本文采取循序渐进的方式,从理论到实践,从RequireJS官方API文档中,总结出在使用RequireJS过程中最常用的一些用法,并对文档中不够清晰具体的内容,加以例证和分析,分享给大家供大家参考,具体内容如下
1. 模块化
相信每个前端开发人员在刚开始接触js编程时,都写过类似下面这样风格的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<script type="text/javascript"> var a = 1; var b = 2; var c = a * a + b * b; if(c> 1) { alert('c > 1'); } function add(a, b) { return a + b; } c = add(a,b);</script> |
|
1
|
<a href="javascript:;" onclick="click(this);" title="">请点击</a> |
这些代码的特点是:
- 到处可见的全局变量
- 大量的函数
- 内嵌在html元素上的各种js调用
当然这些代码本身在实现功能上并没有错误,但是从代码的可重用性,健壮性以及可维护性来说,这种编程方式是有问题的,尤其是在页面逻辑较为复杂的应用中,这些问题会暴露地特别明显:
- 全局变量极易造成命名冲突
- 函数式编程非常不利于代码的组织和管理
- 内嵌的js调用很不利于代码的维护,因为html代码有的时候是十分臃肿和庞大的
所以当这些问题出现的时候,js大牛们就开始寻找去解决这些问题的究极办法,于是模块化开发就出现了。正如模块化这个概念的表面意思一样,它要求在编写代码的时候,按层次,按功能,将独立的逻辑,封装成可重用的模块,对外提供直接明了的调用接口,内部实现细节完全私有,并且模块之间的内部实现在执行期间互不干扰,最终的结果就是可以解决前面举例提到的问题。一个简单遵循模块化开发要求编写的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
//module.jsvar student = function (name) { return name && { getName: function () { return name; } }; }, course = function (name) { return name && { getName: function () { return name; } } }, controller = function () { var data = {}; return { add: function (stu, cour) { var stuName = stu && stu.getName(), courName = cour && cour.getName(), current, _filter = function (e) { return e === courName; }; if (!stuName || !courName) return; current = data[stuName] = data[stuName] || []; if (current.filter(_filter).length === 0) { current.push(courName); } }, list: function (stu) { var stuName = stu && stu.getName(), current = data[stuName]; current && console.log(current.join(';')); } } };//main.jsvar stu = new student('lyzg'), c = new controller();c.add(stu,new course('javascript'));c.add(stu,new course('html'));c.add(stu,new course('css'));c.list(stu); |
以上代码定义了三个模块分别表示学生,课程和控制器,然后在main.js中调用了controller提供的add和list接口,为lyzg这个学生添加了三门课程,然后在控制台显示了出来。运行结果如下:
|
1
|
javascript;html;css |
通过上例,可以看出模块化的代码结构和逻辑十分清晰,代码看起来十分优雅,另外由于逻辑都通过模块拆分,所以达到了解耦的目的,代码的功能也会比较健壮。不过上例使用的这种模块化开发方式也并不是没有问题,这个问题就是它还是把模块引用如student这些直接添加到了全局空间下,虽然通过模块减少了很多全局空间的变量和函数,但是模块引用本身还是要依赖全局空间,才能被调用,当模块较多,或者有引入第三方模块库时,仍然可能造成命名冲突的问题,所以这种全局空间下的模块化开发的方式并不是最完美的方式。目前常见的模块化开发方式,全局空间方式是最基本的一种,另外常见的还有遵循AMD规范的开发方式,遵循CMD规范的开发方式,和ECMAScript 6的开发方式。需要说明的是,CMD和ES6跟本文的核心没有关系,所以不会在此介绍,后面的内容主要介绍AMD以及实现了AMD规范的RequireJS。
2. AMD规范
正如上文提到,实现模块化开发的方式,另外常见的一种就是遵循AMD规范的实现方式,不过AMD规范并不是具体的实现方式,而仅仅是模块化开发的一种解决方案,你可以把它理解成模块化开发的一些接口声明,如果你要实现一个遵循该规范的模块化开发工具,就必须实现它预先定义的API。比如它要求在加载模块时,必须使用如下的API调用方式:
