Memcached介绍
Memcached是什么?
Free & open source, high-performance, distributed memory object caching system(自由&开放源码,高性能,分布式的内存对象缓存系统)
。由LiveJournal旗下的danga公司开发的老牌nosql应用。
什么是NoSQL?
NoSQL,指的是菲关系型的数据库。
相对于传统关系型数据库的"行与列",NoSQL的鲜明特点为key-value存储(memcache,redis),或基于文档存储(mongodb)。
注:nosql --not only sql,不仅仅是关系型数据库
Memcached安装
Linux下编译Memcached
准备编译环境
再Linux下编译,需要gcc,make,cmake,autoconf,libtool等工具,这几件工具,以后还要编译redis等使用,所以需要先安装。在Linux系统联网后,用如下命令安装
yum install gcc gcc-c++ make cmake autoconf libtool
编译Memcached
Memcached依赖于libevent库,因此我们需要先安装libevent。分别到libevent.org和memcached.org下载最新的stable版本(稳定版)。
先编译libevent,再编译memcached。
编译Memcached时要指定libevent的路径。
过程如下:假设源码在/root/package下,安装在/usr/local下
tar zxvf libevent-2.1.8-stable.tar.gz
cd libevent-2.1.8-stable
./configure --prefix=/usr/local/libevent
make && make install
安装memcached
tar zxvf memcached-1.5.1.tar.gz
cd memcached-1.5.1
./configure --prefix=/usr/local/memcached --with-libevent=/usr/local/libevent/
make && make install
配置环境变量
vi /etc/profile
export PATH="$PATH:/usr/local/memcached/bin"
source /etc/profile
创建memcached用户
useradd memcached
设置开机自动启动:
vi /etc/rc.local
增加
/usr/local/memcached/bin/memcached -u memcached -m 64 &
PHP安装Memcached扩展
http://pecl.php.net/package/memcache下载扩展包
wget https://pecl.php.net/get/memcache-2.2.7.tgz
tar zxvf memcache-2.2.7.tgz
cd memcache-2.2.7
phpize //执行phpize命令,phpize是PHP的工具,用来将PHP的扩展与PHP程序建立关联
配置编译安装
./configure && make && make install
修改php.ini
vi /usr/local/php/lib/php.ini
在大约928行左右加上扩展配置
;linux extension load
extension=memcache.so
重启Apache
apachectl -k restart
在phpinfo里可以查找到memcache说明安装成功
Memcached的启动
memcached -m 64 -p 11211 -u nobody -d //-d表示后台运行(也可以用&)
可以使用memcached -h查看帮助来了解各个参数的意义。
| 选项 | 含义说明 |
|---|---|
| -p, --port= |
TCP port to listen on (default: 11211)Memcached监听的端口,要保证该端口号未被占用 |
| -U, --udp-port= |
UDP port to listen on (default: 11211, 0 is off)指定监听UDP的端口,默认11211,0表示关闭 |
| -s, --unix-socket= |
指定Memcached用于监听的UNIX socket文件 |
| -A, --enable-shutdown | |
| -a, --unix-mask= |
设置-s选项指定的UNIX socket文件的权限 |
| -l, --listen= |
监听的服务器IP地址,如果有多个地址的话,使用逗号分隔,格式可以为“IP地址:端口号”,例如:-l 指定192.168.0.184:19830,192.168.0.195:13542;端口号也可以通过-p选项指定 |
| -d, --daemon | run as a daemon(指定memcached进程作为一个守护进程启动) |
| -r, --enable-coredumps | 设置产生core文件大小 |
| -u, --user= |
