《一步步搭建自己的博客》 源码地址 :http://www.cnblogs.com/zhaopei/p/4737958.html 如果你也在学习,请私密或者留言,欢迎一切学习总结,分享!
首先我从导数据开始 ------- 一切的源头
AdminHelperController index view中的 :
$.post("http://" + location.host + "/" + $("#iszf").attr("checked") + "/AdminHelper/butOk/" + $("#user").val(),
标识 post的地址 : Request URL:http://localhost:49532/checked/AdminHelper/butOk/zhaopei //这里的checked参数 ?
注意 :
location.host 包含端口,比如是 127.0.0.1:81。如果端口是 80,那么就没有端口,就是 127.0.0.1。
location.hostname 不包含端口,比如是 127.0.0.1。
根据上面的代码 : 发现 post执行的 Controller 与 Action 分别是 : AdminHelper/butOk 对应的 路由应该是 :
//第四种情况:以 域名 + 用户名
routes.MapRoute(
name: "UserIndex",
url: "{name}/{controller}/{action}/{id}",
defaults: new { action = "UserBlogList", controller = "UserBlog", id = UrlParameter.Optional }
);
然而 butOk 内部调用的是 :Import方法 ,这个方法比较复杂待我好好研读!
进入 Import 方法后发现 博主拼接了 url 这里以我自己的博客为例 :http://www.cnblogs.com/izhiniao/mvc/blog/sidecolumn.aspx 感兴趣的可以单机进去看看 ,可以帮助理解! 然而Import中结尾包含 下面这段代码 ,我想应该是把数据 存如数据库
var modelMyBlogs = new ModelDB.Blogs()
{
BlogContent = blogcontext,
BlogCreateTime = blogtime,
BlogTitle = blogtitle,
BlogUrl = blogurl,
IsDel = false,
BlogTags = myBlogTags,
BlogTypes = myBlogTypes,
UsersId = GetUserId(userName),
BlogForUrl = blogurl,
IsForwarding = iszf == "checked"
};
blog.Add(modelMyBlogs);
blog.save();
那么 下面 的这段代码 背后隐藏写什么呢 ? 我先来个猜想 , 后续联系博主待证实......?
blog.Add(modelMyBlogs);
猜想 :F12 过去


这里我标出的“需要注意” 主要是Model1Container 是数据库的网关类 ,crud都是统一入口, 继承自 DbContext 这里有篇博客介绍了 ObjectContext
DbContext 和ObjectContext两者的区别 : ObjectContext是一种模型优先的开发模式,DbContext是代码优先的开发模式 , 还可以相互转换!
最后 save()是这样构造的 :这里才进行数据库操作(顺便提提 上面的 add(model)是生存sql语句 )
public int save()
{
return db.SaveChanges();
}
这个类暂时解说到这里,对HtmlAgilityPack的理解 自行找资料(不过后期我会开博客写写HtmlAgilityPack) , 其实国人开发的 Jumony 更好用
2015-09-06 今天看看数据库 , 把数据库关系给大概理清晰
有三个暂时未知干嘛,别的根据数据很快就能看出来,这里我直接上图
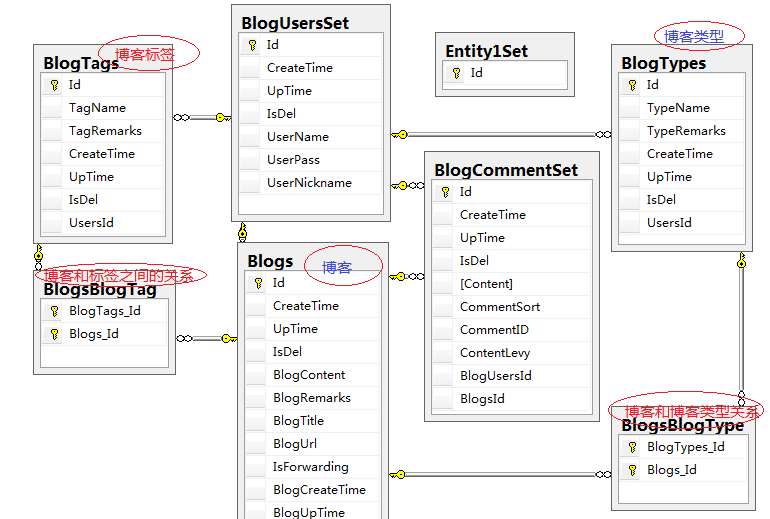
既然前面我们把数据给写入到数据库了,那么接下来我就去看看 博主是怎么把数据给显示出来的 ...
那么我们首先来从 Blogs.Web 开始 往数据方向一步一步去推导 ...