|
1
2
3
4
|
require([module], callback)其中:[module]:是一个数组,里面的成员就是要加载的模块;callback:是模块加载完成之后的回调函数 |
所有遵循AMD规范的模块化工具,都必须按照它的要求去实现,比如RequireJS这个库,就是完全遵循AMD规范实现的,所以在利用RequireJS加载或者调用模块时,如果你事先知道AMD规范的话,你就知道该怎么用RequireJS了。规范的好处在于,不同的实现却有相同的调用方式,很容易切换不同的工具使用,至于具体用哪一个实现,这就跟各个工具的各自的优点跟项目的特点有关系,这些都是在项目开始选型的时候需要确定的。目前RequireJS不是唯一实现了AMD规范的库,像Dojo这种更全面的js库也都有AMD的实现。
最后对AMD全称做一个解释,译为:异步模块定义。异步强调的是,在加载模块以及模块所依赖的其它模块时,都采用异步加载的方式,避免模块加载阻塞了网页的渲染进度。相比传统的异步加载,AMD工具的异步加载更加简便,而且还能实现按需加载,具体解释在下一部分说明。
3. JavaScript的异步加载和按需加载
html中的script标签在加载和执行过程中会阻塞网页的渲染,所以一般要求尽量将script标签放置在body元素的底部,以便加快页面显示的速度,还有一种方式就是通过异步加载的方式来加载js,这样可以避免js文件对html渲染的阻塞。
第1种异步加载的方式是直接利用脚本生成script标签的方式:
|
1
2
3
4
5
6
7
8
|
(function() { var s = document.createElement('script'); s.type = 'text/javascript'; s.async = true; var x = document.getElementsByTagName('script')[0]; x.parentNode.insertBefore(s, x);})(); |
这段代码,放置在script标记内部,然后该script标记添加到body元素的底部即可。
第2种方式是借助script的属性:defer和async,defer这个属性在IE浏览器和早起的火狐浏览器中支持,async在支持html5的浏览器上都支持,只要有这两个属性,script就会以异步的方式来加载,所以script在html中的位置就不重要了:
|
1
2
3
|
<script defer async="true" type="text/javascript" src="app/foo.js"></script><script defer async="true" type="text/javascript" src="app/bar.js"></script><script defer async="true" type="text/javascript" src="app/main.js"></script> |
这种方式下,所有异步js在执行的时候还是按顺序执行的,不然就会存在依赖问题,比如如果上例中的main.js依赖foo.js和bar.js,但是main.js先执行的话就会出错了。虽然从来理论上这种方式也算不错了,但是不够好,因为它用起来很繁琐,而且还有个问题就是页面需要添加多个script标记以及没有办法完全做到按需加载。
JS的按需加载分两个层次,第一个层次是只加载这个页面可能被用到的JS,第二个层次是在只在用到某个JS的时候才去加载。传统地方式很容易做到第一个层次,但是不容易做到第二个层次,虽然我们可以通过合并和压缩工具,将某个页面所有的JS都添加到一个文件中去,最大程度减少资源请求量,但是这个JS请求到客户端以后,其中有很多内容可能都用不上,要是有个工具能够做到在需要的时候才去加载相关js就完美解决问题了,比如RequireJS。
4. RequireJS常用用法总结
前文多次提及RequireJS,本部分将对它的常用用法详细说明,它的官方地址是:http://www.requirejs.cn/,你可以到该地址去下载最新版RequireJS文件。RequireJS作为目前使用最广泛的AMD工具,它的主要优点是:
- 完全支持模块化开发
- 能将非AMD规范的模块引入到RequireJS中使用
- 异步加载JS
- 完全按需加载依赖模块,模块文件只需要压缩混淆,不需要合并
- 错误调试
- 插件支持
4.01 如何使用RequireJS
使用方式很简单,只要一个script标记就可以在网页中加载RequireJS:
|
1
|
<script defer async="true" src="/bower_components/requirejs/require.js"></script> |
由于这里用到了defer和async这两个异步加载的属性,所以require.js是异步加载的,你把这个script标记放置在任何地方都没有问题。
4.02 如何利用RequireJS加载并执行当前网页的逻辑JS
4.01解决的仅仅是RequireJS的使用问题,但它仅仅是一个JS库,是一个被当前页面的逻辑所利用的工具,真正实现网页功能逻辑的是我们要利用RequireJS编写的主JS,这个主JS(假设这些代码都放置在main.js文件中)又该如何利用RJ来加载执行呢?方式如下:
|
1
|
