Hibernate部分
1.为什么要使用Hibernate开发你的项目呢?Hibernate的开发流程是怎么样的?
为什么要使用
①.对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
②.Hibernate 是一个基于JDBC的主流持久化框架,是一个优秀的ORM 实现。他很大程度的简化DAO层的编码工作
③.hibernate 的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
开发流程

2.什么是延迟加载?
延迟加载机制是为了避免一些无谓的性能开销而提出来的,所谓延迟加载就是当在真正需要数据的时候,才真正执行数据加载操作。在Hibernate中提供了对实体对象的延迟加载以及对集合的延迟加载,另外在Hibernate3中还提供了对属性的延迟加载。
3.说一下hibernate的缓存机制
A:hibernate一级缓存
(1)hibernate支持两个级别的缓存,默认只支持一级缓存;
(2)每个Session内部自带一个一级缓存;
(3)某个Session被关闭时,其对应的一级缓存自动清除;
B:hibernate二级缓存
(1) 二级缓存独立于session,默认不开启;
4.Hibernate的查询方式有哪些?
本地SQL查询、Criteria、Hql
5.如何优化Hibernate?
1.使用双向一对多关联,不使用单向一对多 2.灵活使用单向一对多关联 3.不用一对一,用多对一取代 4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set 6. 继承类使用显式多态 7. 表字段要少,表关联不要怕多,有二级缓存撑腰
6.Hibernate中GET和LOAD的区别?
请注意如果没有匹配的数据库记录,load()方法可能抛出无法恢复的异常(unrecoverable exception)。 如果类的映射使用了代理(proxy),load()方法会返回一个未初始化的代理,直到你调用该代理的某方法时才会去访问数据库。若你希望在某对象中创建一个指向另一个对象的关联,又不想在从数据库中装载该对象时同时装载相关联的那个对象,那么这种操作方式就用得上的了。 如果为相应类映射关系设置了batch-size, 那么使用这种操作方式允许多个对象被一批装载(因为返回的是代理,无需从数据库中抓取所有对象的数据)。 如果你不确定是否有匹配的行存在,应该使用 get()方法,它会立刻访问数据库,如果没有对应的行,会返回null。
session.get 方法, 查询立即执行 , 返回Customer类对象
session.load 方法,默认采用延迟加载数据方式,不会立即查询,返回 Customer类子类对象 (动态生成代理对象)
* 如果 PO类使用final修饰,load无法创建代理对象,返回目标对象本身 (load效果和 get效果 相同 )
7.说说在 hibernate中使用Integer做映射和使用int做映射之间有什么差别?
Integer code和int code的区别:
Integer是对象. code=null; 对象可以为空.
int 是普通类型, 不可能=null.
根据你的数据库code是可以空的,故应该映射成Integer.
你没理由hbm.xml里写 Integer,类里却写int
8.SQL和HQL有什么区别?
sql 面向数据库表查询
hql 面向对象查询
hql:from 后面跟的 类名+类对象 where 后 用 对象的属性做条件
sql:from 后面跟的是表名 where 后 用表中字段做条件
查询
在Hibernate中使用查询时,一般使用Hql查询语句。
HQL(Hibernate Query Language),即Hibernate的查询语言跟SQL非常相像。不过HQL与SQL的最根本的区别,就是它是面向对象的。
使用HQL时需要注意以下几点:
1.大小写敏感
因为HQL是面向对象的,而对象类的名称和属性都是大小写敏感的,所以HQL是大小写敏感的。
HQL语句:from Cat as cat where cat.id > 1;与from Cat as cat where cat.ID > 1;是不一样的,这点与SQL不同。
2.from子句
from Cat,该句返回Cat对象实例,开发人员也可以给其加上别名,eg. from Cat as cat,对于多表查询的情况,可参考如下:
from Cat as cat, Dog as dog
其它方面都与SQL类似,在此不再赘述。
9.Hibernate的分页查询
例如:从数据库中的第20000条数据开始查后面100条记录
Query q = session.createQuery("from Cat as c");;
q.setMaxResults(100);;
List l = q.list();;
q.setFirstResult(20000);;
10.Hibernate中Java对象的状态以及对应的特征有哪些?
