId, Seq[(BlockId, Long)])] = { logDebug(s"Fetching outputs for shuffle $shuffleId, partitions $startPartition-$endPartition") val statuses = getStatuses(shuffleId) // Synchronize on the returned array because, on the driver, it gets mutated in place statuses.synchronized { return MapOutputTracker.convertMapStatuses(shuffleId, startPartition, endPartition, statuses) } }
在getStatuses方法中
private def getStatuses(shuffleId: Int): Array[MapStatus] = { val statuses = mapStatuses.get(shuffleId).orNull if (statuses == null) { logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them") val startTime = System.currentTimeMillis var fetchedStatuses: Array[MapStatus] = null fetching.synchronized { // Someone else is fetching it; wait for them to be done while (fetching.contains(shuffleId)) { try { fetching.wait() } catch { case e: InterruptedException => } } // Either while we waited the fetch happened successfully, or // someone fetched it in between the get and the fetching.synchronized. fetchedStatuses = mapStatuses.get(shuffleId).orNull if (fetchedStatuses == null) { // We have to do the fetch, get others to wait for us. fetching += shuffleId } } if (fetchedStatuses == null) { // We won the race to fetch the statuses; do so logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint) // This try-finally prevents hangs due to timeouts: try { val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId)) fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes) logInfo("Got the output locations") mapStatuses.put(shuffleId, fetchedStatuses) } finally { fetching.synchronized { fetching -= shuffleId fetching.notifyAll() } } } logDebug(s"Fetching map output statuses for shuffle $shuffleId took " + s"${System.currentTimeMillis - startTime} ms") if (fetchedStatuses != null) { return fetchedStatuses } else { logError("Missing all output locations for shuffle " + shuffleId) throw new MetadataFetchFailedException( shuffleId, -1, "Missing all output locations for shuffle " + shuffleId) } } else { return statuses } }
- 封装了一层缓存mapStatus,对同一个Executor来说,里面的线程都是运行同一个Driver的提交的任务,对相同的shuffeID,MapStatus是一样的
- 对同一个Executor、ShuffeID来说,通过Driver获取信息只需要一次,Driver里保存的Shuffle的结果是单点的,对同一个Executor来说获取同一个ShuffleID只需要请求一次,在Traker里面保存了一个队列fetching,里面保存的ShuffeID代表的是有线程正在从Driver端获取ShuffleID的MapStatus,如果发现有值,当前线程会等待,直到其他的线程获取ShuffleID状态并保存到缓存结束,当前线程直接从缓存中获取当前状态
- Executor 向Driver发送GetMapOutputStatuses(shuffleId)消息
- Driver收到GetMapOutputStatuses消息后保存到消息队列mapOutputRequests,Map-Output-Dispatcher-x多线程处理消息队列,返回序列化的MapStatus
- Executor反序列化成MapStatus
2.2.3 以BlockManagerId为key的Shuffle的序列
在前面的博客里提到过Driver分配Task的数量的策略是依赖于Partition,在单个任务ShuffledMapTask对Data进行分片也是依赖于Partition
前面一个的Partition 是MapId,后面一个Partition 指的是ReduceId
在ResultTask里所取的Shuffle数据文件中的Partition是ReduceId,而不是MapId

也就是每个ResultTask会去获取所有不同的MapId中相同的PartitionID部分Shuffle文件,而不是继续按前面的Map进行分配,那意味着ResultTask将会去获取所有Shuffle文件
Shuffle_shuffleId_mapId_0.data中的Partition那部分进行Action操作,这样可以适当避免在ShuffledMapTask中分配的数据不均衡,导致单个Shuffle_shuffleId_mapId_0.data文件数据过大的问题。
具体的代码实现如下:
private def convertMapStatuses( shuffleId: Int, startPartition: Int, endPartition: Int, statuses: Array[MapStatus]): Seq[(BlockManagerId, Seq[(BlockId, Long)])] = { assert (statuses != null) val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(BlockId, Long)]] for ((status, mapId) <- statuses.zipWithIndex) { if (status == null) { val errorMessage = s"Missing an output location for shuffle $shuffleId" logError(errorMessage) throw new MetadataFetchFailedException(shuffleId, startPartition, errorMessage) } else { for (part <- startPartition until endPartition) { splitsByAddress.getOrElseUpdate(status.location, ArrayBuffer()) += ((ShuffleBlockId(shuffleId, mapId, part), status.getSizeForBlock(part))) } } } splitsByAddress.toSeq }