assume identity of |
| -m, --memory-limit= |
item memory in megabytes (default: 64 MB)指定分配给memcached使用的内存,单位是MB(默认是64M) |
| -M, --disable-evictions | 当内存使用超出配置值时,禁止自动清除缓存中的数据项,此时Memcached不可以,直到内存被释放 |
| -c, --conn-limit= |
max simultaneous connections (default: 1024)设置最大运行的并发连接数,默认是1024 |
| -k, --lock-memory | 设置锁定所有分页的内存,对于大缓存应用场景,谨慎使用该选项 |
| -v, --verbose | 输出警告和错误信息 |
| -vv | 打印信息比-v更详细:不仅输出警告和错误信息,也输出客户端请求和响应信息 |
| -vvv | |
| -h, --help | 查看帮助 |
| -i, --license | 打印libevent和Memcached的licenses信息 |
| -V, --version | |
| -P, --pidfile= |
保存memcached进程的pid文件 |
| -f, --slab-growth-factor= |
用于计算缓存数据项的内存块大小的乘数因子,默认是1.25 |
| -n, --slab-min-size= |
为缓存数据项的key、value、flag设置最小分配字节数,默认是48 |
| -L, --enable-largepages | 尝试使用大内存分页(pages) |
| -D |
用于统计报告中Key前缀和ID之间的分隔符,默认是冒号“:” |
| -t, --threads= |
指定用来处理请求的线程数,默认为4 |
| -R, --max-reqs-per-event | 为避免客户端饿死(starvation),对连续达到的客户端请求数设置一个限额,如果超过该设置,会选择另一个连接来处理请求,默认为20 |
| -C, --disable-cas | 禁用CAS |
| -b, --listen-backlog= |
|
| -B, --protocol= |
指定使用的协议,默认行为是自动协商(autonegotiate),可能使用的选项有auto、ascii、binary。 |
| -I, --max-item-size= |
覆盖默认的STAB页大小,默认是1M |
| -F, --disable-flush-all | 禁用flush_all命令 |
| -X, --disable-dumping | |
| -o, --extended | 指定逗号分隔的选项,一般用于用于扩展或实验性质的选项 |
Memcached基本使用
PHP操作Memcache
| 方法 | 方法说明 |
|---|---|
| connect() | 打开一个memcached服务端连接 |
| add() | 增加一个条目到缓存服务器 |
| addServer() | 向连接池中添加一个memcache服务器 |
| increment() | 增加一个元素的值 |
| decrement() | 减小一个元素的值 |
| delete() | 从服务端删除一个元素 |
| flush() | 清洗(删除)已经存储的所有的元素 |
| get() | 从服务端检回一个元素 |
| set() | 保存数据到缓存服务器 |
| replace() | 替换已经存在的元素的值 |
| pconnect() | 打开一个到服务器的持久化连接 |
| close() | 关闭memcache连接 |
PHP连接memcache服务
$memcache = new Memcache();
$memcache->connect("192.168.20.131", 11211);
bool Memcache::set (string $key , mixed $var [, int $flag [, int $expire ]])
$key:要设置值的key
$var:要存储的值,字符串和数值直接存储,其他类型序列化后存储。数据的最大长度为1M。
$flag: 使用MEMCACHE_COMPRESSED指定对值进行压缩(使用zlib)。通常传入0即可,表示不需要压缩。
$expire:当前写入缓存的数据的失效时间。如果此值设置为0表明此数据永不过期。当时间小于30天时表示的是时间间隔,当时间大于30天表示时间戳
bool Memcache::add (string $key , mixed $var [, int $flag [, int $expire ]])
说明:与set类似,仅仅可以执行添加操作,不能执行修改操作,当key已经存在时,则add失败
bool Memcache::replace (string $key , mixed $var [, int $flag [, int $expire ]])
说明:与set类似,仅仅可以执行替换操作,仅仅在key存在时才可以执行,当key不存在时,替换是失败的
get($key [, $flag]) --- 获取
获取时, 有时需要设置第二个参数, flag标志!