持久化对象的三种状态
持久化对象PO和OID
PO=POJO + hbm映射配置
编写规则
- ①必须提供无参数 public 构造器
- ②所有属性 private,提供 public的getter和setter方法
- ③必须提供标识属性,与数据表中主键对应 ,例如 Customer类 id属性
- ④PO类属性应尽量使用基本数据类型的包装类型(区分空值) 例如 int --- Integer long--- Long
- ⑤不要用final修饰(将无法生成代理对象进行优化)
OID 指与数据表中主键对应 PO类中属性,例如 Customer类 id属性
Hibernate框架使用OID来区分不同PO对象
* 例如内存中有两个PO对象,只要具有相同 OID, Hibernate认为同一个对象
* Hibernate 不允许缓存同样OID的两个不同对象
①瞬时态(临时态、自由态):不存在持久化标识OID,尚未与Hibernate Session关联对象,被认为处于瞬时态,失去引用将被JVM回收
②持久态:存在持久化标识OID,与当前session有关联,并且相关联的session没有关闭 ,并且事务未提交
③脱管态(离线态、游离态):存在持久化标识OID,但没有与当前session关联,脱管状态改变hibernate不能检测到
区分三种状态:判断对象是否有OID,判断对象是否与session关联(被一级缓存引用)
// 获得Session
Session session = HibernateUtils.openSession();
// 开启事务
Transaction transaction = session.beginTransaction();
Book book = new Book(); // 瞬时态(没有OID,未与Session关联)
book.setName("hibernate精通");
book.setPrice(56d);
session.save(book);// 持久态(具有OID,与Session关联)
// 提交事务,关闭Session
transaction.commit();
session.close();
System.out.println(book.getId()); // 脱管态(具有 OID,与Session断开关联)
11.Hibernate中怎样处理事务?
Hibernate是对JDBC的轻量级对象封装,Hibernate本身是不具备Transaction 处理功能的,Hibernate的Transaction实际上是底层的JDBC Transaction的封装,或者是JTA Transaction的封装,下面我们详细的分析:
Hibernate可以配置为JDBCTransaction或者是JTATransaction,这取决于你在hibernate.properties中的配置:
- #hibernate.transaction.factory_class net.sf.hibernate.transaction.JTATransactionFactory
- #hibernate.transaction.factory_class net.sf.hibernate.transaction.JDBCTransactionFactory
如果你什么都不配置,默认情况下使用JDBCTransaction,如果你配置为:
hibernate.transaction.factory_class net.sf.hibernate.transaction.JTATransactionFactory
将使用JTATransaction,不管你准备让Hibernate使用JDBCTransaction,还是JTATransaction,我的忠告就是什么都不配,将让它保持默认状态,如下:
- #hibernate.transaction.factory_class net.sf.hibernate.transaction.JTATransactionFactory
- #hibernate.transaction.factory_class net.sf.hibernate.transaction.JDBCTransactionFactory
在下面的分析中我会给出原因。
一、JDBC Transaction
看看使用JDBC Transaction的时候我们的代码例子:
- Session session = sf.openSession();
- Transaction tx = session.beginTransactioin();
- ...
- session.flush();
- tx.commit();
- session.close();
这是默认的情况,当你在代码中使用Hibernate的Transaction的时候实际上就是JDBCTransaction。那么JDBCTransaction究竟是什么东西呢?来
12.简单的介绍一下Hibernate的核心API?
