1. Mysql事务的四大特性
事务:就是针对数据库的一组操作,他可由多条sql语句组成,且每个SQL相互依赖。只要程序在执行过程中有一条SQL执行失败,则其他语句都不会执行。
Mysql的事务要求必须满足A,C,I,D这4个基本特性。
- A-原子性:事务中的sql要么同时成功,要么同时失败。
- C-一致性:事务前后,数据总量保持不变。
- I-隔离性:各个事务相互隔离,互不干扰【当一个事务在执行时,不会受到其他事务的影响,保证了未完成事务的所有操作与数据库系统的隔离,直到事务完成为止,才能看到事务的执行结果】
- D-持久性:事务成功提交后,数据会永久性的保存下来。
注意:Mysql的事务默认是自动提交,如果没有主动关闭事务提交,每条SQL都会自动提交。
注意:Mysql5.7默认的存储引擎为InnoDB,该存储引擎支持事务。而常见的另一个存储引擎MyISAM不支持事务。
1.1 Mysql的保存点(补充)
在回滚事务时,事务内的所有操作都将撤销。若希望只撤销一部分,可以用保存点来实现,使用以下语句可以在事务中设置一个保存点
在事务中设置一个保存点
savepoint 保存点名;
在使用保存点后,使用以下语句可将事务回滚到指定保存点
rollback to savepoint 保存点名;
若不再需要保存点,使用以下语句删除保存点
release savepoint 保存点名;
//一个事务可以创建多个保存点,在提交事务后,事务中的所有保存点就会被删除。另外,在回滚到某个保存点后,在该保存点之后创建的保存点也会消失。//
1.2 Mysql的锁机制(补充)
不加锁出现的问题:
同一时刻,用户A,B同时要去修改同一个表的同一个数据。比如:A用户:将User表的age值10改为20,B用户:将User表的age值10改为30。
再不加锁的情况下和关闭mysql的自动提交功能情况下:
当A改了age为20,还没提交。与此同时B获取到此时User表的age值为10。
锁机制:用于解决多个事务操作同一个数据时存在的问题。在A事务进行操作时,锁住该资源,不准其他事务操作。
在Mysql中,根据存储引擎的不同,分为如下锁类型:
- 行级锁:仅锁定用户操作所涉及的记录行。【InnoDB采用】
- 表级锁:锁定用户操作行所在的整个数据表。【MyISAM采用】
锁等待:指一个线程等待其他线程释放锁的过程。
数据表的死锁:两个或多个线程在互相等待对方释放锁而出现的一种"僵持"状态,若无外力作用,他们将永久处于锁等待的状态。
2. 事务的隔离级别
隔离级别:Mysql允许多线程并发访问,隔离级别时为了保证这些事务之间不受影响而存在的。
- 读未提交:【脏读,幻读,不可重复读】
- 读已提交:【幻读,不可重复读】SQLSever,Oracle的默认隔离级别
- 可重复读:【幻读】Mysql的默认隔离级别,Mysql的InnoDB存储引擎通过多版本并发控制机制解决了幻读的问题
- 串行化:事务的最高隔离级别,会在每个读的数据上加锁,解决了所有问题。由于加锁,导致性能低。
==============================
- 脏读:一个事务可以读取到另一个事务还没提交的数据
- 幻读:一个事务内的两次查询数据不一致。幻读是由于其他事务做了插入记录的操作
- 不可重复读:一个事务内的多次查询结果不一致。不可重复读是由于查询过程中数据被其他事务进行了修改
3. 存储引擎
存储引擎:可以看作是数据表存储数据的一种格式,不同的格式具有的特性也不相同。在创建数据表时,选择合适的存储引擎则会对整体系统和性能产生巨大影响。
