KNN是通过测量对象的不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
对象相似性衡量
在KNN中,将通过计算各个对象之间的距离来衡量其之间的相似性。
(1)欧几里得距离(欧氏距离)
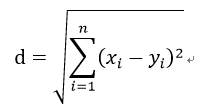
(2)曼哈顿距离(城市街区距离)
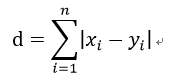
(3)切比雪夫距离

(4)Jaccard相似系数与Jaccard距离
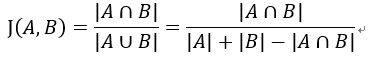
给定两个集合A,B,Jaccard系数定义为A与B交集的大小与A与B并集的大小的比值。当集合A,B都为空时, 定义为1。
Jaccard距离用于描述集合之间的不相似度。Jaccard 距离越大,样本相似度越低。
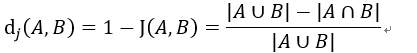
(5)相关系数

其中, 表示协方差, 表示方差。
(6)马氏距离
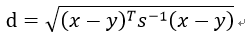
其中, 是协方差矩阵。
其表示数据的协方差距离,是一种与尺度无关的度量方式。其会将样本的各个特征标准化,再计算样本间的距离。
(7)夹角余弦

余弦相似度使用特征空间两个特征向量夹角的余弦值作为衡量差异的大小。余弦值越接近1,说明特征向量夹角越接近0°,两个特征向量越相似。
计算过程
①得到训练样本及其对应类别。
②计算某个待测样本与各个训练样本之间的距离
③对距离进行升序
④考察前k个距离中,对应训练样本出现次数最多的为该待测样本的距离。