比如如果存储时设置了第二个参数为压缩存储,那么获取时也需要传递压缩存储的参数。
increment($key, $num) --- 递增
在原有值得基础上增加,第二个参数不写默认是1
decrement($key, $num) --- 递减
在原有值得基础减少,
delete($key) --- 删除
fulsh() --- 清空/刷新
close() --- 关闭连接
Memcached的内存管理与删除机制
内存的碎片化
如果用 c 语言直接 malloc, free 来向操作系统申请和释放内存时,在不断的申请和释放过程中,形成了一些很小的内存片断,无法再利用。这种空闲,但无法利用内存的现象,--称为内存的碎片化。
slab allocator缓解内存碎片化
Memcached 用 slab allocator 机制来管理内存。
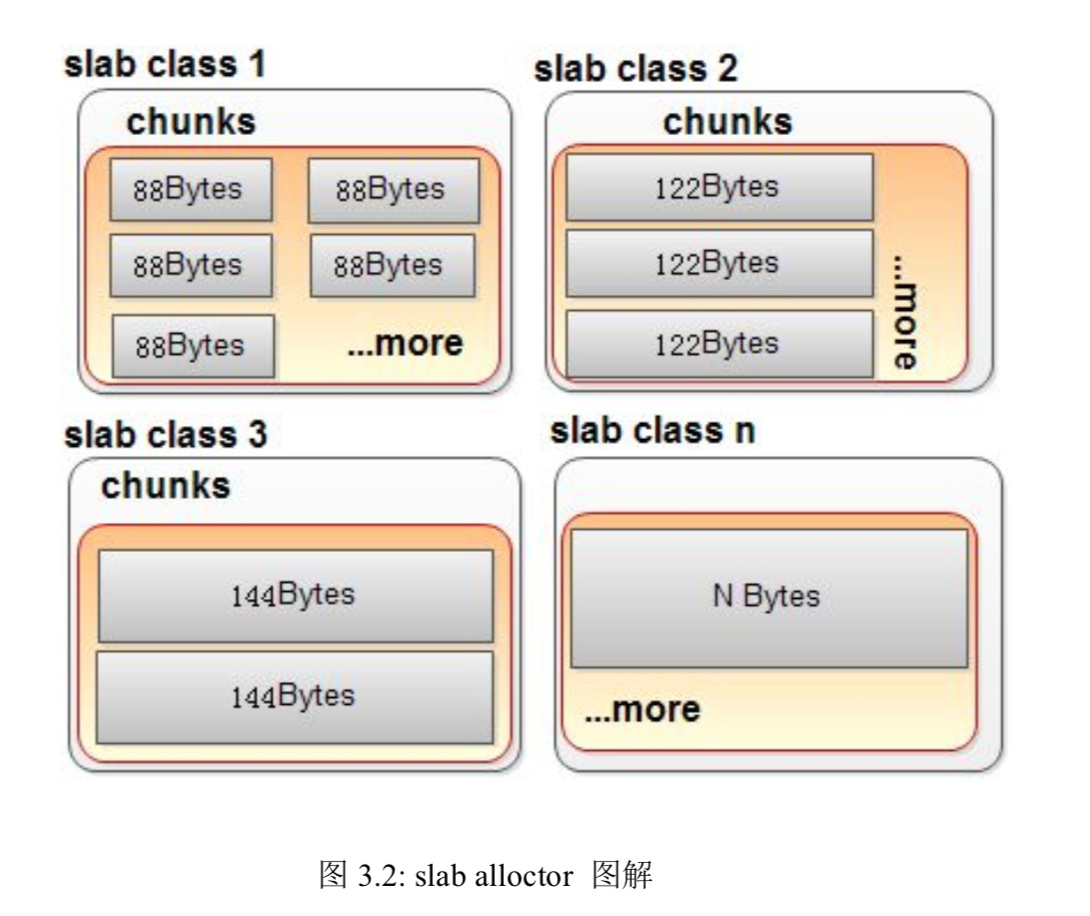
Slab allocator 原理:预告把内存划分成数个 slab cl ass 仓库。(每个 slab class 大小 1 M)各仓库,切分成不同尺时的小块(chunk).(图 3.2)
需要存内容时,判断内容的大小,为其选取合理的仓库.
系统如何选择合适的chunk?
