前两天帮同学实现在线预览word文档中的内容,而且需要提供可以下载的链接!在网上找了好久,都没有什么可行的方法,只得用最笨的方法来实现了。希望得到各位大神的指教。下面我就具体谈谈自己的实现过程,总结一下学习中的收获。
我相信很多程序员都遇到过,有些word文档希望直接在浏览器中打开进行预览,但是浏览器往往不是很配合,直接就提示下载,不像pdf文档,浏览器可以直接进行预览。Word文档甚至始终都会通过本地的Office软件打开。那么,问题来了,如何可以在线浏览word文档呢?
其实,我在最初的时候也没有接触过这方面的东西,一般用的比较多的是生成pdf文档,而浏览器一般都支持pdf的浏览,因此,直接通过后台传来的数据,再利用java和一些相关的jar包就可以生产一个pdf文档,在浏览器中可以直接显示。尽管可以这样,但是我们需要的是解决实际问题啊?在浏览器中打开word文档。
在网上查了一些资料,也都没有查出个所以然。看了好几个博客和论坛,也都是大同小异,测试了好几个,基本都是浏览器提示直接下载,或者打开,这里的打开也都是利用本地的Office软件打开的,所以这并不是自己想要的结果。于是,自己动手,既然浏览器不支持显示word文档,我何不将word文档按照原来word的样式和内容转为html呢?而在浏览器中,html是再熟悉不过了。基本思路就是这样,首先是利用上传的word文档转为html文件,然后生成的链接显示在jsp页面上,如果点击显示该word文档,那么实际上浏览器读取的是刚生成的html文件。
下面将自己的实现过程总结如下,欢迎各位朋友提供更好的解决办法。转载本文请在文章明显位置标明文章的原始出处,个人博客:http://itred.cnblogs.com 邮箱: it_red@sina.com
1. Word文档转为html
这里采用第三方组件jacob来实现的,本demo所用的版本为jacob-1.18-M2;下载链接为:http://sourceforge.jp/projects/sfnet_jacob-project/releases/
先在这里说一下,用这个组件还是比较麻烦的,首先要根据自己的电脑实际情况将压缩包里面的动态链接库放到多个目录下,而这个动态链接库为:
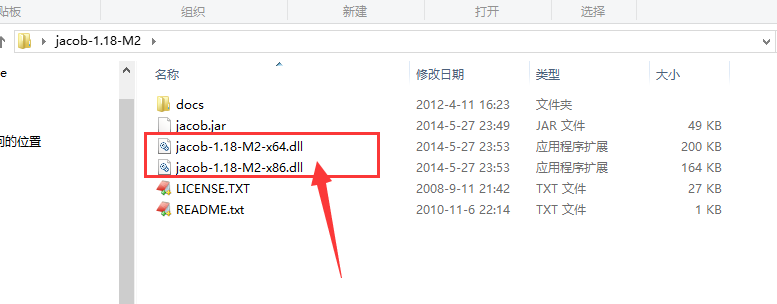
将其复制的位置分别是:
C:WindowsSystem32
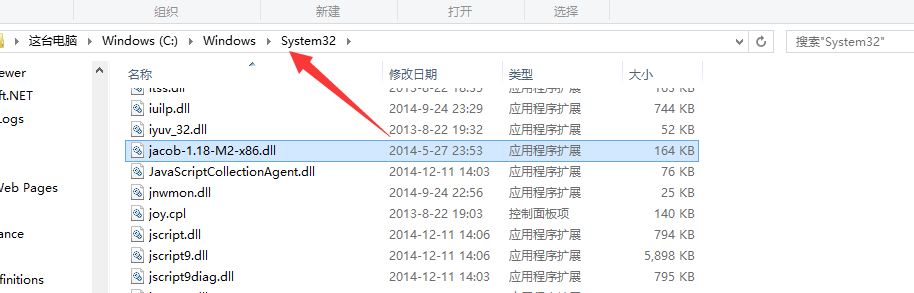
机器所安装的java目录下的jdk下的bin中
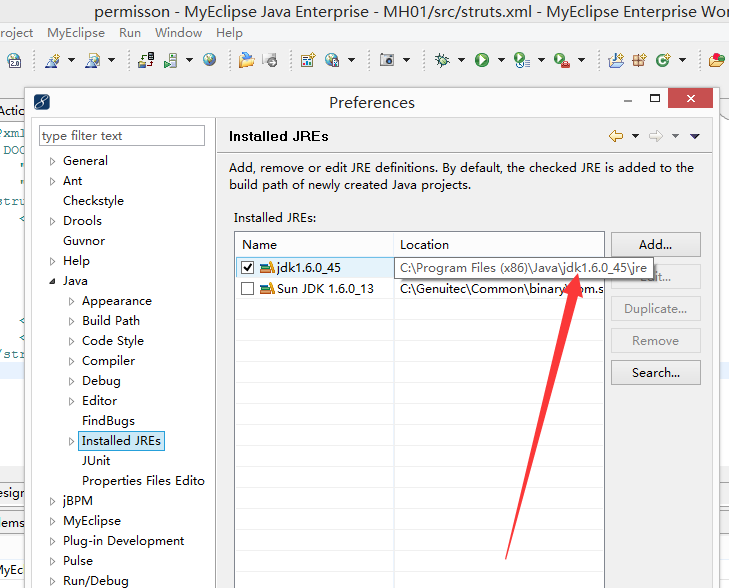
在myeclipse中指定jre
然后就是编码阶段:
导入相关的jar包,新建一个WordReader类,源码如下:
package com.mh.test; import com.jacob.activeX.ActiveXComponent; import com.jacob.com.Dispatch; import com.jacob.com.Variant; public class WordReader { public static void extractDoc(String inputFIle, String outputFile) { boolean flag = false; // 打开Word应用程序 ActiveXComponent app = new ActiveXComponent("Word.Application"); try { // 设置word不可见 app.setProperty("Visible", new Variant(false)); // 打开word文件 Dispatch doc1 = app.getProperty("Documents").toDispatch(); Dispatch doc2 = Dispatch .invoke(doc1, "Open", Dispatch.Method, new Object[] {inputFIle, new Variant(false), new Variant(true)}, new int[1]).toDispatch(); // 作为html格式保存到临时文件::参数 new Variant(8)其中8表示word转html;7表示word转txt;44表示Excel转html。。。 Dispatch.invoke(doc2, "SaveAs", Dispatch.Method, new Object[] {outputFile, new Variant(8)}, new int[1]); // 关闭word Variant f = new Variant(false); Dispatch.call(doc2, "Close", f); flag = true; } catch (Exception e) { e.printStackTrace(); } finally { app.invoke("Quit", new Variant[] {}); } if (flag == true) { System.out.println("Transformed Successfully"); } else { System.out.println("Transform Failed"); } } }
