1-order by
-1- 单列
-2- 多列 order by column1, column2, column3
-3- 位置select语句中的最后一条子句
-4- order by的列,不一定要选择哪些被检索,被显示的列,哪些没有出现的列也是可以的。
-5- 支持用位置序号代替(必须是select清单中,所以不支持未检索的)列名 order by 1, 3; #列名不清楚,如果数据库表修改也会出乱问题
-6- 指定排序方向desc(降序),asc(升序,默认) 多列是要分别说明
order by column1 desc, column2, column3 desc; # column1 降序 z-a, column3 降序, 默认升序,desc必须放在后面。
-7-a与A是否排序先后,要根据不同数据库系统,可以手动修改数据库系统设置
select name from eight order by id; // 最后,产生查询结果后,在排序。任意列。
2-where
操作符
= 等于
<> 不等于
!= 不等于 (有的不支持,access, access只支持<>)
<
<=
!<
>
>=
!> 不大于
between 值1 and 值2 #在指定的两个值之间
is null 为空值
where column1 <> 10;
where column1 <> ‘10’; #字符串的情况要加单引号
where column1 between 1 and 10;
where column1 is null;
组合where子语句
and(优先级高于or先执行)
or
where column1='1' or column2='2' and column3 >= 10; 小于10的也会出现,次序问题
where (column1='1' or column2='2') and column3 >= 10; 这样才没有小于10的
in指定条件范围(效率快,而且可以在括号中嵌套select语句)
where column1 in ('1', '2'); = where column1 = '1' or column1 = '2';
not in的相反(mysql不支持,NOT EXISTS 代替)
where (id, num) > (2,3) 等价于 where id > 2 or num > 3;
3-通配符
%代表任何字符出现任意次数(access用*)
_代表任何字符出现一次,匹配单个字符
select * from one where num like '%3%';
select * from one where num like '_3';
select * from one where num like 12;
虽然num是int类型,同样可以用like,可以用字符串去匹配,但是要用上通配符,就一定是否字符串,一定要加上单引号,像%12是会报错的。
放过来char类型也可以直接like 12; 数据库会自动将12转换成字符串之后再进行比较的。
[]集合 (微软的才支持)
like '[js]'; // 意思是字符串里包含有j或s的,只能匹配一个
like '[js]%'; // 意思是字符串里以j或s开头的字符串。 [^js]是取相反的意思,[!js]有些用!;
4-拼接字符串
select num+':(' + x + ',' + y + ')' as point from one; // 多少数据库用+表示连接,如将点的序号加上坐标形成新的列, 2:(232,332)
// 有些数据库系统使用||,而不是+;
MySQL对上面的都不支持。
MySql 使用concat函数
select concat (vend_name, '(', vend_country, ')') from vendors; // 参数任意长。
5-别名
列别名
表别名:from语句 表名 as 别名, 别名可以用于select,where, group by等, or
注意:oracle 不支持 as关键字,也可以说省略了as。
别名可以缩短sql语句,允许单条中多次使用
6-计算 * / + -
select id, quantity * price as expanded_price from items; // 这种不是交叉相乘,而是每一行中两个元素的相乘,结果行数不会发生变化
select id, quantity * 2.3 as quantity from items; // as可以是表中某列名,也可以是原来的,不过命名,为没有名的列,或者列名为quantity * 2.3
7-数据库函数:不同数据库系统支持的函数可能不同
不区分大小写
字符串:
length(name)
upper
lower
rtrim(name) //去掉右边空格
ltrim(name)
left(name, length) 返回name左边的length个长度,length为阿拉伯数字