<script data-main="scripts/main.js" defer async="true" src="/bower_components/requirejs/require.js"></script> |
对比4.01,你会发现script标记多了一个data-main,RJ用这个配置当前页面的主JS,你要把逻辑都写在这个main.js里面。当RJ自身加载执行后,就会再次异步加载main.js。这个main.js是当前网页所有逻辑的入口,理想情况下,整个网页只需要这一个script标记,利用RJ加载依赖的其它文件,如jquery等。
4.03 main.js怎么写
假设项目的目录结构为:

main.js是跟当前页面相关的主JS,app文件夹存放本项目自定义的模块,lib存放第三方库。
html中按4.02的方式配置RJ。main.js的代码如下:
|
1
2
3
|
require(['lib/foo', 'app/bar', 'app/app'], function(foo, bar, app) { //use foo bar app do sth}); |
在这段JS中,我们利用RJ提供的require方法,加载了三个模块,然后在这个三个模块都加载成功之后执行页面逻辑。require方法有2个参数,第一个参数是数组类型的,实际使用时,数组的每个元素都是一个模块的module ID,第二个参数是一个回调函数,这个函数在第一个参数定义的所有模块都加载成功后回调,形参的个数和顺序分别与第一个参数定义的模块对应,比如第一个模块时lib/foo,那么这个回调函数的第一个参数就是foo这个模块的引用,在回调函数中我们使用这些形参来调用各个模块的方法,由于回调是在各模块加载之后才调用的,所以这些模块引用肯定都是有效的。
从以上这个简短的代码,你应该已经知道该如何使用RJ了。
4.04 RJ的baseUrl和module ID
在介绍RJ如何去解析依赖的那些模块JS的路径时,必须先弄清楚baseUrl和module ID这两个概念。
html中的base元素可以定义当前页面内部任何http请求的url前缀部分,RJ的baseUrl跟这个base元素起的作用是类似的,由于RJ总是动态地请求依赖的JS文件,所以必然涉及到一个JS文件的路径解析问题,RJ默认采用一种baseUrl + moduleID的解析方式,这个解析方式后续会举例说明。这个baseUrl非常重要,RJ对它的处理遵循如下规则:
- 在没有使用data-main和config的情况下,baseUrl默认为当前页面的目录
- 在有data-main的情况下,main.js前面的部分就是baseUrl,比如上面的scripts/
- 在有config的情况下,baseUrl以config配置的为准
上述三种方式,优先级由低到高排列。
data-main的使用方式,你已经知道了,config该如何配置,如下所示:
|
1
2
3
|
require.config({ baseUrl: 'scripts'}); |
这个配置必须放置在main.js的最前面。data-main与config配置同时存在的时候,以config为准,由于RJ的其它配置也是在这个位置配置的,所以4.03中的main.js可以改成如下结构,以便将来的扩展:
|
1
2
3
4
5
6
7
|
require.config({ baseUrl: 'scripts'});require(['lib/foo', 'app/bar', 'app/app'], function(foo, bar, app) { // use foo bar app do sth}); |
关于module ID,就是在require方法以及后续的define方法里,用在依赖数组这个参数里,用来标识一个模块的字符串。上面代码中的['lib/foo', 'app/bar', 'app/app']就是一个依赖数组,其中的每个元素都是一个module ID。值得注意的是,module ID并不一定是该module 相关JS路径的一部分,有的module ID很短,但可能路径很长,这跟RJ的解析规则有关。下一节详细介绍。
4.05 RJ的文件解析规则
RJ默认按baseUrl + module ID的规则,解析文件,并且它默认要加载的文件都是js,所以你的module ID里面可以不包含.js的后缀,这就是为啥你看到的module ID都是lib/foo, app/bar这种形式了。有三种module ID,不适用这种规则:
- 以/开头,如/lib/jquey.js
- 以.js结尾,如test.js
- 包含http或https,如http://xx.baidu.com/js/jquery.js
假如main.js如下使用:
|
1
2
3
4
5
6
7
|
require.config({ baseUrl: 'scripts'});require(['/lib/foo', 'test.js', '/js/jquery'], function(foo, bar, app) { // use foo bar app do sth}); |
这三个module 都不会根据baseUrl + module ID的规则来解析,而是直接用module ID来解析,等效于下面的代码:
|
1
2
3
|
<script src="/lib/foo.js"></script><script src="test.js"></script><script src="/js/jquery.js"></script> |