新建测试类,包含main方法:
package com.mh.test; public class TT { /** * @param args */ public static void main(String[] args) { WordReader.extractDoc("e:/f.docx","e:/ee.html"); } }
这里是将word转为html就算完成了,因此知道了,如果需要将word转为html就可以直接调用WordReader中的方法就可以实现。这里就不多说了。
2. 且说文件的上传,下载
这里是利用Struts2实现的上传功能,index页面中的源码:
<%@ page language="java" pageEncoding="utf-8"%> <%@ taglib uri="/struts-tags" prefix="s"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>文件上传</title> </script> </head> <body> <s:form action="upload" method="post" enctype="multipart/form-data"> <s:file name="upload" label="上传的文件" id="ufile"></s:file> <s:submit value="上传"></s:submit> </s:form> <div id="retShow"></div> </body> </html>
Struts.xml中的相关配置:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.0//EN" "http://struts.apache.org/dtds/struts-2.0.dtd"> <struts> <package name="default" extends="struts-default"> <action name="upload" class="com.mh.action.UploadAction"> <result name="success">/success.jsp</result> </action> <action name="*viewAction" class="com.mh.action.ViewAction" method="{1}"> </action> </package> <constant name="struts.multipart.saveDir" value="/tmp"></constant> </struts>
UploadAction的源码:
package com.mh.action; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import java.util.List; import javax.servlet.ServletContext; import javax.servlet.http.HttpServletRequest; import org.apache.struts2.ServletActionContext; import org.apache.struts2.util.ServletContextAware; import com.mh.test.WordReader; import com.opensymphony.xwork2.ActionSupport; public class UploadAction extends ActionSupport implements ServletContextAware { private List<File> upload; private List<String> uploadFileName; private ServletContext context; HttpServletRequest request = ServletActionContext.getRequest(); public HttpServletRequest getRequest() { return request; } public void setRequest(HttpServletRequest request) { this.request = request; } public String execute() throws Exception { String path = ""; if (upload != null) { for (int i = 0; i < upload.size(); i++) { System.out.println(upload.get(i).getPath() + "-----------------------------" + getUploadFileName().get(i)); InputStream