left(name, 列名), 长度可变,可以是对应元组的某一属性值。列必须为数字列,长度过大会将其全部输出
right同上
日期和时间处理函数:
DATEPART(yy,列名) // 取出年,mysql不支持
year(列名), mysql支持的,day,month,hour等
to_char(),to_number() // mysql不支持
数值计算函数:
abs(列名)
cos(列名)
exp(列名)
pi() 圆周
sin()
sqrt()
tan等
汇总函数:
avg(列名) // 求平均, 去除重复avg(distinct 列名)
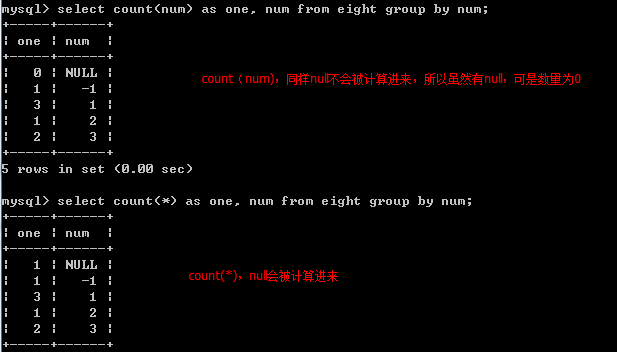
count(列) // 忽略列名中的null行,count(*)整个表有多少记录,不忽略null, 也可用distinct去除重复
max
min
sum等 去除重复sum(distinct 列名)
过滤分组:
select count(*) as num_count, num from eight group by num;// 不忽略null,num相同的被分到同一组,让后对各个组进行count操作。,count(num), null不像上面的,而是会被算出,null作为一个分组。
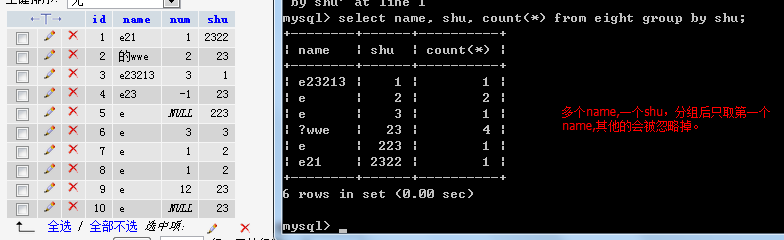
select count(*) as num_count, num from eight group by num, shu; // num和shu都相同才会被分到一起
group by 也可按选择的列数编号, group by 1, 2
对分组进行过滤:having
having支持所有where后面的操作符
where在分组前进行过滤,having在分组后进行过滤,where过滤行,where排除的行不会出现在分组中
order by排序。group by 很多是排序,可是不一定的。
order by与group by
order by 排序产出,所有过滤操作后,才计算,可以是任意列,即使列没有出现
group by 把相同的归类到一组,不能是任意列,列一定要出现
select name, shu, count(*) as count from eight group by shu;
11-子查询
情况一:in的使用
select a from eight where id = 2;
a
1
2
select b from eight where a in (1,2);
b
3
4
组合上面的查找
select b from eight where a in (select a from eight where id = 2); // 重内向外进行计算
注意:作为子查询的select语句只能查询单列,多列将会报错
情况二:填充计算列
select a, (select count(*) from seven where eigth.id = seven.id) as count from eight;
一个a在seven中有多个记录,计算它的数目
12-联结表
关系表的设计就是要保证把信息分解成多个表,比如由多个供应商生产的多种产品,如果一个表表示,供应商会出现很多次,而如果把供应商和产品分开,用两个表,用id关联,会避免重复字符串的重复。
联结查询,不同于其他就是,from语句中为多个表,而且列名出现二义性时,要完全限定列名,通过(表名.列名)表示
联结查询,不能少了正确的where语句,没有where语句,返回的将是表1的每一行与表2的每一行配对,结果也就是笛卡尔积。
表的联结个数是有限制的,对于不同的DBMS系统有不同的个数限制
select a, b from t1, t2 where t1.id = t2.id; 等价于 select a, b from t1 inner join t2 on t1.id = t2.id; // on后面和where一样
自联结:
select name from customers where name = (select name from customers where contact = 'Jim') // 用=类似于in, 子查询慢
select c1.name from customers as c1, customers as c2 where c1.name = c2.name and c2.contact = 'Jim' // 同一个表多个命名, 自联结快
自然联结:
select C1.*, C2.name, C3.contact from customers as C1, citys as C2, cat as C3 from where C1.id = C2.id and C2.id = C3.id; // 避免多列出现C1.*
外部联结:在联结中包含哪些相关表中没有关联行的行
如:列出所有产品及订购数量,及哪些没有人订购的产品
