目录
A3C原理
源码实现
参考资料

针对A2C的训练慢的问题,DeepMind团队于2016年提出了多进程版本的A2C,即A3C。
|
A3C原理 |
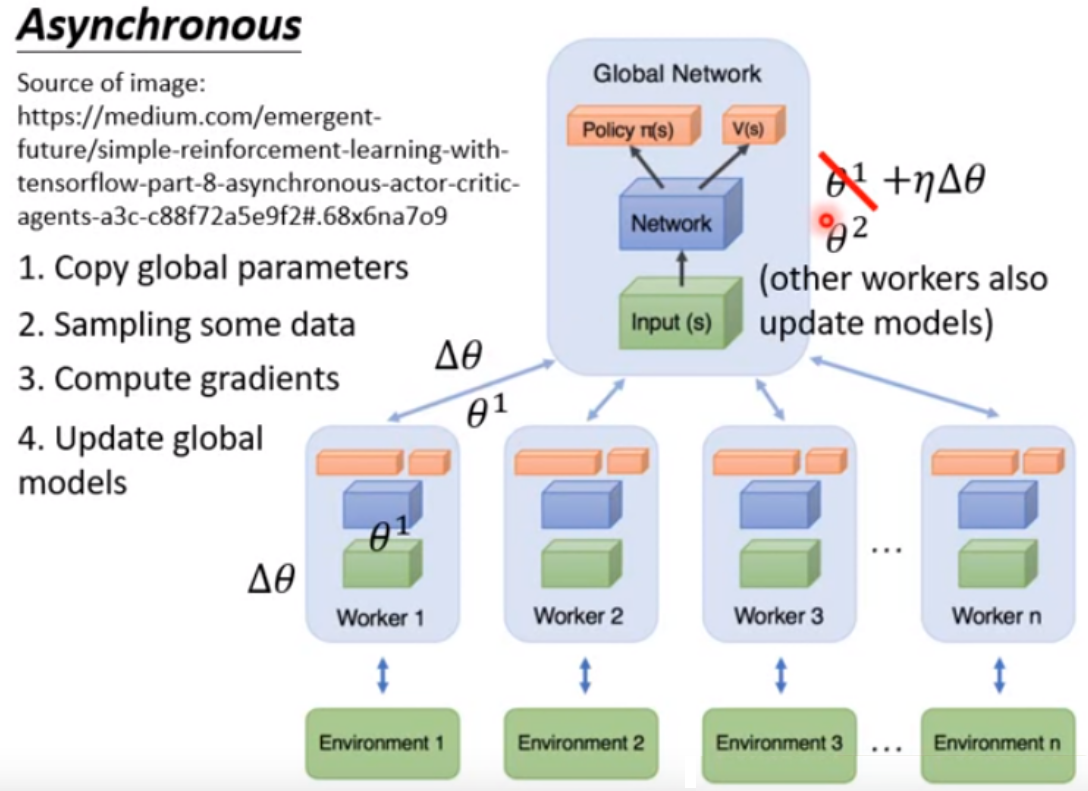
同时开多个worker,最后会把所有的经验集合在一起
一开始有一个全局的网络,假设参数是θ1
每一个worker使用一个cpu去跑,工作之前就把全局的参数拷贝过来
每一个actor和环境做互动,为了收集到各种各样的数据,制定策略收集比较多样性的数据
计算梯度
更新全局的参数为θ2
所有的actor都是并行的
可以再开一个进程用于测试全局模型的表现
|
源码实现 |


import gym import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.distributions import Categorical import torch.multiprocessing as mp import time import matplotlib.pyplot as plt # Hyperparameters n_train_processes = 3 learning_rate = 0.0002 update_interval = 5 gamma = 0.98 max_train_ep = 300 max_test_ep = 400 class ActorCritic(nn.Module): def __init__(self): super(ActorCritic, self).__init__() self.fc1 = nn.Linear(4, 256) self.fc_pi = nn.Linear(256, 2) self.fc_v = nn.Linear(256, 1) def pi(self, x, softmax_dim=0): x = F.relu(self.fc1(x)) x = self.fc_pi(x) prob = F.softmax(x, dim=softmax_dim) return prob def v(self, x): x = F.relu(self.fc1(x)) v = self.fc_v(x) return v def train(global_model, rank): local_model = ActorCritic() local_model.load_state_dict(global_model.state_dict()) optimizer = optim.Adam(global_model.parameters(), lr=learning_rate) env = gym.make('CartPole-v1') for n_epi in range(max_train_ep): done = False s = env.reset() while not done: s_lst, a_lst, r_lst = [], [], [] for t in range(update_interval): prob = local_model.pi(torch.from_numpy(s).float()) m = Categorical(prob) a = m.sample().item() s_prime, r, done, info = env.step(a) s_lst.append(s) a_lst.append([a]) r_lst.append(r/100.0) s = s_prime if done: break s_final = torch.tensor(s_prime, dtype=torch.float) R = 0.0 if done else local_model.v(s_final).item() td_target_lst = [] for reward in r_lst[::-1]: R = gamma * R + reward td_target_lst.append([R]) td_target_lst.reverse() s_batch, a_batch, td_target = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), torch.tensor(td_target_lst) advantage = td_target - local_model.v(s_batch) pi = local_model.pi(s_batch, softmax_dim=1) pi_a = pi.gather(1, a_batch) loss = -torch.log(pi_a) * advantage.detach() + F.smooth_l1_loss(local_model.v(s_batch), td_target.detach()) optimizer.zero_grad() loss.mean().backward() for global_param, local_param in zip(global_model.parameters(), local_model.parameters()): global_param._grad = local_param.grad optimizer.step() local_model.load_state_dict(global_model.state_dict()) env.close() print("Training process {} reached maximum episode.".format(rank)) def test(global_model): env = gym.make('CartPole-v1') score = 0.0 print_interval = 20 x = [] y = [] for n_epi in range(max_test_ep): done = False s = env.reset() while not done: prob = global_model.pi(torch.from_numpy(s).float()) a = Categorical(prob).sample().item() s_prime, r, done, info = env.step(a) s = s_prime score += r if n_epi % print_interval == 0 and n_epi != 0: print("# of episode :{}, avg score : {:.1f}".format( n_epi, score/print_interval)) x.append(n_epi) y.append(score / print_interval) score = 0.0 time.sleep(1) env.close() plt.plot(x, y) plt.savefig('pic_saved/res_A3C.jpg') plt.show() if __name__ == '__main__': global_model = ActorCritic() global_model.share_memory() processes = [] for rank in range(n_train_processes + 1): # + 1 for test process if rank == 0: p = mp.Process(target=test, args=(global_model,)) else: p = mp.Process(target=train, args=(global_model, rank,)) p.start() processes.append(p) for p in processes: p.join()
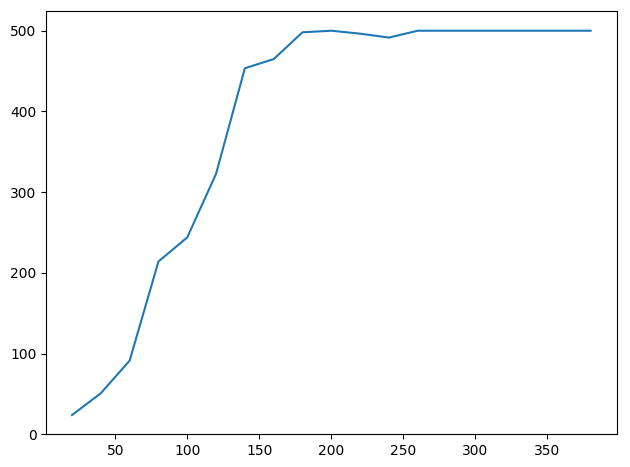
横坐标表示训练轮数,纵坐标表示智能体得分的能力(满分500分),可以看到A3C在较短的时间内就能达到满分的水平,效果确实不错。
|
参考资料 |
https://github.com/seungeunrho/minimalRL
https://www.bilibili.com/video/BV1UE411G78S?from=search&seid=10996250814942853843
paper:Actor-Critic Algorithms
paper:Asynchronous Methods for Deep Reinforcement Learning