1.Configuration
用于加载hibernate配置
①加载核心属性配置hibernate.properties和hibernate.cfg.xml
//方式一:去src 读取 hibernate.properties 属性配置文件
Configuration cfg = new Configuration();
//方式二:去src读取 hibernate.cfg.xml
Configuration cfg = new Configuration().configure();
Configuration cfg = new Configuration().configure("自定义xml文件"); 去src 加载指定文件
②手动加载hbm映射配置,持久化类与数据表的映射关系(*.hbm.xml 文件)
如果没有对PO类进行hbm映射,会报错 :
org.hibernate.MappingException: Unknown entity: cn.itcast.domain.Customer
那么我们可以手动加载其映射文件:
//方式一:
configuration.addResource("cn/itcast/domain/Customer.hbm.xml"); 加载hbm文件
//方式二:
configuration.addClass(Customer.class); 加载Class,自动搜索hbm映射文件
* 如果使用 hibernate.cfg.xml配置,将映射配置xml中 <mapping resource="cn/itcast/domain/Customer.hbm.xml"/>
2.SessionFactory
①保存了当前的数据库配置信息和所有映射关系以及预定义的SQL语句 这个对象是线程安全的
//预定义SQL语句
<sql-query name="login">
<![CDATA[select * from user where username= ? and password =?]]>
</sql-query>
3.Session
代表hibernate操作会话对象,相当于Connection
session是一个单线程对象,线程不安全(在方法内部定义和使用Session,不会出现线程问题)
* 每个线程方法调用栈,是线程私有的
session 进行PO(Persistent Object)对象常见持久化操作, 存在一级缓存
常用API
save 完成插入 update 完成修改 delete 完成删除 get/load 根据主键字段查询
createQuery、 createSQLQuery 创建查询对象 Query 接收HQL, SQLQuery 接收SQL
createCriteria() 面向对象条件查询
4.Transaction 事务操作 commit 提交 rollback 回滚
如果没有开启事务,那么每个Session的操作,都相当于一个独立的事务
* 事务是否提交
//默认false
<property name="hibernate.connection.autocommit">false</property> 事务不提交
<property name="hibernate.connection.autocommit">true</property> 事务提交
5.Query
session.createQuery()获得
面向对象查询,操作类,操作属性
接收参数 HQL语句
开发代码步骤
获得Hibernate Session对象
编写HQL语句
调用session.createQuery 创建查询对象
如果HQL语句包含参数,则调用Query的setXXX设置参数
调用Query对象的list() 或uniqueResult() 方法执行查询
6.Criteria 接口(QBC查询 Query By Criteria )
主要为了解决多条件查询问题,以面向对象的方式添加条件,无需拼接HQL语句
13.update与saveOrUpdate有什么区别?
save() 方法很显然是执行保存操作的,如果是对一个新的刚new出来的对象进行保存,自然要使用这个方法了,数据库中没有这个对象。
update() 如果是对一个已经存在的托管对象进行更新那么肯定是要使用update()方法了,数据中有这个对象。
saveOrUpdate() 这个方法是更新或者插入,有主键就执行更新,如果没有主键就执行插入。【此方法慎用】
在Hibernate中saveOrUpdate()方法在执行的时候,先会去session中去找存不存在指定的字段,如果存在直接update,否则save,这个时候问题就发生了。
