首先要明白一点,为什么要使用链路跟踪?
当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错。
它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的。
基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护机制
首先,我们先在project-solr和project-shopping-mall里加配置:
project-solr中的application.yml:
logging:
path: D:worklogsproject-solr #打印存放日志的路径
level:
com.gaofei: info #包名下日志的级别
project-shopping-mall中的application.yml:
logging:
path: D:worklogsproject-shopping-mall #打印存放日志的路径
level:
com.gaofei: info #包下面日志级别
大家可以看出我两个服务里的日志存放的路径不一样,这样也便于区分
在project-solr里的constroller里:
@RestController//这里使此Constroller中所有的方法返回的不是页面
public class SolrSearchConstroller {
public static Logger logger=LoggerFactory.getLogger(SolrSearchConstroller.class);
@RequestMapping("/SolrSearch")
public String SolrSearch(){
logger.info("Solr被调用");
return "这里是Solr";
}
}
在project-shopping-mall里的constroller:
@Controller
public class PageController {
public static Logger logger=LoggerFactory.getLogger(PageController.class);
@Autowired
private RestTemplate restTemplate;
@RequestMapping("/toIndex")
public String toIndex(Model model){
logger.info("执行调用");
String msg=restTemplate.getForEntity("http://project-solr/SolrSearch",String.class).getBody();//project-solr是调用注册中心里的名字
logger.info("调用结束");
model.addAttribute("msg",msg);
return "/index";
}
}
接下来执行:
在这里如果没有logs后面的目录它会自动创建
点开两个日志文件:
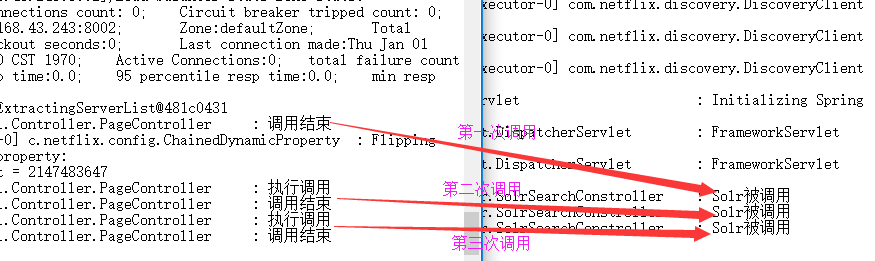
这里因为我运行刷新了3次,所以执行了3次,而两个日志里也对应了三次
如果其中一条报错那么也很快可以找到答案,并且知道哪个日志里报错,也就对应了哪个服务报错
那么问题来了,如果我们在开发中,一天可能会运行n次,那么其中某次运行报错,我们就要在n次调用时来找对应的服务,那么怎么办,我们不可能一一对应查找
这时候我们可以进行链路追踪,只需要在对应的服务器build.gradle加上Spring Cloud Sleuth依赖
//分布式链路依赖
compile group: 'org.springframework.cloud', name: 'spring-cloud-starter-sleuth'
这里我只用到了两个服务project-solr和project-shopping-mall,所以这里就在这两个服务build.gradle中添加
之后执行,打开存放的日志:
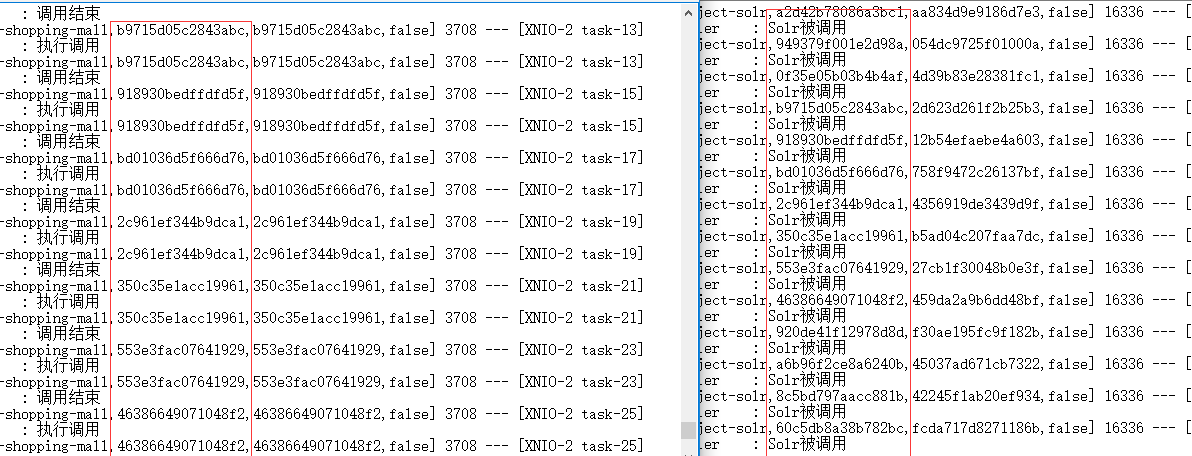
这里我运行刷新了n次,那么怎么在另一个服务找到对应的调用呢?大家仔细看一下红块中的链路是不是对应相应的服务
我随便拿一个进行查找

通过查找可以发现,可以找到对应的链路,那么也就是每次运行都会出现一个链路,可以来查找相应服务的操作是否执行成功,那么这也就是链路追踪
下一篇我会写分布式服务整合zipkin的链路跟踪