1.1. Zookeeper的安装与使用
ZooKeeper的安装包括单机模式安装,以及集群模式安装。
安装如果有不懂可以看:
https://blog.csdn.net/lihao21/article/details/51778255
1.1.1. Windows环境下搭建Zookeeper
环境要求:必须要有jdk环境。
(1)安装jdk
(2)安装zookeeper,可以在http://zookeeper.apache.org/官网下下载zookeeper。
我下载的是3.3.6版本的zookeeper。
(3)解压zookeeper后获取到zookeeper的目录。
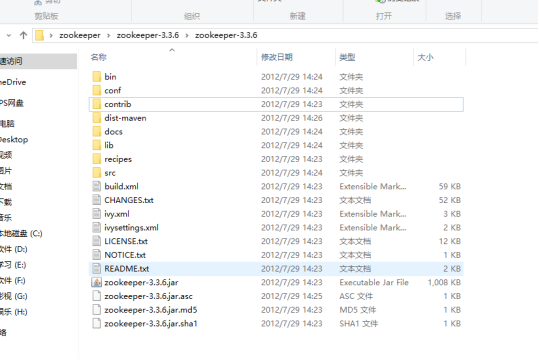
对主要的一些目录做介绍:
Bin:主要运行的一些脚本
Conf:配置文件的所在地
Lib:zookeeper的jar
(4)启动zookeeper服务
走到bin目录下去运行zkServer.cmd,双击它,但是出现一闪而退的情况,这是正常的。
到conf目录下将zoo_sample.cfg复制粘贴命名为zoo.cfg。
并修改其中的内容:
1 # The number of milliseconds of each tick 2 3 tickTime=2000 4 5 # The number of ticks that the initial 6 7 # synchronization phase can take 8 9 initLimit=10 10 11 # The number of ticks that can pass between 12 13 # sending a request and getting an acknowledgement 14 15 syncLimit=5 16 17 # the directory where the snapshot is stored. 18 19 dataDir=C:\Users\Dell\Desktop\zookeeper\zookeeper-3.3.6\zookeeper-3.3.6\data 20 21 dataDir=C:\Users\Dell\Desktop\zookeeper\zookeeper-3.3.6\zookeeper-3.3.6\log 22 23 # the port at which the clients will connect 24 25 clientPort=2181
配置文件简单解析:
1、tickTime:这个时间是作为Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2、dataDir:顾名思义就是Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
3、dataLogDir:顾名思义就是Zookeeper 保存日志文件的目录
4、clientPort:这个端口就是客户端连接Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
好修改完毕后,就可以去启动zookeeper的服务了。
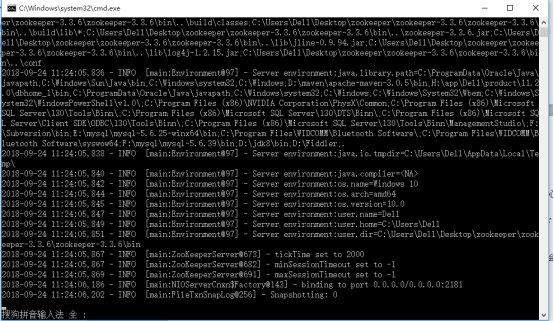
出现当前界面表示启动成功。可以去测试一下了。
补充:ZooKeeper的安装模式分为三种,分别为:单机模式(stand-alone)、集群模式和集群伪分布模式。ZooKeeper 单机模式的安装相对比较简单,如果第一次接触ZooKeeper的话,建议安装ZooKeeper单机模式或者集群伪分布模式。以上使用的是单机模式
1.1.2. Linux安装单机版
提示:
单机模式较简单,是指只部署一个zk进程,客户端直接与该zk进程进行通信。
在开发测试环境下,通过来说没有较多的物理资源,因此我们常使用单机模式。当然在单台物理机上也可以部署集群模式,但这会增加单台物理机的资源消耗。故在开发环境中,我们一般使用单机模式。
但是要注意,生产环境下不可用单机模式,这是由于无论从系统可靠性还是读写性能,单机模式都不能满足生产的需求。
环境要求:必须要有jdk环境。当前安装机器是有jdk1.8的环境了,就不演示jdk的安装了。
(1)下载zookeeper安装包zookeeper-3.3.6.tar.gz
(2)上传到linux上,并将其解压出来。解压命令:tar -zxvf zookeeper-3.3.6.tar.gz
解压后会得到一个zookeeper-3.3.6的目录。并将去复制到/usr/local目录下
cp -r zookeeper-3.3.6 zookeeper
(3)进入到/usr/local/zookeeper/conf目录下,拷贝zoo_samle.cfg为zoo.cfg
cd zookeeper-3.3.6/conf/
cp zoo_sample.cfg zoo.cfg
(4)编辑zoo.cfg文件,修改为:
1 # The number of milliseconds of each tick 2 3 tickTime=2000 4 5 # The number of ticks that the initial 6 7 # synchronization phase can take 8 9 initLimit=10 10 11 # The number of ticks that can pass between 12 13 # sending a request and getting an acknowledgement 14 15 syncLimit=5 16 17 # the directory where the snapshot is stored. 18 19 # 指定数据存放目录 20 21 dataDir=/usr/zookeeper 22 23 # log 存放目录 24 25 dataLogDir=/usr/zookeeper/log 26 27 # the port at which the clients will connect 28 29 # 端口号 30 31 clientPort=2181