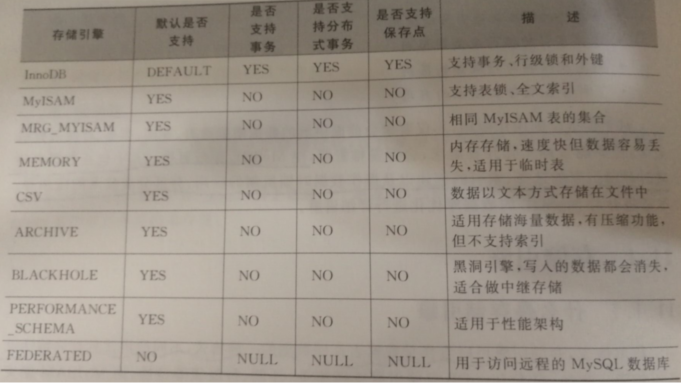
InnoDB:Mysql5.7版本中被指定为默认的存储引擎,用于完成事务,回滚等事务的安全处理。
特点:提供了良好的事务管理和并发控制。但是读写效率一般。
MyISAM:Mysql5.5以前的版本的默认存储引擎,不支持事务。
特点:不支持事务和并发性,但是读写效率快。
常见的存储引擎:
4. 完整SQL语法
select * from user where group by having order by limit
5. delete与truncate区别
delete:删除表中所有记录,有多少删多少,不会改变表结构。若:id为自增,则自增不会变为0。
truncate:删除表,自动重新创建一个一摸一样的表。若:id为自增,则自增会变为0。
6. varchar与char区别
varchar:可变字符串,长度可变。最多放65532个长度。存取慢,不占空间。
char:定长字符串,长度不可变,你设置它多长,若他达不到,则会以空格进行填补。存取快,占空间。
varchar(50):最多存放50个字符。存取慢。
char(11):必须存11个字符,一般我们设置表的时候,可以将手机号设置为char(11)。存取快。【总的来说,只要你能很确定,这个字段存字符的大小,就可以优先考虑用char】
7. count(*),count(1),count(column)的区别是啥
- count(*):对行的数据进行计算,包含NULL
- count(1):和上述一样
- count(column):对特定列进行计算,不包含NULL
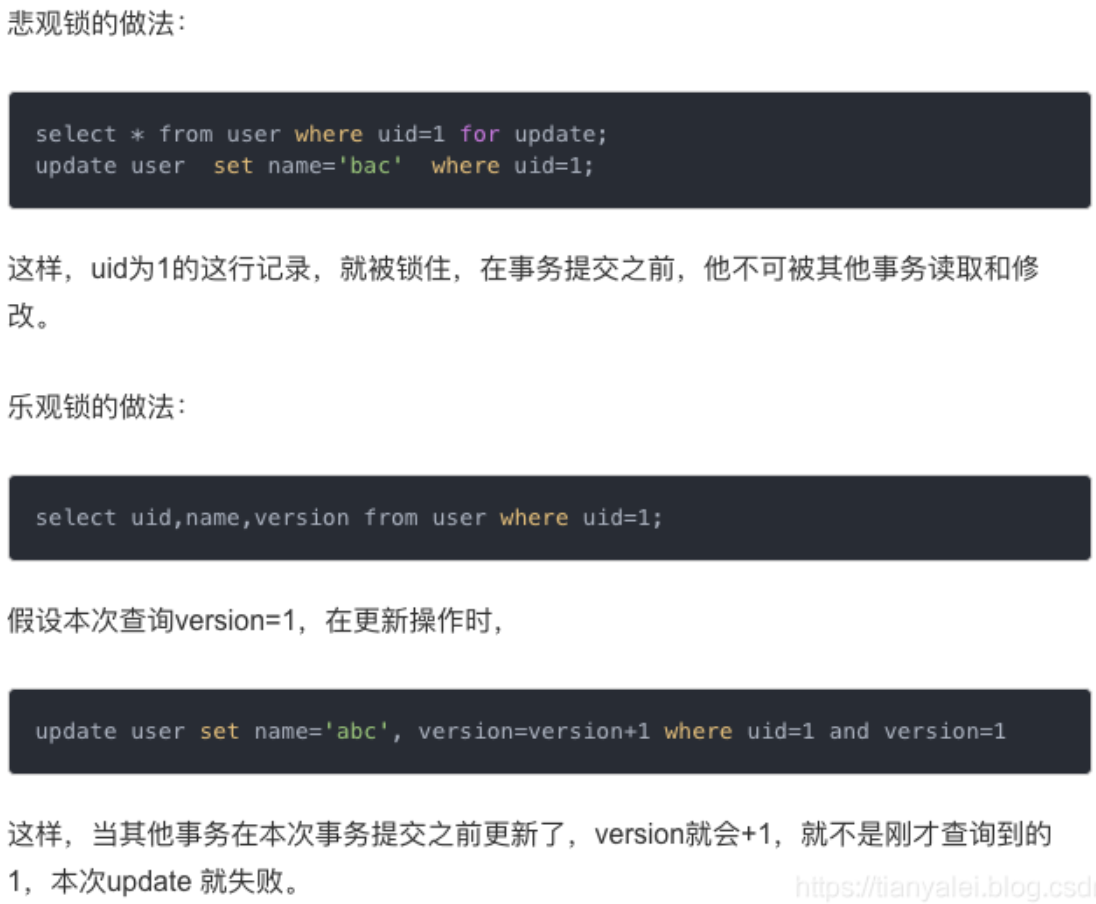
8. Mysql实现乐观锁,悲观锁
乐观锁:很乐观,每次拿数据都认为别人不会修改数据,不会上锁。在更新的时候再去判断在此期间别人是否更新了这个数据。
实现方式:
在表中加一个version字段,查询数据时得到它的值,更新时加上这个条件。
悲观锁:很悲观,每次拿数据都任务别人肯定会修改数据,会上锁。在他拿到数据操作完之前,别人不能来操作数据。
实现方式:
- 关闭事务的自动提交功能
- 在查询数据时加上“for update”
9. 数据库优化
前言:在开发中,我们要根据需求,合理安排资源,使MySQL运行更快。其中包括:建表时存储引擎的选择,索引的创建,SQL语句的优化,操作数据时锁机制的应用,分区分表技术的应用等。
9.1 索引
索引:一种特殊的数据结构,用于将表中某些字段与记录的位置建立一个对应关系,加快定位数据位置的时间。
特点:加快查询效率。但不是越多越好,虽然提高了查询效率,但是为降低服务器的负载,建里索引也会占用物理存储空间,索引的维护也比较麻烦。
分类:
- 普通索引:可以创建多个。
- 唯一索引:可以创建多个,但是创建的字段必须具有唯一约束。
- 主键索引:一般不需要我们主动创建,只要在建表时指定了主建。主建索引只能有一个,不能为NULL, 没有索引名
- 全文索引
- 空间索引
根据创建索引的字段个数,还阔以将其分为单列索引和复合索引。
- 单列索引:指在表中单个字段上创建的索引,可以是普通索引,唯一索引,主建索引,全文索引
- 复合索引:指在表中多个字段上创建一个索引,且只有在查询条件中使用了这些字段中的第一个字段时,该索引才会被使用(如:对name,age,address字段建立复合索引,在查询时,只有第一个字段被使用时,该复合索引才会被使用)。【多个字段的设置顺序要遵循“最左前缀原则”,就是把最频繁使用的字段放在最左边,然后依次类推】
