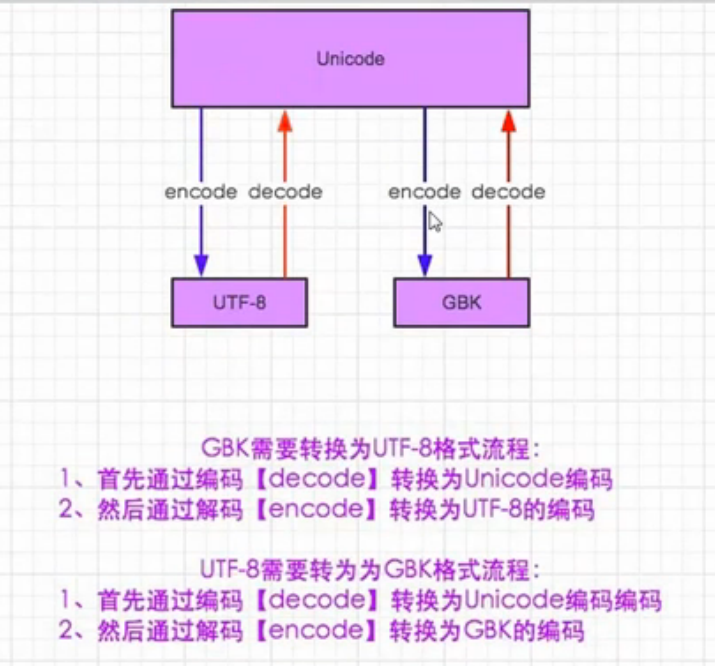
对之前的字符串类型和二进制类型(bytes类型),可以这样关联记忆,把字符串类型当作是Unicode,把bytes类型当作是GBK或者UTF-8或者是日文编码。这样字符串要转成二进制,那么就需要编码encode,二进制要转成字符串就需要解码decode。
在python3里,所有的字符默认编码是Unicode,在python2里,所有字符默认是Ascii。
只有加了如下代码,才表示默认编码是啥:
#-*- coding:utf-8 -*-
下面所有的代码都在python2.7下运行的结果:
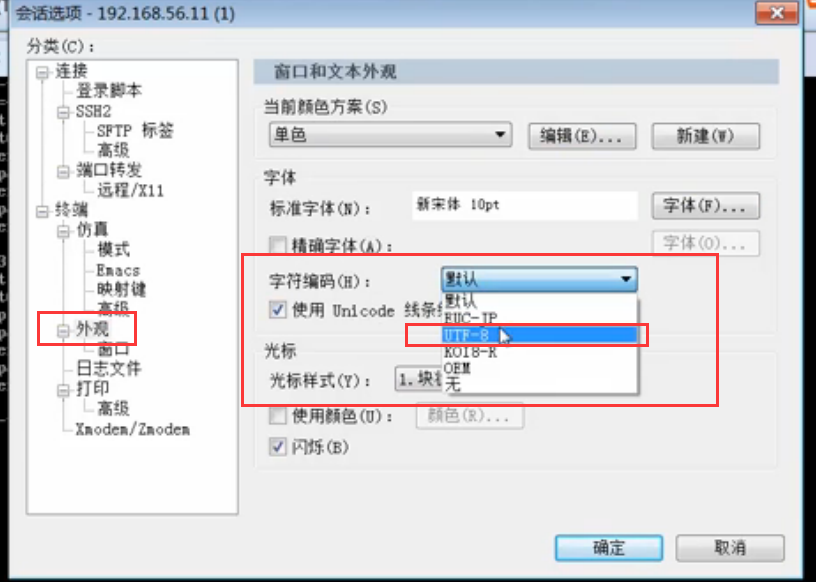
在SecureCRT里的,如果操作linux,打中文是乱码的话,说明会话的字符集不是UTF-8,需要设置下:
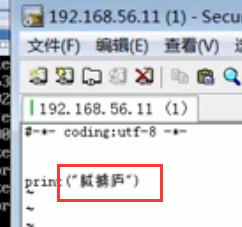
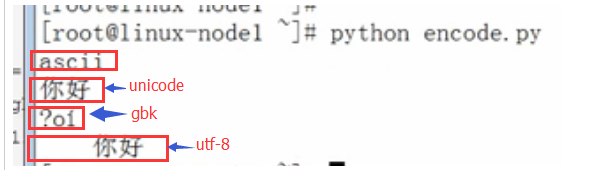
打印当前python的默认编码:python2是Ascii,python3是utf-8
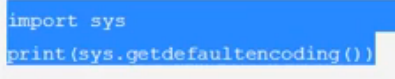
import sys print(sys.getdefaultencoding())
如果你对utf-8的字符串不进行解码(或者decode()里面啥都不写)就进行编码,系统会自动用Ascii码对你的字符串进行先解码。如下图的报错情况:

或者decode()为空,里面啥都不写,如下图:
报错如下:ascii不能解码为GBK

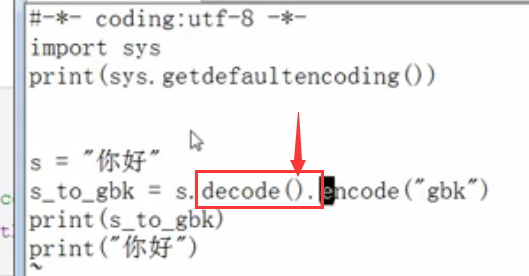
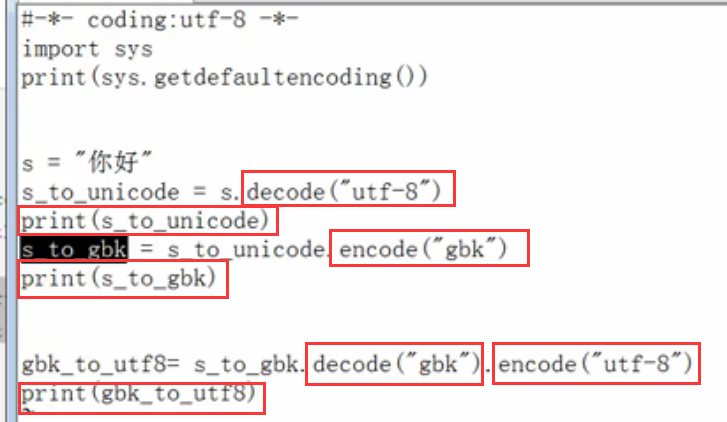
现在下面我们演示,把utf-8转换为GBK的代码:

所以,在py3里s="hi all" #这里的s,依旧是unicode,这个是字符串编码,而在py2里,s已经是utf-8的数据编码了
这里的代码过程是这样,代码的当前编码为utf-8,所以s="你好",就是utf-8的字符串编码,
utf-8要想转换为GBK,那么需要首先decode解码为Unicode,请注意这里一定要写decode("utf-8"),这个utf-8不可以省略!!!表示字符串的编码是utf-8
然后Unicode再编码为GBK,即为encode("gbk"),这里的GBK不可以省略!!!表示要转换为GBK编码!!!
但是实际操作中,上面的代码使用SecureCRT进行代码编程的时候,有其他问题:
我们首先将utf-8的代码转成unicode,并打印出来:我们默认SecureCRT的会话编码目前为UTF-8:
如下图,虽然SecureCRT的 会话编码为UTF-8,但是你打印unicode,一样会显示中文。因为unicode包括utf-8,utf-8只是unicode的扩展集。
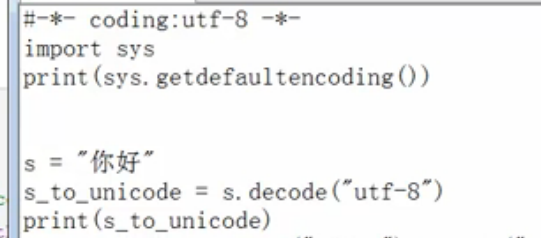

这边有一个小插曲,如果你再打印unicode的类型,会出现如下的结果:


结果会,原来显示中文的,变成乱码了(其实不是乱码,而是unicode编码,前面有一个u字母,这个是对的),
这个是因为,你加了一个打印字符类型,那么这里就变成打印一个元祖字符类型出来,而元祖的字符类型是不会显示中文的!!!
如果你想打印中文,就单独打印,不要加一个字符类型,变成元祖了。
我们继续测试代码:我们将字符串转换为gbk:


上图发现在默认SecureCRT的会话编码Terminal目前为UTF-8的情况下,如果你打印GBK格式的话,会显示乱码,这个是对的。
这个时候,我们把会话编码改成默认,因为你选择默认的话,那么编码就随系统windows走,会GBK编码:
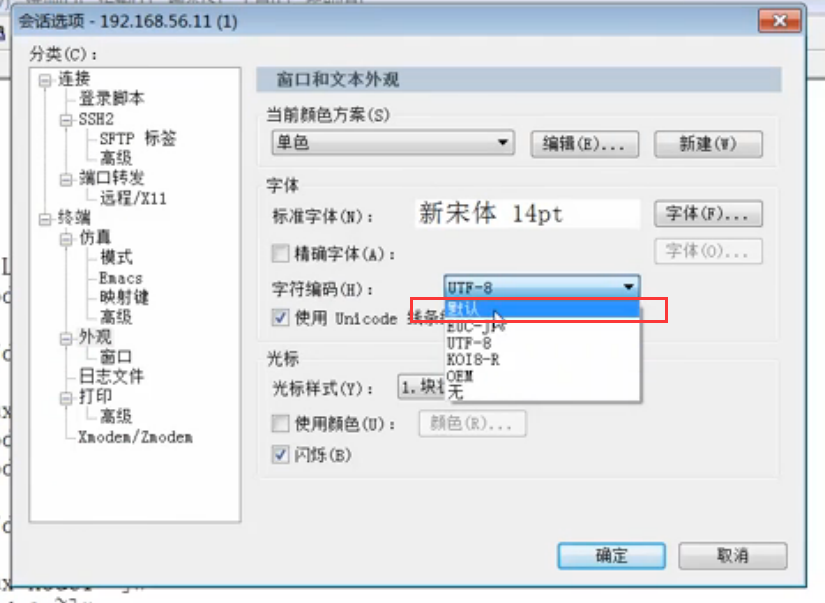
这个时候,我们再运行一次程序:发现gbk的中文正确显示了:说明默认为随系统的默认编码走了!

我们这个时候恢复unicode的打印,如下:同时把默认SecureCRT的会话编码Terminal改为默认的GBK:

结果如下:

结论:这里有个特殊情况:
1、如果默认SecureCRT的会话编码Terminal为默认的gbk,那么打印字符串为unicode无法显示;因为两个字符集不同。
2、如果默认SecureCRT的会话编码Terminal为utf-8,那么打印字符串为unicode可以正确显示。因为utf-8是unicode的扩展集。
最终,我们把转过去的gbk,再转回为utf-8,最终代码如下:当前CRT的会话编码为utf-8
字符串可以直接在前面加一个字母u,来代表是unicode字符串:注意这里的u必须在封号""之外写,不可以写到里面

这里的s就是unicode编码。
上面都是python2,那么下面的代码,是运行在python3里的。
py3里,只有 unicode编码格式 的字节串才能叫作str。
其他编码格式的统统都叫bytes,如:gbk,utf-8,gb2312…………
这些bytes要转换为 unicode编码 才能当作str来用,就需要知道 bytes 的编码格式。
如果你事先知道,比如gbk,就可以用 bytes.decode('gbk')将bytes解码为unicode字符。
如果很不幸,你有一堆bytes,不知道它们的编码(例如 网站服务器返回的响应体),
这时候,你就需要chardet 来测试它们的编码。
首先,我们测试,python3的默认字符串编码是unicode:
我们定义一个字符串,因为默认是unicode,所以我们一开始根本就没有decode()的方法
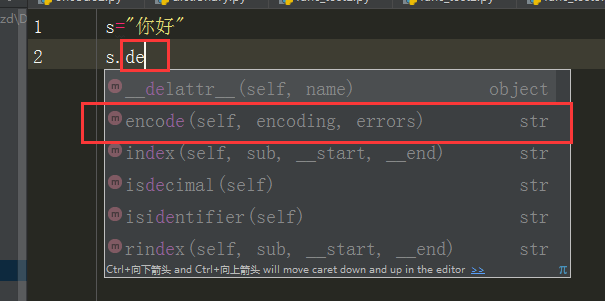
那么我们编码为gbk,运行居然乱码,这个是为什么呢?其实不是乱码,而是转为了二进制的bytes类型,在py3里,所有的非unicode的字符串,都会转换为二进制编码,bytes类型