各种module ID解析举例:
例1,项目结构如下:
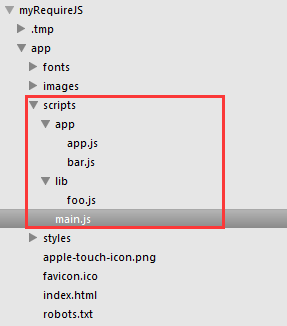
main.js如下:
|
1
2
3
4
5
6
7
|
require.config({ baseUrl: 'scripts'});require(['lib/foo', 'app/bar', 'app/app'], function(foo, bar, app) { // use foo bar app do sth}); |
baseUrl为:scripts目录
moduleID为:lib/foo, app/bar, app/app
根据baseUrl + moduleID,以及自动补后缀.js,最终这三个module的js文件路径为:
|
1
2
3
|
scripts/lib/foo.jsscripts/app/bar.jsscripts/app/app.js |
例2,项目结构同例1:
main.js改为:
|
1
2
3
4
5
6
7
8
9
10
11
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }});require(['foo', 'app/bar', 'app/app'], function(foo, bar, app) { // use foo bar app do sth}); |
这里出现了一个新的配置paths,它的作用是针对module ID中特定的部分,进行转义,如以上代码中对app这个部分,转义为../app,这表示一个相对路径,相对位置是baseUrl所指定的目录,由项目结构可知,../app其实对应的是scirpt/app目录。正因为有这个转义的存在,所以以上代码中的app/bar才能被正确解析,否则还按baseUrl + moduleID的规则,app/bar不是应该被解析成scripts/lib/app/bar.js吗,但实际并非如此,app/bar被解析成scripts/app/bar.js,其中起关键作用的就是paths的配置。通过这个举例,可以看出module ID并不一定是js文件路径中的一部分,paths的配置对于路径过程的js特别有效,因为可以简化它的module ID。
另外第一个模块的ID为foo,同时没有paths的转义,所以根据解析规则,它的文件路径时:scripts/lib/foo.js。
paths的配置中只有当模块位于baseUrl所指定的文件夹的同层目录,或者更上层的目录时,才会用到../这种相对路径。
例3,项目结果同例1,main.js同例2:
这里要说明的问题稍微特殊,不以main.js为例,而以app.js为例,且app依赖bar,当然config还是需要在main.js中定义的,由于这个问题在定义模块的时候更加常见,所以用define来举例,假设app.js模块如下定义:
|
1
2
3
4
5
6
7
|
define(['./bar'], function(bar) { return { doSth: function() { bar.doSth(); } }}); |
上面的代码通过define定义了一个模块,这个define函数后面介绍如何定义模块的时候再来介绍,这里简单了解。这里这种用法的第一个参数跟require函数一样,是一个依赖数组,第二个参数是一个回调,也是在所有依赖加载成功之后调用,这个回调的返回值会成为这个模块的引用被其它模块所使用。
这里要说的问题还是跟解析规则相关的,如果完全遵守RJ的解析规则,这里的依赖应该配置成app/bar才是正确的,但由于app.js与bar.js位于同一个目录,所以完全可利用./这个同目录的相对标识符来解析js,这样的话只要app.js已经加载成功了,那么去同目录下找bar.js就肯定能找到了。这种配置在定义模块的时候非常有意义,这样你的模块就不依赖于放置这些模块的文件夹名称了。
4.06 RJ的异步加载
RJ不管是require方法还是define方法的依赖模块都是异步加载的,所以下面的代码不一定能解析到正确的JS文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<script data-main="scripts/main" src="scripts/require.js"></script><script src="scripts/other.js"></script>//main.jsrequire.config({ paths: { foo: 'libs/foo-1.1.3' }});//other.jsrequire( ['foo'], function( foo ) { //foo is undefined}); |
由于main.js是异步加载的,所以other.js会比它先加载,但是RJ的配置存在于main.js里面,所以在加载other.js读不到RJ的配置,在other.js执行的时候解析出来的foo的路径就会变成scripts/foo.js,而正确路径应该是scripts/libs/foo-1.1.3.js。
尽管RJ的依赖是异步加载的,但是已加载的模块在多次依赖的时候,不会再重新加载:
|
1
2
3
4
5
|
define(['require', 'app/bar', 'app/app'], function(require) { var bar= require("app/bar"); var app= require("app/app"); //use bar and app do sth}); |