Memcached 根据收到的数据的大小,选择最适合数据大小的 chunk 组(slab class)(图 3.3)。memcached 中保存着 slab class 内空闲 chunk 的列表,根据该列表选择空的 chunk,然后将数据缓存于其中。
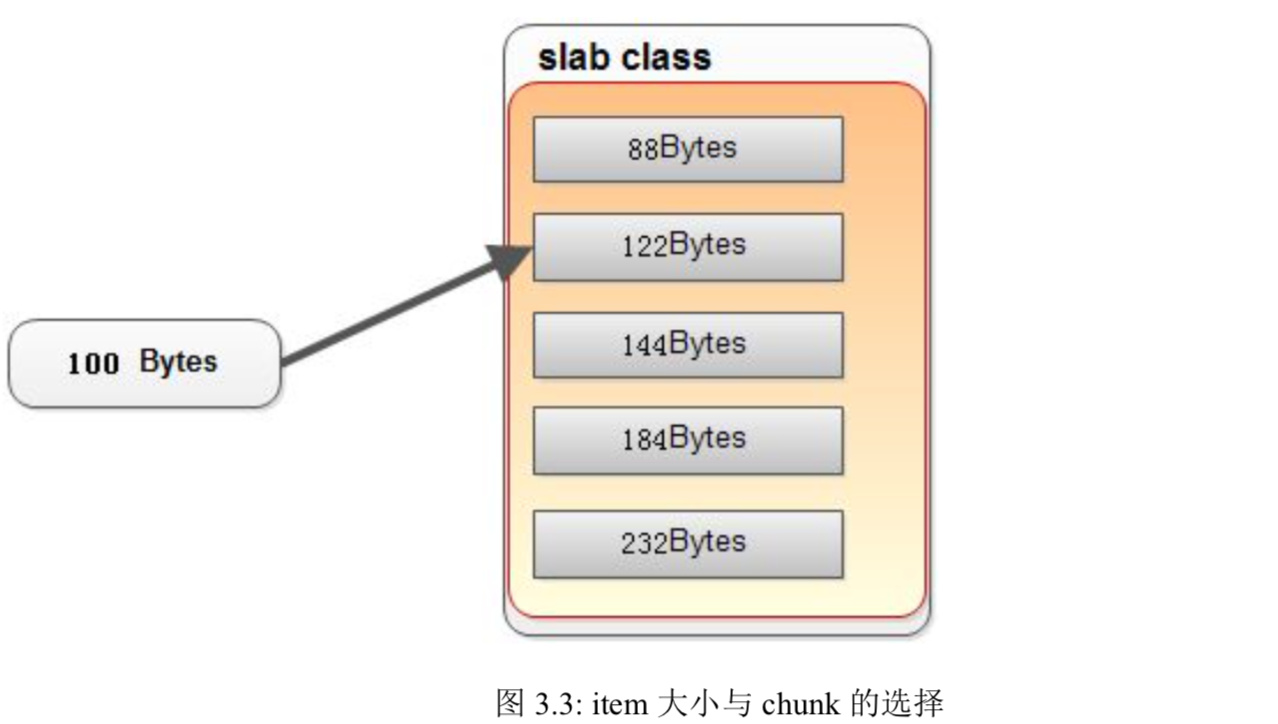
警告:
如果有100byte的内存要存,但122大小的仓库的chunk满了
并不会寻找更大的,如144的仓库来存储,
而是把122仓库的旧数据踢掉!详见过期与删除机制
固定大小的chunk带来的内存浪费
由于 slab allocator 机制中,分配的 chunk 的大小是”固定”的,因此,对于特定的 item,可能造成内存空间的浪费。
比如,将 100 字节的数据缓存到 122 字节的 chunk 中,剩余的 22 字节就浪费了图 3.4)

对于 chunk 空间的浪费问题,无法彻底解决,只能缓解该问题。
开发者可以对网站中缓存中的 item 的长度进行统计,并制定合理的 slab class 中的 chunk 的大小。
可惜的是,我们目前还不能自定义 chunk 的大小,但可以通过参数来调整各 slab class 中 chunk 大小的增长速度。即增长因子,grow factor!
