数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。数组的长度是数组类型的组成部分。因为数组的长度是数组类型的一个部分,不同长度或不同类型的数据组成的数组都是不同的类型,因此在Go语言中很少直接使用数组(不同长度的数组因为类型不同无法直接赋值)。和数组对应的类型是切片,切片是可以动态增长和收缩的序列,切片的功能也更加灵活,但是要理解切片的工作原理还是要先理解数组。
我们先看看数组有哪些定义方式:
var a [3]int // 定义长度为3的int型数组, 元素全部为0
var b = [...]int{1, 2, 3} // 定义长度为3的int型数组, 元素为 1, 2, 3
var c = [...]int{2: 3, 1: 2} // 定义长度为3的int型数组, 元素为 0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 定义长度为6的int型数组, 元素为 1, 2, 0, 0, 5, 6
第一种方式是定义一个数组变量的最基本的方式,数组的长度明确指定,数组中的每个元素都以零值初始化。
第二种方式定义数组,可以在定义的时候顺序指定全部元素的初始化值,数组的长度根据初始化元素的数目自动计算。
第三种方式是以索引的方式来初始化数组的元素,因此元素的初始化值出现顺序比较随意。这种初始化方式和map[int]Type类型的初始化语法类似。数组的长度以出现的最大的索引为准,没有明确初始化的元素依然用0值初始化。
第四种方式是混合了第二种和第三种的初始化方式,前面两个元素采用顺序初始化,第三第四个元素零值初始化,第五个元素通过索引初始化,最后一个元素跟在前面的第五个元素之后采用顺序初始化。
数组的内存结构比较简单。比如下面是一个[4]int{2,3,5,7}数组值对应的内存结构:
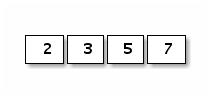
图 1-7 数组布局
Go语言中数组是值语义。一个数组变量即表示整个数组,它并不是隐式的指向第一个元素的指针(比如C语言的数组),而是一个完整的值。当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。如果数组较大的话,数组的赋值也会有较大的开销。为了避免复制数组带来的开销,可以传递一个指向数组的指针,但是数组指针并不是数组。
var a = [...]int{1, 2, 3} // a 是一个数组
var b = &a // b 是指向数组的指针
fmt.Println(a[0], a[1]) // 打印数组的前2个元素
fmt.Println(b[0], b[1]) // 通过数组指针访问数组元素的方式和数组类似
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v)
}
其中b是指向a数组的指针,但是通过b访问数组中元素的写法和a类似的。还可以通过for range来迭代数组指针指向的数组元素。其实数组指针类型除了类型和数组不同之外,通过数组指针操作数组的方式和通过数组本身的操作类似,而且数组指针赋值时只会拷贝一个指针。但是数组指针类型依然不够灵活,因为数组的长度是数组类型的组成部分,指向不同长度数组的数组指针类型也是完全不同的。
可以将数组看作一个特殊的结构体,结构的字段名对应数组的索引,同时结构体成员的数目是固定的。内置函数len可以用于计算数组的长度,cap函数可以用于计算数组的容量。不过对于数组类型来说,len和cap函数返回的结果始终是一样的,都是对应数组类型的长度。
我们可以用for循环来迭代数组。下面常见的几种方式都可以用来遍历数组:
for i := range a {
fmt.Printf("a[%d]: %d
", i, a[i])
}
for i, v := range b {
fmt.Printf("b[%d]: %d
", i, v)
}
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d
", i, c[i])
}
用for range方式迭代的性能可能会更好一些,因为这种迭代可以保证不会出现数组越界的情形,每轮迭代对数组元素的访问时可以省去对下标越界的判断。
用for range方式迭代,还可以忽略迭代时的下标:
var times [5][0]int
for range times {
fmt.Println("hello")
}
其中times对应一个[5][0]int类型的数组,虽然第一维数组有长度,但是数组的元素[0]int大小是0,因此整个数组占用的内存大小依然是0。没有付出额外的内存代价,我们就通过for range方式实现了times次快速迭代。
数组不仅仅可以用于数值类型,还可以定义字符串数组、结构体数组、函数数组、接口数组、管道数组等等:
// 字符串数组
var s1 = [2]string{"hello", "world"}
var s2 = [...]string{"你好", "世界"}
var s3 = [...]string{1: "世界", 0: "你好", }
// 结构体数组
var line1 [2]image.Point
var line2 = [...]image.Point{image.Point{X: 0, Y: 0}, image.Point{X: 1, Y: 1}}
var line3 = [...]image.Point{{0, 0}, {1, 1}}
// 图像解码器数组
var decoder1 [2]func(io.Reader) (image.Image, error)
var decoder2 = [...]func(io.Reader) (image.Image, error){
png.Decode,
jpeg.Decode,
}
// 接口数组
var unknown1 [2]interface{}
var unknown2 = [...]interface{}{123, "你好"}
// 管道数组
var chanList = [2]chan int{}
我们还可以定义一个空的数组:
var d [0]int // 定义一个长度为0的数组
var e = [0]int{} // 定义一个长度为0的数组
var f = [...]int{} // 定义一个长度为0的数组
长度为0的数组在内存中并不占用空间。空数组虽然很少直接使用,但是可以用于强调某种特有类型的操作时避免分配额外的内存空间,比如用于管道的同步操作:
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
在这里,我们并不关心管道中传输数据的真实类型,其中管道接收和发送操作只是用于消息的同步。对于这种场景,我们用空数组来作为管道类型可以减少管道元素赋值时的开销。当然一般更倾向于用无类型的匿名结构体代替:
c2 := make(chan struct{})
go func() {
fmt.Println("c2")
c2 <- struct{}{} // struct{}部分是类型, {}表示对应的结构体值
}()
<-c2
我们可以用fmt.Printf函数提供的%T或%#v谓词语法来打印数组的类型和详细信息:
fmt.Printf("b: %T
", b) // b: [3]int
fmt.Printf("b: %#v
", b) // b: [3]int{1, 2, 3}