上面的代码,在callback定义的时候,只用了一个形参,这主要是为了减少形参的数量,避免整个回调的签名很长。依赖的模块在回调内部可以直接用require(moduleID)的参数得到,由于在回调执行前,依赖的模块已经加载,所以此处调用不会再重新加载。但是如果此处获取一个并不在依赖数组中出现的module ID,require很有可能获取不到该模块引用,因为它可能需要重新加载,如果它没有在其它模块中被加载过的话。
4.07 RJ官方推荐的JS文件组织结构
RJ建议,文件组织尽量扁平,不要多层嵌套,最理想的是跟项目相关的放在一个文件夹,第三方库放在一个文件夹,如下所示:

4.08 使用define定义模块
AMD规定的模块定义规范为:
|
1
2
3
4
5
6
|
define(id?, dependencies?, factory);其中:id: 模块标识,可以省略。dependencies: 所依赖的模块,可以省略。factory: 模块的实现,或者一个JavaScript对象 |
关于第一个参数,本文不会涉及,因为RJ建议所有模块都不要使用第一个参数,如果使用第一个参数定义的模块成为命名模块,不适用第一个参数的模块成为匿名模块,命名模块如果更名,所有依赖它的模块都得修改!第二个参数是依赖数组,跟require一样,如果没有这个参数,那么定义的就是一个无依赖的模块;最后一个参数是回调或者是一个简单对象,在模块加载完毕后调用,当然没有第二个参数,最后一个参数也会调用。
本部分所举例都采用如下项目结构:

1. 定义简单对象模块:
app/bar.js
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
define({ bar:'I am bar.'});利用main.js测试:require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }});require(['app/bar'], function(bar) { console.log(bar);// {bar: 'I am bar.'}}); |
2. 定义无依赖的模块:
app/nodec.js:
|
1
2
3
4
5
|
define(function () { return { nodec: "yes, I don't need dependence." }}); |
利用main.js测试:
|
1
2
3
4
5
6
7
8
9
10
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }});require(['app/nodec'], function(nodec) { console.log(nodec);// {nodec: yes, I don't need dependence.'}}); |
3. 定义依赖其它模块的模块:
app/dec.js:
|
1
2
3
4
5
6
|
define(['jquery'], function($){ //use $ do sth ... return { useJq: true }}); |
利用main.js测试:
|
1
2
3
4
5
6
7
8
9
10
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }});require(['app/dec'], function(dec) { console.log(dec);//{useJq: true}}); |
4. 循环依赖:
当一个模块foo的依赖数组中存在bar,bar模块的依赖数组中存在foo,就会形成循环依赖,稍微修改下bar.js和foo.js如下。
app/bar.js:
|
1
2
3
4
5
6
7
8
|
define(['foo'],function(foo){ return { name: 'bar', hi: function(){ console.log('Hi! ' + foo.name); } }}); |
lib/foo.js:
|
1
2
3
4
5
6
7
8
|
define(['app/bar'],function(bar){ return { name: 'foo', hi: function(){ console.log('Hi! ' + bar.name); } }}); |
利用main.js测试:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }});require(['app/bar', 'foo'], function(bar, foo) { bar.hi(); foo.hi();}); |
运行结果:

如果改变main.js中require部分的依赖顺序,结果:

循环依赖导致两个依赖的module之间,始终会有一个在获取另一个的时候,得到undefined。解决方法是,在定义module的时候,如果用到循环依赖的时候,在define内部通过require重新获取。main.js不变,bar.js改成:
|
1
2
3
4
5
6
7
8
9
|
define(['require', 'foo'], function(require, foo) { return { name: 'bar', hi: function() { foo = require('foo'); console.log('Hi! ' + foo.name); } }}); |