is = new FileInputStream(upload.get(i)); path = context.getRealPath(getUploadFileName().get(i)); System.out.println(context.getRealPath(getUploadFileName().get(i)) + "=============="); String str = getUploadFileName().get(i); String view = getUploadFileName().get(i).replace(".docx", ".html"); request.setAttribute("str", str); request.setAttribute("view", view); OutputStream os = new FileOutputStream(context.getRealPath(getUploadFileName().get(i))); byte buffer[] = new byte[1024]; int count = 0; while ((count = is.read(buffer)) > 0) { os.write(buffer, 0, count); } os.close(); is.close(); } } System.out.println(path.replace("\", "/")+"&&&&&&&&&&&&"); System.out.println(path.replace("\", "/").replace(".docx", ".html")+"%%%%%%%%%%%%%"); WordReader.extractDoc(path.replace("\", "/"), path.replace("\", "/").replace(".docx", ".html")); return SUCCESS; } public List<File> getUpload() { return upload; } public void setUpload(List<File> upload) { this.upload = upload; } public List<String> getUploadFileName() { return uploadFileName; } public void setUploadFileName(List<String> uploadFileName) { this.uploadFileName = uploadFileName; } public void setServletContext(ServletContext context) { this.context = context; } }
ViewAction源码:
package com.mh.action; import javax.servlet.http.HttpServletRequest; import org.apache.struts2.ServletActionContext; import com.mh.test.WordReader; import com.opensymphony.xwork2.ActionSupport; public class ViewAction extends ActionSupport { private static final long serialVersionUID = 1814430419057331187L; HttpServletRequest request = ServletActionContext.getRequest(); public void UView() { String ufile = request.getParameter("upf"); System.out.println(ufile + "++++++++++++++++"); System.out.println(ufile.replace("\", "/") + "****************"); WordReader.extractDoc(ufile.replace("\", "/"), ufile.replace("\", "/").replace(".docx", ".html")); } }
在这里同时将上面实现的转换的功能加到模块中,只要上传就进行转换。在这里,我并没有设置上传后的文件路径,直接按默认的上传到ROOT目录下,下载的时候就按照最原始的方式,直接打开word文档的链接,浏览器就自动进行下载了,而在线预览实际上就是打开该文档生成的html文档的链接。十分方便,但是,这样做有一个弊端,需要随时注意文件的数量,如果文件过多会影响程序的运行和计算机的硬件水平,同时,如果该项目需要进行重新部署,以前上传的数据就没有了,这也是需要考虑的,本demo只是进行抛砖引玉的作用,更多地完善,拒绝伸手主义。始终坚信,动手时最好的学习方式,愿与君共勉!