有两张表,表A和表B,这两张表的主键都是一样的,例如都是MASTER_ID,同时对应的BO里面属性都是masterID,现在要执行的操作是,以MASTER_ID为条件将表A中的数据查询出来,然后将部分值插入到表B中,然后再更新表B,在查询表A后,session中已经存在masterID 了,这个时候再去对表B进行savaOrUpdate的时候,Hibernate会发现session中已经存在masterID了,所以执行的就是 update,但是实际上表B中根本不存在masterID这个值,当你执行完查询数据库的时候会发现没有插入数据,像这种情况,就得先用 masterID对表B进行查询,当返回的BO为NULL时,new一个新BO然后再进行插入,这个时候用到的就是createbo了。
14.Hibernate的inverse属性的作用?
1.明确inverse和cascade的作用
inverse 决定是否把对对象中集合的改动反映到数据库中,所以inverse只对集合起作用,也就是只对one-to-many或many-to-many有效(因为只有这两种关联关系包含集合,而one-to-one和many-to-one只含有关系对方的一个引用)。
cascade决定是否把对对象的改动反映到数据库中,所以cascade对所有的关联关系都起作用(因为关联关系就是指对象之间的关联关系)。
2.inverse属性 :inverse所描述的是对象之间关联关系的维护方式。
inverse只存在于集合标记的元素中 。Hibernate提供的集合元素包括<set/> <map/> <list/> <array /> <bag />
Inverse属性的作用是:是否将对集合对象的修改反映到数据库中。 inverse属性的默认值为false,表示对集合对象的修改会被反映到数据库中;inverse=false 的为主动方,由主动方负责维护关联关系。 inverse=”true” 表示对集合对象的修改不会被反映到数据库中。为了维持两个实体类(表)的关系,而添加的一些属性,该属性可能在两个实体类(表)或者在一个独立的表里面,这个要看这双方直接的对应关系了: 这里的维护指的是当主控放进行增删改查操作时,会同时对关联关系进行对应的更新。
一对多: 该属性在多的一方。应该在一方的设置 inverse=true ,多的一方设置 inverse=false(多的一方也可以不设置inverse属性,因为默认值是false),这说明关联关系由多的一方来维护。如果要一方维护关 系,就会使在插入或是删除"一"方时去update"多"方的每一个与这个"一"的对象有关系的对象。而如果让"多"方面维护关系时就不会有update 操作,因为关系就是在多方的对象中的,直指插入或是删除多方对象就行了。显然这样做的话,会减少很多操作,提高了效率。
注:单向one-to-many关联关系中,不可以设置inverse="true",因为被控方的映射文件中没有主控方的信息。
多对多: 属性在独立表中。inverse属性的默认值为false。在多对多关联关系中,关系的两端 inverse不能都设为false,即默认的情况是不对的,如果都设为false,在做插入操作时会导致在关系表中插入两次关系。也不能都设为 true,如果都设为true,任何操作都不会触发对关系表的操作。因此在任意一方设置inverse=true,另一方inverse=false。
一对一: 其实是一对多的一个特例,inverse 的设置也是一样的,主要还是看关联关系的属性在哪一方,这一方的inverse=false。
多对一: 也就是一对多的反过来,没什么区别。
3.cascade属性
级联操作:指当主控方执行某项操作时,是否要对被关联方也执行相同的操作。
cascade属性的作用是描述关联对象进行操作时的级联特性。因此,只有涉及到关系的元素才有cascade属性。具有cascade属性的标记包括<many-to-one /> <one-to-one /> <any /> <set /><bag /> <idbag /> <list /> <array />
注意:<one-to-many />和 <many-to-many />是用在集合标记内部的,所以是不需要cascade属性的。
4.inverse和cascade的区别
作用的范围不同:
Inverse是设置在集合元素中的。
Cascade对于所有涉及到关联的元素都有效。
<many-to-one/><ont-to-many/>没有inverse属性,但有cascade属性
执行的策略不同
Inverse 会首先判断集合的变化情况,然后针对变化执行相应的处理。
Cascade 是直接对集合中每个元素执行相应的处理
执行的时机不同
Inverse是在执行SQL语句之前判断是否要执行该SQL语句
Cascade则在主控方发生操作时用来判断是否要进行级联操作
执行的目标不同
Inverse对于<ont-to-many>和<many-to-many>处理方式不相同。
对于<ont-to-many>,inverse所处理的是对被关联表进行修改操作。
对于<many-to-many>,inverse所处理的则是中间关联表