foo.js改成:
|
1
2
3
4
5
6
7
8
9
|
define(['require', 'app/bar'], function(require, bar) { return { name: 'foo', hi: function() { bar = require('app/bar'); console.log('Hi! ' + bar.name); } }}); |
利用上述代码,重新执行,结果是:

模块定义总结:不管模块是用回调函数定义还是简单对象定义,这个模块输出的是一个引用,所以这个引用必须是有效的,你的回调不能返回undefined,但是不局限于对象类型,还可以是数组,函数,甚至是基本类型,只不过如果返回对象,你能通过这个对象组织更多的接口。
4.09 内置的RJ模块
再看看这个代码:
|
1
2
3
4
5
6
7
8
9
|
define(['require', 'app/bar'], function(require) { return { name: 'foo', hi: function() { var bar = require('app/bar'); console.log('Hi! ' + bar.name); } }}); |
依赖数组中的require这个moduleID对应的是一个内置模块,利用它加载模块,怎么用你已经看到了,比如在main.js中,在define中。另外一个内置模块是module,这个模块跟RJ的另外一个配置有关,具体用法请在第5大部分去了解。
4.10 其它RJ有用功能
1. 生成相对于模块的URL地址
|
1
2
3
|
define(["require"], function(require) { var cssUrl = require.toUrl("./style.css");}); |
这个功能在你想要动态地加载一些文件的时候有用,注意要使用相对路径。
2. 控制台调试
require("module/name").callSomeFunction()
假如你想在控制台中查看某个模块都有哪些方法可以调用,如果这个模块已经在页面加载的时候通过依赖被加载过后,那么就可以用以上代码在控制台中做各种测试了。
5. RequireJS常用配置总结
在RJ的配置中,前面已经接触到了baseUrl,paths,另外几个常用的配置是:
- shim
- config
- enforceDefine
- urlArgs
5.01 shim
为那些没有使用define()来声明依赖关系、设置模块的"浏览器全局变量注入"型脚本做依赖和导出配置。
例1:利用exports将模块的全局变量引用与RequireJS关联
main.js如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }, shim: { underscore: { exports: '_' } }});require(['underscore'], function(_) { // 现在可以通过_调用underscore的api了}); |
如你所见,RJ在shim中添加了一个对underscore这个模块的配置,并通过exports属性指定该模块暴露的全局变量,以便RJ能够对这些模块统一管理。
例2:利用deps配置js模块的依赖
main.js如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
require.config({ baseUrl: 'scripts/lib', paths: { app: '../app' }, shim: { backbone: { deps: ['underscore', 'jquery'], exports: 'Backbone' } }});require(['backbone'], function(Backbone) { //use Backbone's API}); |
由于backbone这个组件依赖jquery和underscore,所以可以通过deps属性配置它的依赖,这样backbone将会在另外两个模块加载完毕之后才会加载。
例3:jquery等库插件配置方法
代码举例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
requirejs.config({ shim: { 'jquery.colorize': { deps: ['jquery'], exports: 'jQuery.fn.colorize' }, 'jquery.scroll': { deps: ['jquery'], exports: 'jQuery.fn.scroll' }, 'backbone.layoutmanager': { deps: ['backbone'] exports: 'Backbone.LayoutManager' } }}); |
5.02 config
常常需要将配置信息传给一个模块。这些配置往往是application级别的信息,需要一个手段将它们向下传递给模块。在RequireJS中,基于requirejs.config()的config配置项来实现。要获取这些信息的模块可以加载特殊的依赖“module”,并调用module.config()。
例1:在requirejs.config()中定义config,以供其它模块使用