导师给了一个结论,所有的编码分为两种情况,一个是内存(字符串)编码,一个是硬盘(文件存储)编码:
注意使用的场景不一样,字符串编码是在内存里用的,硬盘是文件保存的时候使用的编码,而文件存储一般使用utf-8,因为存储的时候使用utf-8更节省空间,英文1个字符,欧洲2个字符,东亚中文等3个字符。
字符在计算机的内存中统一是以Unicode编码的。只有在字符要被写进文件、存进硬盘或者从服务器发送至客户端(例如网页前端的代码)时会变成utf-8
所以,在py3里s="hi all" #这里的s,依旧是unicode,这个是字符串编码,而在py2里,s已经是utf-8的数据编码了
包括在pycharm的右下角,显示的utf-8,也是文件的存储编码,跟字符串编码无关。
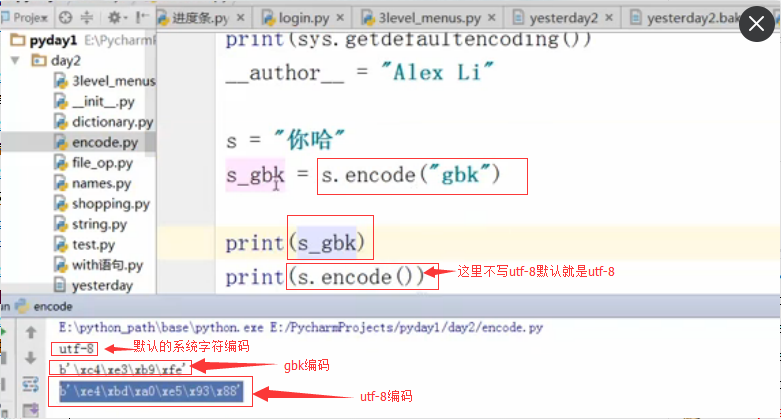
中文gbk编码是2个字符,而utf-8是3个字符,所以上图utf-8要比GBK更长1个字节
如果只是更改了pycharm右下角的文件存储编码,那么会报错的:因为当前文件存储编码是GBK了,你默认还是utf-8,就报错了。
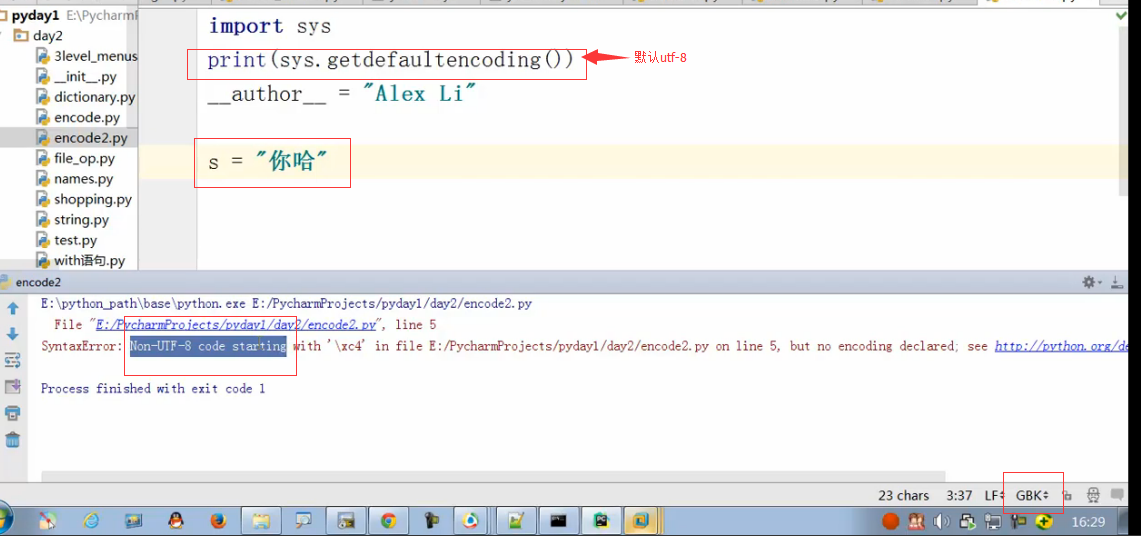
所以在文件头也申明,程序的编码为gbk跟文件编码保持一致:看下面的截图,两个蓝色的框必须保持编码一致:这样就不会报错了。

特别要注意,不管你文件编码,编程代码编码怎么变,字符串赋值的一定是unicode,如上图的变量s就是unicode编码。这个是py3的特有特性!!!
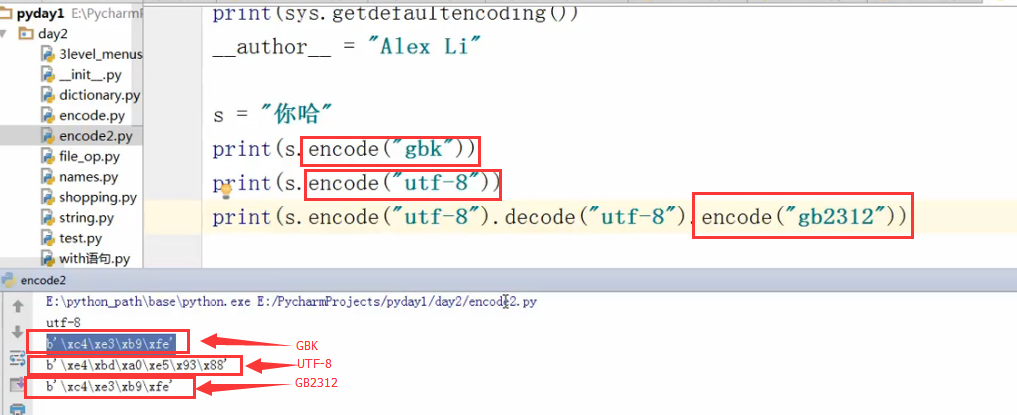
发现GBK或者GB2312的bytes数据类型是一样的。因为“你哈”在这两个类型都有。
gb2312是gbk的子集。