growfactor调优
Memcached 在启动时可以通过- f 选项指定 Growth Factor 因子,并在某种程度上控制 slab 之间的差异。默认值为 1.25. 但是,在该选项出现之前,这个因子曾经固定为 2, 称为”powers of2”策略。
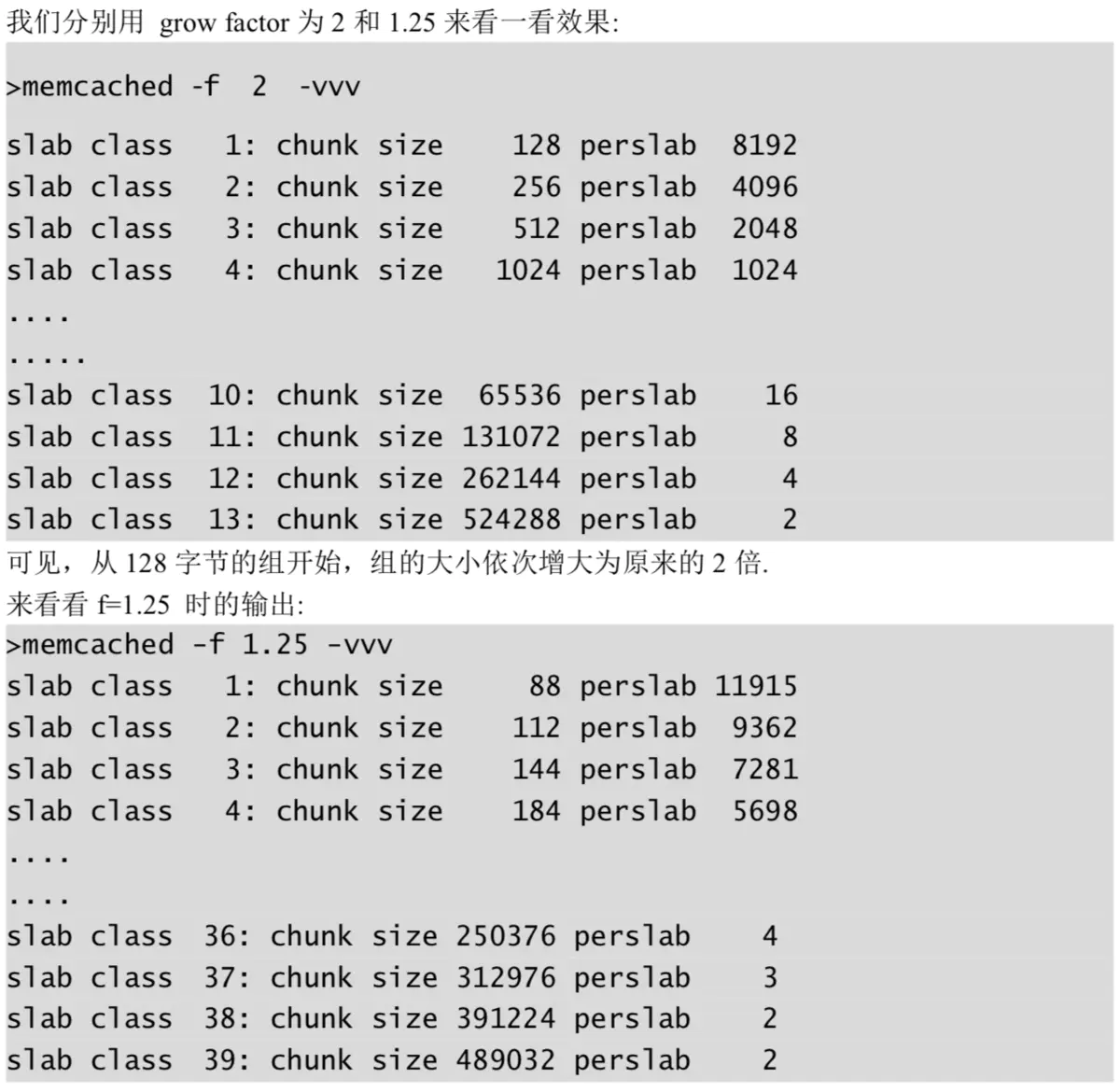
对比可知,当 f=2 时,各 slab 中的 chunk size 增长很快,有些情况下就相当浪费内存。因此,我们应细心统计缓存的大小,制定合理的增长因子。
注意:
当 f=1.25 时,从输出结果来看,某些相邻的 slab class 的大小比值并非为 1.25,可能会觉得有些 计算误差,这些误差是为了保持字节数的对齐而故意设置的.
memcached的过期数据惰性删除
1: 当某个值过期后,并没有从内存删除, 因此,stats 统计时, curr_item 有其信息
2: 当某个新值去占用他的位置时,当成空 chunk 来占用.
3: 当 get 值时,判断是否过期,如果过期,返回空,并且清空, curr_item 就减少了.
这个过期,只是让用户看不到这个数据而已,并没有在过期的瞬间立即从内存删除. 这个称为 lazy expiration, 惰性失效.
好处:节省了CPU时间和检测的成本
memcached的LRU删除机制
如果以 122byte 大小的 chunk 举例, 122 的 chunk 都满了, 又有新的值(长度为 120)要加入, 要 挤掉谁?
memcached 此处用的 lru 删除机制.
(操作系统的内存管理,常用 fifo,lru 删除)
lru: least recently used 最近最少使用
fifo: first in ,first out
原理:当某个单元被请求时,维护一个计数器,通过计数器来判断最近谁最少被使用. 就把谁t出.