Cascade不会区分这两种关系的差别,所做的操作都是针对被关联的对象。
总结:
<one-to-many>
<one-to-many>中,建议inverse=”true”,由“many”方来进行关联关系的维护
<many-to-many>中,只设置其中一方inverse=”false”,或双方都不设置
Cascade,通常情况下都不会使用。特别是删除,一定要慎重。
操作建议:
一般对many-to-one和many-to-many不设置级联,这要看业务逻辑的需要;对one-to-one和one-to-many设置级联。
many-to-many关联关系中,一端设置inverse=”false”,另一端设置为inverse=”true”。在one-to-many关联关系中,设置inverse=”true”,由多端来维护关系表
Hibernate一级缓存相关问题
1.Session中的一级缓存
Hibernate框架共有两级缓存, 一级缓存(Session级别缓存)、二级缓存(SessionFactory级别缓存)
在Session接口的实现中包含一系列的 Java 集合, 这些 Java 集合构成了 Session 缓存. 持久化对象保存Session一级缓存中(一级缓存引用持久化对象地址),只要 Session 实例没有结束生命周期, 存放在它缓存中的对象也不会结束生命周期
Hibernate Session接口的实现类SessionImpl类(查看源码,右击session,选择Open Type Hierarchy) ,里面有2个重要的字段:
* private transient ActionQueue actionQueue; ---- 行动队列(标记数据活动)
* private transient StatefulPersistenceContext persistenceContext; ---- 持久化上下文
当session的save()方法持久化一个对象时,该对象被载入缓存,以后即使程序中不再引用该对象,只要缓存不清空,该对象仍然处于生命周期中。当试图get()、 load()对象时,会判断缓存中是否存在该对象,有则返回,此时不查询数据库。没有再查询数据库
Session 能够在某些时间点, 按照缓存中对象的变化来执行相关的 SQL 语句, 来同步更新数据库, 这一过程被称为刷出缓存(flush)
* Transaction的commit()
* 应用程序执行一些查询操作时
* 调用Session的flush()方法
①验证一级缓存的存在
Book book = (Book) session.get(Book.class, 1); // 第一次查询,缓存中没有
System.out.println(book);
Book book2 = (Book) session.get(Book.class, 1);// 因为第一次查询,对象已经被放入1级缓存,不会查询数据
System.out.println(book2);
* 生成一条SQL语句,返回同一个对象 ,第一次查询生成SQL,查询对象,将对象放入一级缓存,第二次查询,直接从一级缓存获得
②测试Hibernate快照 (深入理解一级缓存内存结构原理)
hibernate 向一级缓存放入数据时,同时保存快照数据(数据库备份),当修改一级缓存数据,在flush操作时,对比缓存和快照,如果不一致,自动更新(将缓存的内容同步到数据库,更新快照)
* 快照区使用,在Session 保存一份与数据库相同的数据,在session的flush时, 通过快照区比较得知一级缓存数据是否改变,如果改变执行对应操作(update)
@Test
public void demo3() {
// 获得Session
Session session = HibernateUtils.openSession();
// 开启事务
Transaction transaction = session.beginTransaction();
// 查询id 为1 的图书对象
Book book = (Book) session.get(Book.class, 1); // 第一次查询,将对象加入一级缓存
System.out.println(book);
book.setName("深入浅出Hibernate技术"); // 修改书名(一级缓存被修改,自动update)
// 没有手动执行update,因为快照区原因,自动更新
// 提交事务,关闭Session
transaction.commit();
session.close();
}
使用Debug模式进行截图说明:
我们重点关注session中的2个属性actionQueue和persistenceContext
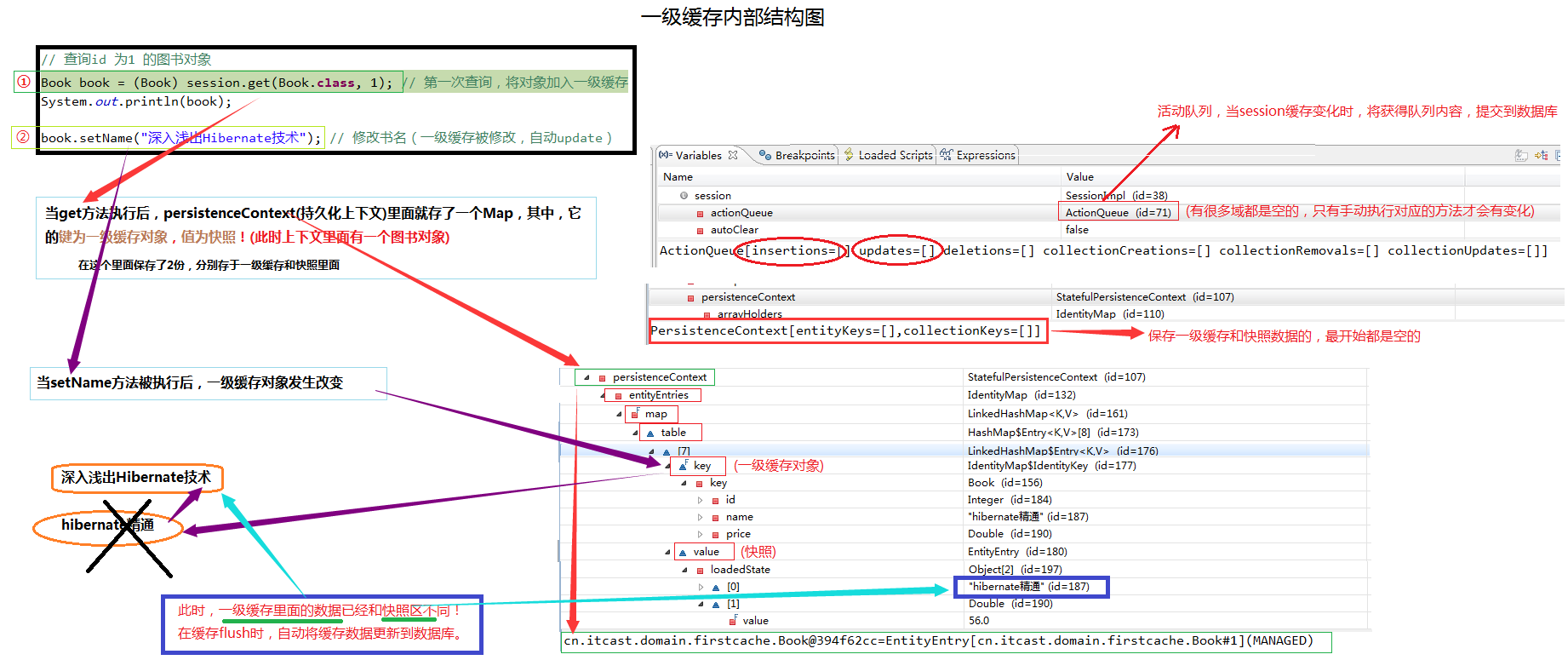
大白话解析:
**当执行get后,缓存里面有数据了,活动队列没有发生变化,说明没有需要提交到数据的内容,而PersistenceContext里面有内容了。
我们说,持久化上下文里面存放的是一个Map,它的键为一级缓存对象,值为快照(它是一级缓存对象的一个副本)。
**当执行setName后,一级缓存里面的数据发生了改变,在缓存flush时,会对比缓存和快照,如果不一致,那么会将缓存中的内容同步到数据库,并更新快照!
* Hibernate中 持久态 对象具有自动更新数据库能力 (持久态对象 才保存在 Session中,才有快照 )
2.一级缓存常见操作
所有操作需要使用断点调试才能看得比较清楚!
1)flush : 修改一级缓存数据针对内存操作,需要在session执行flush操作时,将缓存变化同步到数据库
* 只有在缓存数据与快照区不同时,生成update语句
2)clear : 清除所有对象 一级缓存 3)evict : 清除一级缓存指定对象 4)refresh :重新查询数据库,更新快照和一级缓存
3.一级缓存刷出时间点设置 (FlushMode)
ALWAYS :在每次查询时,session都会flush (不要求 )
AUTO : 在有些查询时,session会flush (默认) ---------- 查询、commit 、session.flush
COMMIT : 在事务提交时,session会flush ------- commit 、session.flush
MANUAL :只有手动调用 session.flush 才会刷出 ---- session.flush
刷出条件(时间点严格程度 )
MANUAL > COMMIT> AUTO> ALWAYS
4.session持久化对象操作方法
1) save 将数据保存到数据库 , 将瞬时对象转换持久对象
持久化对象,不允许随便修改 OID
2) update 更新数据 ,主要用于脱管对象的更新(持久对象,可以根据快照自动更新 ), 将脱管对象转换持久对象
问题一: 调用update,默认直接生成update语句,如果数据没有改变,不希望生成update
在hbm文件 <class>元素 添加 select-before-update="true"
<class name="cn.itcast.domain.firstcache.Book" table="book" catalog="hibernate3day2" select-before-update="true">
问题二: 当update,脱管对象变为持久对象, 一级缓存不允许出现相同OID 两个持久对象
问题三: 脱管对象 OID 在数据表中不存在,update时,发生异常
org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [cn.itcast.domain.firstcache.Book#20]
3) saveOrUpdate , 如果参数是一个瞬时对象执行save, 如果参数是一个脱管对象执行update, 如果参数是持久对象直接返回
判断对象是瞬时对象 : OID为null , 在hbm文件中为 <id>元素指定 unsaved-value属性,如果PO对象OID为 unsaved-value 也是瞬时对象
<id name="id" unsaved-value="-1"> 如果对象 OID为-1 也是瞬时对象,此时执行的是save操作
4) get/load
如果查询OID不存在, get方法返回 null , load 方法返回代理对象 (代理对象初始化时抛出 ObjectNotFoundException )
5) delete 方法既可以删除一个脱管对象, 也可以删除一个持久化对象
**如果删除脱管,先将脱管对象 与 Session 关联,然后再删除
**执行delete,先删除一级缓存数据,在session.flush 操作时,删除数据表中数据
Hibernate二级缓存相关问题
1.二级缓存的相关介绍
缓存好处: 将数据库或者硬盘数据,保存在内存中,减少数据库查询次数,减少硬盘交互,提高检索效率
hibernate 共有两个级别的缓存
* 一级缓存,保存Session中, 事务范围的缓存
* 二级缓存,保存SessionFactory ,进程范围的缓存
SessionFacoty 两部分缓存
内置 :Hibernate 自带的, 不可卸载. 通常在 Hibernate 的初始化阶段, Hibernate 会把映射元数据和预定义的 SQL 语句放到 SessionFactory 的缓存中, 映射元数据是映射文件中数据的复制, 而预定义 SQL 语句时 Hibernate 根据映射元数据推到出来的. 该内置缓存是只读的.
