1.样本不平衡性
常见处理方法:
- 过采样(正负样本一样多):增加正样本个数
- 方法:通常通过SMOTE进行样本生成
- 特点:召回率略低,但误杀率也低
- 下采样(正负样本一样少):减少负样本个数
- 方法:原数据要拆分为train_set1和test_set1,针对整个数据集下采样后数据也要拆分为train_set2和test_set2,然后用train_set2进行模型训练,用test_set1进行结果验证
- 特点:召回率高,但误杀率也高(坏样本大部分都能检测出来,好样本误判为好样本太多,增加工作量 )
注:
- 数据不平衡时,注意查看正样本召回率,而非整体准确率
- 在正样本量较小时,尽量选用过采样,能用生成策略就用生成策略,数据越多越好
2. 交叉验证
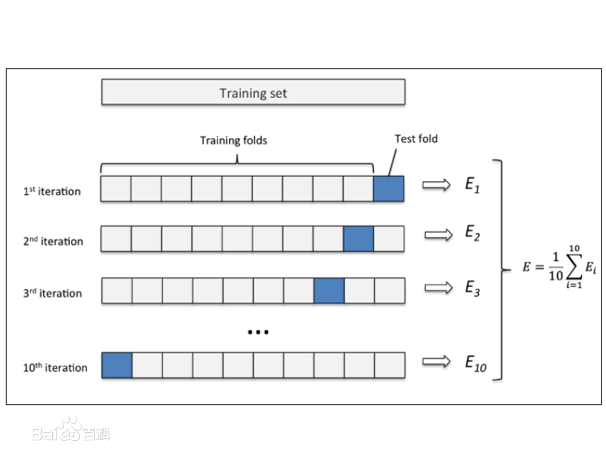
作用:通过K折交叉验证,找出模型最优参数。可通过遍历各参数列表,查看各参数值表现,从而选择最优参数。或者直接通过GridSearchCV直接选择最优参数变量。
目的:防止验证集存在异常点,造成预测结果太差;或者验证集太简单,在成预测结果太好,容易产生过拟合;取每次交叉验证的均值,则可避免这种情况。
数据区间:训链集train_set2
3.模型评估

4.正则化
正则化的目的:正则化是为了防止过拟合
参考链接:https://blog.csdn.net/jinping_shi/article/details/52433975