注意:即使某个key是设置的永久有效期,也一样会被踢出来!即-永久数据被踢现象
Memcached的一些参数限制
key 的长度: 250 字节, (二进制协议支持 65536 个字节)
value 的限制: 1m, 一般都是存储一些文本,如新闻列表等等,这个值足够了.
内存的限制: 32 位下最大设置到 2G.
如果有 30g 数据要缓存,一般也不会单实例装 30G, (不要把鸡蛋装在一个篮子里), 一般建议 开启多个实例(可以在不同的机器,或同台机器上的不同端口)
分布式集群算法
Memcached如何实现分布式
Memcached并不像MongoDB那样,允许配置多个节点,且节点之间"自动分配数据"。也就是说,Memcached节点之间是不互相通信的
因此,Memcached的分布式,要靠用户去设计算法,把数据分布在多个Memcached节点中。
求余/取模算法
代码:
interface hasher {
public function hash($str);
}
interface distribution {
public function lookup($key);
}
/**
* Class Moder
* 求余算法
*/
class Moder implements hasher, distribution {
protected $server = array();
protected $num = 0;
//计算一个字符串对应的32 位循环冗余校验码多项式
public function hash($str) {
return sprintf("%u", crc32($str));
}
//查询数据应存放的节点服务器
public function lookup($key) {
$index = $this->hash($key) % $this->num;
return $this->server[$index];
}
//模拟增加一台Memcached服务器
public function addNode($s) {
$this->server[] = $s;
$this->num++;
}
//模拟Memcached服务器宕机
public function delNode($s) {
foreach ($this->server as $key => $value) {
if($s == $value) {
unset($this->server[$key]);
}
}
$this->num--;
$this->server = array_merge($this->server); //重新整理server的键,使其按照0->1->2递增
}
}
$moder = new Moder();
$moder->addNode('a');
$moder->addNode('b');
$moder->addNode('c');
$moder->addNode('d');
for($i = 0; $i < 100; $i++) {
$key = 'key_'.$i;
echo $key, '---->', $moder->lookup($key), '<br>';
}
一致性哈希算法
通俗理解一致性哈希:把各服务器节点映射放在钟表的各个时刻上,把key也映射到钟表的某个时刻上,该key沿着钟表顺时针走,碰到的第一个节点即为该key的存储节点。如下图所示:

一致性哈希+虚拟节点算法代码
interface hasher {
public function hash($str);
}
interface distribution {
public function lookup($key);
}
class Consistency implements hasher, distribution {
protected $nodes = array();
protected $points = array();
protected $multi = 64; //每个Memcached服务器对应的虚拟节点数量
//计算一个字符串对应的32 位循环冗余校验码多项式
public function hash($str) {
return sprintf("%u", crc32($str));
}
//查询数据应存放的节点服务器
public function lookup($key) {
$position = $this->hash($key);
reset($this->points); //重置指针(因为foreach遍历时会数组指针后移,等到下次遍历数组时,key()方法获取的就不是第一个元素的键了)
$needle = key($this->points); //默认会落在第一个节点
foreach ($this->points as $key => $value) {
if($position <= $key) {
$needle = $key;
break;
}
}
return $this->points[$needle];
}
//添加节点
public function addNode($node) {
$this->nodes[$node] = array();
for($i = 0; $i < $this->multi; $i++) {
$point = $node . '_' . $i;
$point = $this->hash($point); //虚拟节点转为数字
$this->points[$point] = $node;
$this->nodes[$node][] = $point;
$this->resort();
}
}
public function delNode($node) {
foreach ($this->nodes[$node] as $p) { //清除64个虚拟节点
unset($this->points[$p]);
}
unset($this->nodes[$node]); //去掉节点
}
//对虚拟几点进行排序
protected function resort() {
ksort($this->points);
}
}
$consistency = new Consistency();
$consistency->addNode('A');
$consistency->addNode('B');
$consistency->addNode('C');
$consistency->addNode('D');
echo $consistency->hash('name');
echo $consistency->lookup('name');
并发处理-乐观锁
在新版的memcached中,增加了对并发的控制,处理方案是:乐观锁
并发:多个进程(连接), 同时操作一个key. 就是并发操作.
乐观锁:
进程A, 先操作了缓存项
在进程A第二次操作缓存项前, 进程B操作了缓存项.