c表id,name d表id,count
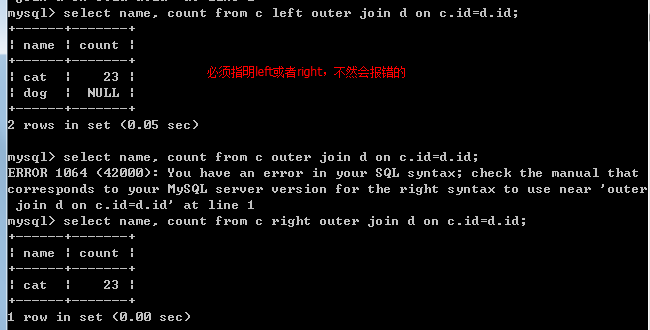
上面的可以用
select name, count from c,d where c.id *= d.id; // 左外联, =*右外联, oracle使用(+) 代替*
select name, count from c full outer join d on c.id=d.id; // 全外连接,部分dbms支持
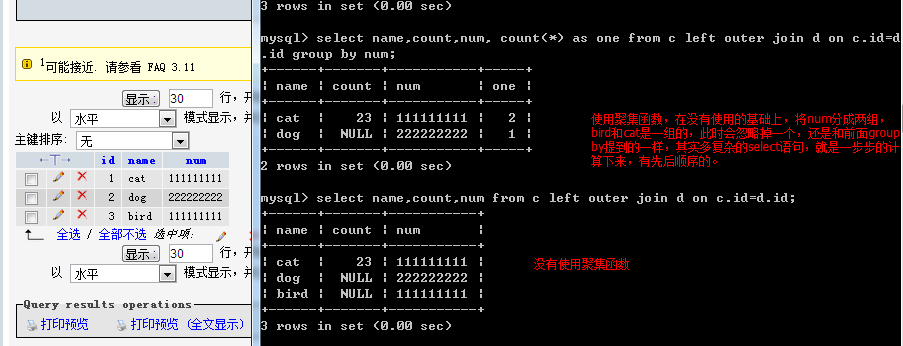
使用聚集函数的联结:
13-组合查询
将多个select语句的结果并在一起
在单个查询中从不同的表类似返回数据结构
对单个表执行多个查询,按单个查询返回数据
就是并运算,参加元素的元素要相容(类型可以不同)才行,多条select语句,n条select语句,n-1个union
union // 自动取出重复的
union all
以下mysql不支持
交 intersect (all)
差 except
14-插入数据
插入完整的一行:可以不用列出列名,直接insert into 表名 values(值); // 值一定要全部一一对应,如果有自增的不妥
插入行的部分数据:插入到哪里,就要指定对应的列名,一一对应
insert into eight (name, id) values('wew', 12); // 顺序可改变
插入查询结果:列数据类型要相容
insert into eight (name,id) select name, id from eight;
从一个表复制到另一个表
select into 导入数据
insert select 导出数据
create table nine as select * from eight; // 不同dbms不同写法
15-更新删除数据:sql没有撤销按钮,小心
更新特定行 // where要注意,不然很容易造成大量数据被更改
更新所有行:update nine set name='name',num=2 where id > 22;
删除:delete from 表名 (where 语句); //
delete from 表名; // 删除表中所有数据,truncate 表名,更快
16-创建表和操纵表
用default而不用null,not null 加 default
17-使用视图(虚拟表,表数据改变也会跟着改变)
当使用多条条件语句查询出几个表的结果时,如果下次使用,可是需求稍有改变,又得重新查询,重写书写select语句。这样会带来很多不方便。
如果能把第一次的查询结果做成一个虚拟表,那么需求稍有改变也不怕,就直接在这个表上面查询,这就是视图,也就是视图带来的好处。
性能问题:大量使用视图会造成性能下降
视图好处:重用sql语句(隐藏复杂的sql语句),保护数据,重新格式化检索出的数据(如字符串的相加,联结,加括号等复杂麻烦的sql语句,保存为视图,下次使用就不用再写了,直接查询视图。视图也可以用于将表的字段计算出结果保存在视图中,下次直接查询视图)
视图限制:数目无限,可以嵌套,可以利用从其他视图中检索数据的查询来构造一个视图,视图不能有索引,触发器。视图操作需要一定权限
create view ten as select * from eight; // as前才是真名,后为查询结果表
drop view ten; // 删除视图
查询视图的方法,同查询表,因为视图其实就是一个表
18-使用存储过程
就是为以后的使用而保存的一条或多条sql语句的集合,可将其视为批文件。也是为了隐藏SQL语句,以及要相同结果是不多次去查询数据库
begin transaction
... 修改操作
commit transaction
savepoint name; // 设置保留点
rollback to name; // 回滚回保留点,试过mysql回滚时,错误,保留点不存在

19-使用游标:结果集
declare name cursor is select * from eight; // 结果集
open cursor name;
close cursor;
部分数据库系统支持
20-高级SQL特性
约束:管理如何插入或处理数据库数据的规则,如在create table或alter table语句中指定为int类型就不能插入字符串类型
主键:主键值不能重用,如果从表中删除一行,该行的主键值将不分配给新行
外键:保证数据库完整性,涉及级联等
唯一约束:不能用于定义外键,值在表中一定唯一
检查约束:check (条件)
create table oo
( age int not null check (age > 0));
创建一个表,插入age的值不能小于或等于0,发现mysql不支持,任然可以插入不符合条件的。
索引:加快数据库的查询速度
触发器:特殊的存储过程,当特定数据库活动发生时自动执行(比约束慢)