explain:SQL分析语句
该关键字用于分析SQL语句的执行情况。

索引的使用原则总结:
-
查询条件中频繁使用的字段才适合建立索引
-
比起字符串类型的字段,数字型的字段更适合建立索引
-
比起存储空间大的字段,存储空间较小的字段更适合建立索引
-
重复值字段高的字段不适合建立索引
-
更新频繁的字段不适合建立索引
索引失效的情况总结:
可以使用explain命令加在要分析的sql语句前面,在执行结果中查看key这一列的值,如果为NULL,说明没有使用索引。
-
mysql估计使用全表扫描比使用索引快时
mysql估计使用全表扫描比使用索引快时,则不使用索引 -
查询时保证字段的独立
对于建立索引的字段,在查询时要保证该字段在关系运算符(如:=,>等)的一侧独立,不能是表达式的一部分或函数的参数。
如:select id from user where id+1 > 3;
如:select name from user where ASB(id) = 1; -
模糊查询中通配符的使用
在模糊查询时,若匹配模式中的最左侧含有通配符(%),会导致全表扫描。如:select name from user where namke like "%飞"; -
or条件查询
在使用or查询时,只有or两边的字段都有索引,才会触发索引。 -
列类型为字符串
比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。 -
最左前缀原则
复合索引没有使用最左前缀原则,则不会触发复合索引。 -
在索引字段上使用not,<>,!=。
不会用到索引。 优化方法: key<>0 改为 key>0 or key<0。 -
在索引字段上使用in,not in
in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)。对于连续的数值,能用 between 就不要用 in 了。
select id from t where num between 1 and 3 -
应尽量避免在 where 子句中对字段进行 null 值判断
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
9.2 SQL优化
参考:https://www.cnblogs.com/xc-chejj/p/11244748.html
SQL优化,我们可以从数据表优化和sql语句优化入手。
数据表优化:
- 选择合适的存储引擎。
- 列的字段能小就小,比如:年龄字段,可以设为thyint。以达到节省空间,提高查询效率。
- 不能为null的列,尽可能设置为不为NULL。
- 如果确认该字段是定长,用char。比如:手机号。
- 一个表字段不要太多,可以拆分成多张表。
SQL语句优化:
- 不要使用select * 。阿里开发手册也这样说了的。尽量不要返回用不到的任何字段。不然会增加不必要的消耗(内存,CPU,宽带)
- 只需要查询一条数据是,可使用limit 1 提高查询。
- 要避免索引失效问题的出现。
- 避免联合查询,能改成单表查询,改成单表查询。
- 对于连续的数值,用between比用in效率高。能用between就不用in。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。