之后, 进程A第二次操作缓存项. 检查, 在进程A第一次操作后, 是否有其他进程操作过需要的缓存项. 如果有, 则放弃第二次操作. 采取乐观的处理态度.(乐观锁定)
支持乐观锁的操作:
gets() 获取
cas() 设置
注意:Memcache扩展还不支持这两个操作,在telnet上可以演示
Memcached经典问题或现象
缓存雪崩现象及真实案例
缓存雪崩一般是由某个缓存节点失效,导致其他节点的缓存命中率下降,缓存中缺失的数据去数据库查询。短时间内,造成数据库服务器崩溃。
重启DB,短期又被压垮,但缓存数据也多一些。
DB反复多次启动,缓存重建完毕,DB才稳定运行。
或者,是由于缓存周期性的失效,比如每6个小时失效一次,那么每6小时,将有一个请求“峰值”,严重者甚至会令DB崩溃。
解决办法/方案:把缓存设置为随机3-9个小时的生命周期,这样不同时失效,把工作分担到各个时间点。
缓存的无底洞现象multiget-hole
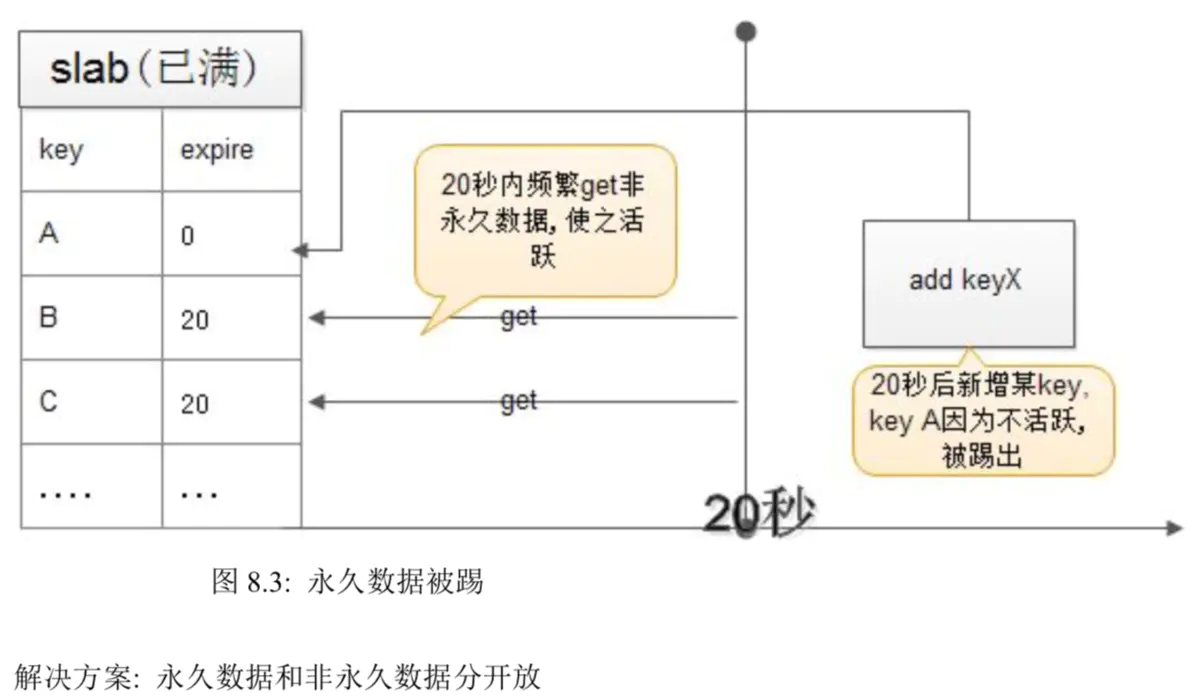
永久数据被踢现象
网上有人反馈为"memcached 数据丢失",明明设为永久有效,却莫名其妙的丢失了.
其实,这要从 2 个方面来找原因:
即前面介绍的 惰性删除,与 LRU 最近最少使用记录删除.
分析(如下图)
1:如果 slab 里的很多 chunk,已经过期,但过期后没有被 get 过, 系统不知他们已经过期.
2:永久数据很久没 get 了,不活跃,如果新增 item,则永久数据被踢了.
3: 当然,如果那些非永久数据被 get,也会被标识为 expire,从而不会再踢掉永久数据