配置文件简单解析:
1、tickTime:这个时间是作为Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2、dataDir:顾名思义就是Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
3、dataLogDir:顾名思义就是Zookeeper 保存日志文件的目录
4、clientPort:这个端口就是客户端连接Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
(5)修改环境变量
vim /etc/profile
#指向到zookeeper目录下
export ZOOKEEPER_INSTALL=/usr/local/zookeeper
export PATH=$ZOOKEEPER_INSTALL/bin:$PATH
source /etc/profile //让环境变量生效
(6)启动zookeeper
到bin目录下
./zkServer.sh start 启动
./zkServer.sh status 查看状态,看看是否启动成功
./zkServer.sh stop 关闭zookeeper服务
(7)好了安装成功,可以使用客户端去使用zookeeper了。
连接zookeeper:Zkcli.sh -server 127.0.0.1:2181
1.1.3. Linux集群版安装
单机模式的zk进程虽然便于开发与测试,但并不适合在生产环境使用。在生产环境下,我们需要使用集群模式来对zk进行部署。
注意 :
在集群模式下,建议至少部署3个zk进程,或者部署奇数个zk进程。如果只部署2个zk进程,当其中一个zk进程挂掉后,剩下的一个进程并不能构成一个quorum的大多数。因此,部署2个进程甚至比单机模式更不可靠,因为2个进程其中一个不可用的可能性比一个进程不可用的可能性还大。
环境要求:
准备三台服务器,每台服务器上必须要有jdk环境。
安装开始:
(1)上传zookeeper 压缩包并且解压出来。
(2)拷贝conf 目录下的zoo_samle.cfg文件为zoo.cfg,并修改其中的内容:
tickTime=2000 initLimit=5 syncLimit=2 dataLogDir=/usr/local/zookeeper/logs dataDir=/usr/local/zookeeper/data clientPort=2181 server.1=192.168.100.21:2888:3888 server.2=192.168.100.23:2888:3888 server.3=192.168.100.90:2888:3888
配置说明:
initLimit:
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。
syncLimit:
配置follower和leader之间发送消息,请求和应答的最大时间长度。
tickTime:
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。
server.id=host:port1:port2:
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。
dataDir:
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
注意
如果仅为了测试部署集群模式而在同一台机器上部署zk进程,server.id=host:port1:port2配置中的port参数必须不同。但是,为了减少机器宕机的风险,强烈建议在部署集群模式时,将zk进程部署不同的物理机器上面。
(3)进入zoo.cfg文件制定data的目录下创建myid文件,并写入值。
这个值是每台服务器上的zookeeper的进程id。都是不同的。
(4)三台服务器分别进行以上操作后。分别在这三台机器上启动zk进程,这样我们便将zk集群启动了起来。
在启动成功后,可以使用 ./zkServer.sh status 来查看每台服务器是否启动成功,还可以看到当前zk的进程是leader还是follower。
(5)连接
可以使用以下命令来连接一个zookeeper集群:
bin/zkCli.sh -server 192.168.100.21:2181,192.168.100.23:2181,192.168.100.90:2181
成功连接后,可以看到如下输出:

1.1.4. 客户端使用
ZooKeeper命令行工具类似于Linux的shell环境,不过功能肯定不及shell啦,但是使用它我们可以简单的对ZooKeeper进行访问,数据创建,数据修改等操作.使用 zkCli.sh -server 127.0.0.1:2181 连接到 ZooKeeper 服务,连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息。
命令行工具的一些简单操作如下:
1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容
2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据
3. 创建文件,并设置初始内容: create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串
4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串
5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置
6. 删除文件: delete /zk 将刚才创建的 znode 删除
7. 退出客户端: quit
8. 帮助命令: help