外置 :一个可配置的缓存插件. 在默认情况下, SessionFactory 不会启用这个缓存插件. 外置缓存中的数据是数据库数据的复制, 外置缓存的物理介质可以是内存或硬盘,必须引入第三方缓存插件才能使用。
2.二级缓存的内部结构以及存储特点
Hibernate二级缓存分为:
* 类缓存区域* 集合缓存区域* 更新时间戳区域 * 查询缓存区域

类缓存区数据存储特点
* 从二级缓存区返回数据每次地址都是不同的(散装数据 )。每次查询二级缓存,都是将散装数据构造为一个新的对象
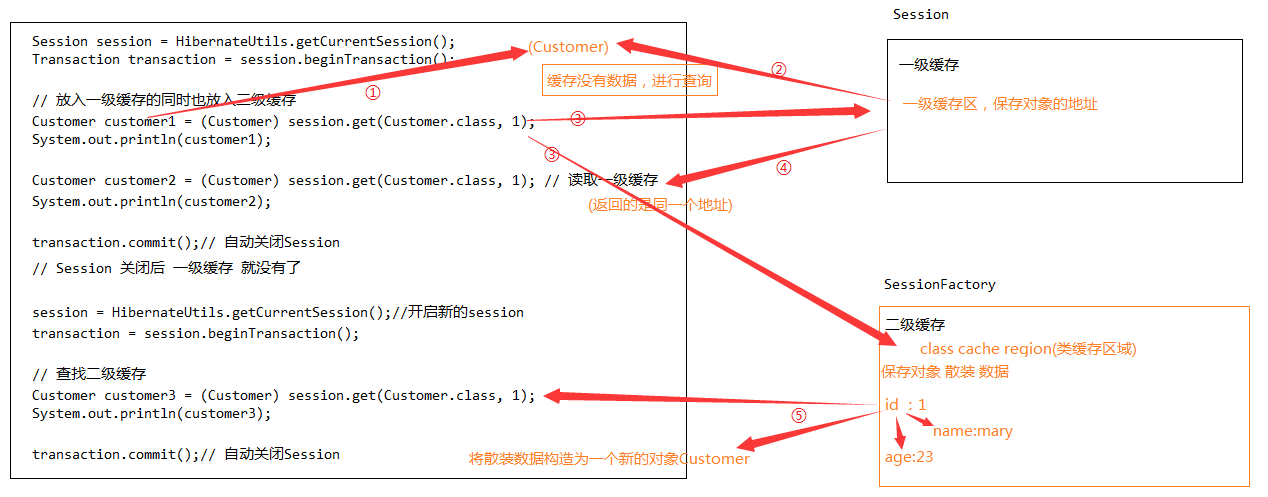
集合缓存区

如果注释掉 Order类缓存,orders 集合无法缓存
* 集合缓存区数据缓存依赖类缓存区数据缓存
** 一级缓存的操作会同步到二级缓存
更新时间戳区域
作用:记录数据最后更新时间,确保缓存数据是有效的
Hibernate 提供了和查询相关的缓存区域:
**时间戳缓存区域: org.hibernate.cahce.UpdateTimestampCache
时间戳缓存区域存放了对于查询结果相关的表进行插入, 更新或删除操作的时间戳. Hibernate 通过时间戳缓存区域来判断被缓存的查询结果是否过期, 其运行过程如下:
T1 时刻执行查询操作, 把查询结果存放在 QueryCache 区域, 记录该区域的时间戳为 T1
T2 时刻对查询结果相关的表进行更新操作, Hibernate 把 T2 时刻存放在 UpdateTimestampCache 区域.