|
1
2
3
4
5
6
7
8
9
10
|
requirejs.config({ config: { 'bar': { size: 'large' }, 'baz': { color: 'blue' } }}); |
如你所见,config属性中的bar这一节是在用于module ID为bar这个模块的,baz这一节是用于module ID为baz这个模块的。具体使用以bar.js举例:
|
1
2
3
|
define(['module'], function(module) { //Will be the value 'large'var size = module.config().size;}); |
前面提到过,RJ的内置模块除了require还有一个module,用法就在此处,通过它可以来加载config的内容。
5.03 enforceDefine
如果设置为true,则当一个脚本不是通过define()定义且不具备可供检查的shim导出字串值时,就会抛出错误。这个属性可以强制要求所有RJ依赖或加载的模块都要通过define或者shim被RJ来管理,同时它还有一个好处就是用于错误检测。
5.04 urlArgs
RequireJS获取资源时附加在URL后面的额外的query参数。作为浏览器或服务器未正确配置时的“cache bust”手段很有用。使用cache bust配置的一个示例:
urlArgs: "bust=" + (new Date()).getTime()
6. 错误处理
6.01 加载错误的捕获
IE中捕获加载错误不完美:
IE 6-8中的script.onerror无效。没有办法判断是否加载一个脚本会导致404错;更甚地,在404中依然会触发state为complete的onreadystatechange事件。
IE 9+中script.onerror有效,但有一个bug:在执行脚本之后它并不触发script.onload事件句柄。因此它无法支持匿名AMD模块的标准方法。所以script.onreadystatechange事件仍被使用。但是,state为complete的onreadystatechange事件会在script.onerror函数触发之前触发。
所以为了支持在IE中捕获加载错误,需要配置enforceDefine为true,这不得不要求你所有的模块都用define定义,或者用shim配置RJ对它的引用。
注意:如果你设置了enforceDefine: true,而且你使用data-main=""来加载你的主JS模块,则该主JS模块必须调用define()而不是require()来加载其所需的代码。主JS模块仍然可调用require/requirejs来设置config值,但对于模块加载必须使用define()。比如原来的这段就会报错:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
require.config({ enforceDefine: true, baseUrl: 'scripts/lib', paths: { app: '../app' }, shim: { backbone: { deps: ['underscore', 'jquery'], exports: 'Backbone' } }});require(['backbone'], function(Backbone) { console.log(Backbone);}); |
把最后三行改成:
|
1
2
3
|
define(['backbone'], function(Backbone) { console.log(Backbone);}); |
才不会报错。
6.02 paths备错
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
requirejs.config({ //To get timely, correct error triggers in IE, force a define/shim exports check. enforceDefine: true, paths: { jquery: [ //If the CDN location fails, load from this location 'lib/jquery' ] }});//Laterrequire(['jquery'], function ($) {}); |
上述代码先尝试加载CDN版本,如果出错,则退回到本地的lib/jquery.js。
注意: paths备错仅在模块ID精确匹配时工作。这不同于常规的paths配置,常规配置可匹配模块ID的任意前缀部分。备错主要用于非常的错误恢复,而不是常规的path查找解析,因为那在浏览器中是低效的。
6.03 全局 requirejs.onError
为了捕获在局域的errback中未捕获的异常,你可以重载requirejs.onError():
|
1
2
3
4
5
6
7
8
|
requirejs.onError = function (err) { console.log(err.requireType); if (err.requireType === 'timeout') { console.log('modules: ' + err.requireModules); } throw err;}; |
以上就是本文的全部内容,希望对大家的学习有所帮助。