实现效果如下:
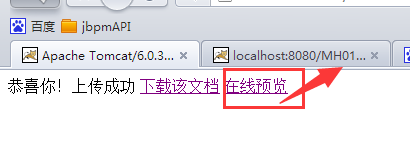
下载word文档:
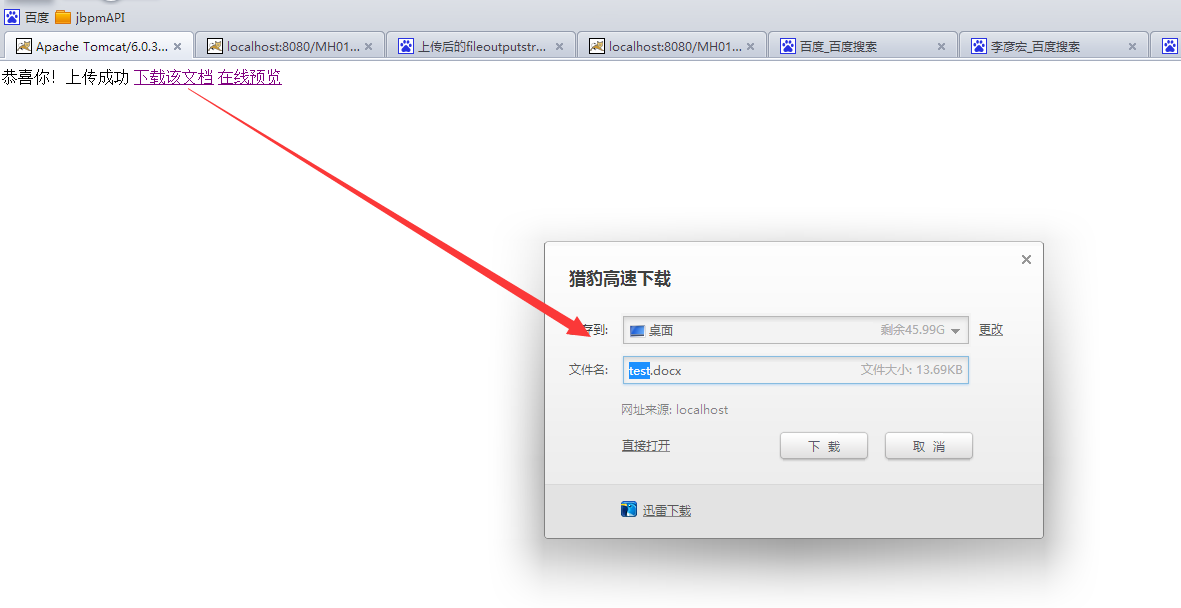
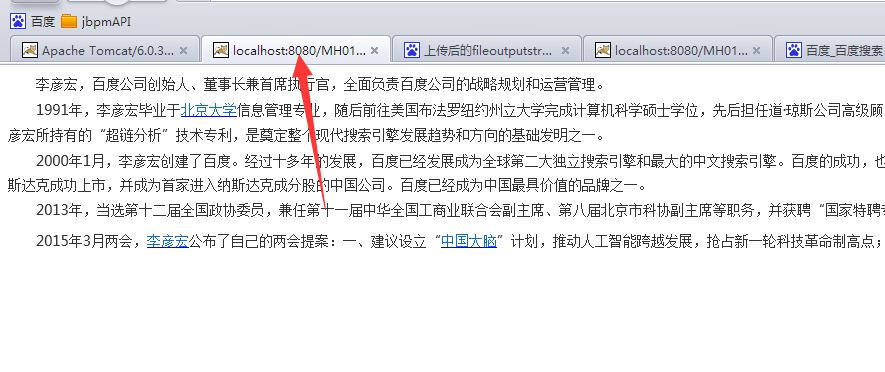
预览效果:
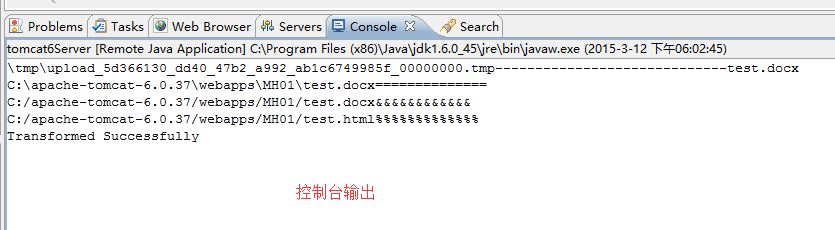
控制台输出:
-------------------------注意----------------------------
在文章前就说过,要想用好这个第三方的组件,就必须了解自己的计算机,然后根据实际情况配置好环境;在程序的实现过程中,就遇到一些常见错误:
(1) Open错误:说明没有找到指定路径下的word文档,要么就是路径中的斜杠写反了,本人犯错最多的地方;解决办法:配置并确认好路径后再进行运行;
(2)SaveAs错误:路径问题;解决办法同上。
(3)注意tomcat和jdk。
-------------------------------------------------------------------
探索,让人无悔;失败,令人思索;剩下的便是心平气和,专心致志,既不瞻前顾后,也不无目的地四面出击。
邮箱:it_red@sina.com
个人博客: http://itred.cnblogs.com 网站: http://wangxingyu.jd-app.com
版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。