T3 时刻执行查询结果前, 先比较 QueryCache 区域的时间戳和 UpdateTimestampCache 区域的时间戳, 若 T2 >T1, 那么就丢弃原先存放在 QueryCache 区域的查询结果, 重新到数据库中查询数据, 再把结果存放到 QueryCache 区域; 若 T2 < T1, 直接从 QueryCache 中获得查询结果。
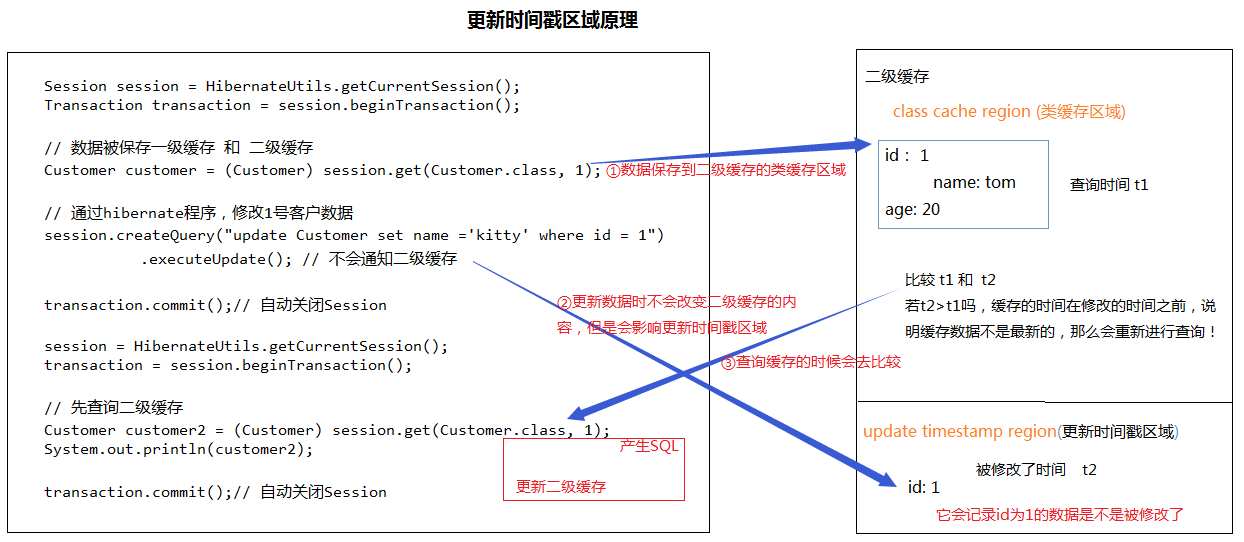
**更新时间戳区域,记录数据最后更新时间,在使用二级缓存时,比较缓存时间t1 与更新时间 t2 , 如果 t2 > t1 丢弃原来缓存数据,重新查询缓存
查询缓存
有人称查询缓存 为hibernate 第三级缓存
* 二级缓存缓存数据都是类对象数据,数据都是缓存在 "类缓存区域" ,二级缓存缓存PO类对象,条件(key)是id
查询缓存适用场合:
**应用程序运行时经常使用查询语句
**很少对与查询语句检索到的数据进行插入, 删除和更新操作
如果查询条件不是id查询, 缓存数据不是PO类完整对象 =====> 不适合使用二级缓存
查询缓存: 缓存的是查询数据结果, key是查询生成SQL语句 , 查询缓存比二级缓存功能更加强大
适用查询缓存的步骤
1)配置二级缓存(查询缓存依赖二级缓存)
2)启用查询缓存 hibernate.cfg.xml
<property name="hibernate.cache.use_query_cache">true</property>
3)必须在程序中指定使用查询缓存
query.setCacheable(true);
3.二级缓存的并发策略
transactional : 提供Repeatable Read事务隔离级别,缓存支持事务,发生异常的时候,缓存也能够回滚
read-write : 提供Read Committed事务隔离级别,更新缓存的时候会锁定缓存中的数据
nonstrict-read-write :导致脏读, 很少使用
read-only : 数据不允许修改,只能查询
* 很少被修改,不是很重要,允许偶尔的并发问题, 适合放入二级缓存。考虑因素(二级缓存的监控【后面学习】,它是是否采用二级缓存主要参考指标)
4.Hibernate支持哪些二级缓存技术?
* EHCache (主要学习,支持本地缓存,支持分布式缓存)
可作为进程范围内的缓存, 存放数据的物理介质可以是内存或硬盘, 对 Hibernate 的查询缓存提供了支持。
* OSCache
可作为进程范围内的缓存, 存放数据的物理介质可以是内存或硬盘, 提供了丰富的缓存数据过期策略, 对 Hibernate 的查询缓存提供了支持
* SwarmCache
可作为集群范围内的缓存, 但不支持 Hibernate 的查询缓存
* JBossCache
可作为集群范围内的缓存, 支持 Hibernate 的查询缓存