HomeController 下的 Index() 就是 博客view对应的action 方法 , 这个方法 里面第一行代码是 BLL.BlogsBLL blog = new BLL.BlogsBLL(); 创建了一个逻辑Blogs类,
具体怎么处理 , 背后隐藏了些什么 (这是三层中的逻辑层,待我稍后细细分析) , 我先看看 下面的代码 :
var bloglist = blog.GetList(t => t.Id < 50)//我本人对Lamda表达式不熟练,到时候我单独写一篇关于lamda表达式的文章,在对这里做个解析
.Select(t => new
{
Id = t.Id,
BlogTitle = t.BlogTitle,
BlogContent = t.BlogContent,
UserName = t.Users.UserName,
UserNickname = t.Users.UserNickname,
BlogCreateTime = t.BlogCreateTime
})
.ToList()
.Select(t => new ModelDB.Blogs()
{
Id = t.Id,
BlogTitle = t.BlogTitle,
BlogContent = MyHtmlHelper.GetHtmlText(t.BlogContent),
BlogCreateTime = t.BlogCreateTime,
Users = new ModelDB.BlogUsers()
{
UserName = t.UserName,
UserNickname = t.UserNickname
},
}).ToList();
这里的 bloglist 就是博客文章清单 ,然后把这个清单放入 数据字典中 供view 强类型解析
Dictionary<string, object> dic = new Dictionary<string, object>();
这里的 CacheData.GetUserInfo() 是获得用户信息,博主这里用的缓存(本人水平有限,暂时还没有设计到缓存,以后在细说缓存)
对于view中的代码我就解析几个有意思的地方
<a href="~/@(blog.Users.UserName)/@(blog.Id).html">@blog.BlogTitle</a>
这个 条 语句生成的html代码是 : <a href="/zhaopei/12.html">一步步开发自己的博客 .NET版(3、注册登录功能)</a>
所以它对应的 路由大概是 :
//第一种情况:以 域名 + 用户名 + id + html 后缀组合(默认控制器)
routes.MapRoute(
name: "UserPage",
url: "{name}/{id}.html/{controller}/{action}",
defaults: new { action = "UserBlog", controller = "UserBlog", name = "zhaopei", id = 1 }
);
对于获取所有博客的用户信息 做的缓存 我这里分析下 :
/// <summary>
/// 获取所有博客的用户信息
/// </summary>
/// <param name="newCache">是否重新获取</param>
/// <returns></returns>
public static List<BlogUsers> GetUserInfo(bool newCache = false)
{
if (null == HttpRuntime.Cache["UserInfo"] || newCache)
{
BLL.BlogUsersBLL user = new BlogUsersBLL();
HttpRuntime.Cache["UserInfo"] = user.GetList(t => true).ToList();
}
return (List<BlogUsers>)HttpRuntime.Cache["UserInfo"];
}
根据代码可以看出 首先判断缓存是否存在和是否从新获得缓存 , 如果不为空 我们就返回缓存-----那么问题又来了,我们第一次的缓存从那里获得呢 ?
这里只能待 博主来回答了 ,我暂时不得而知 。。。。(这个问题待我今天从新看 , 秒懂 ,昨天这么就没看出来呢 )
当 null == HttpRuntime.Cache["UserInfo"] 时 就获取啊 (这不就是第一次获取吗 , 自己SB ^_^ ) HttpRuntime.Cache["UserInfo"] = user.GetList(t => true).ToList();
下面这段代码主要是 实现内容过长而隐藏 ...
@Html.Raw(blog.BlogContent.Substring(0, con_length))
2.下面就是用户单击 博客标题后进入博客内容的实现 UserBlogController /UserBlog:
public ActionResult UserBlog(string name, int id)
{
BLL.BlogsBLL blog = new BLL.BlogsBLL();
var blogobj = blog.GetList(t => t.Id == id && t.Users.UserName == name).FirstOrDefault();
//这里看 能不能只查询一次
var blogNext = blog.GetList(t => t.Id > id && t.Users.UserName == name).OrderBy(t => t.Id).FirstOrDefault();
var blogLast = blog.GetList(t => t.Id < id && t.Users.UserName == name).OrderBy(t => t.Id).FirstOrDefault();
var commentList = blogobj.BlogComment.ToList();
Dictionary<string, object> dic = new Dictionary<string, object>();
dic.Add("blog", blogobj);
dic.Add("blogNext", blogNext);
dic.Add("blogLast", blogLast);
dic.Add("commentList", commentList);//对应的评论
dic.Add("contentBlogType", blogobj.BlogTypes.ToList());
dic.Add("contentBlogTag", blogobj.BlogTags.ToList());
SetDic(dic, name);
return View(dic);
}
看到这段代码我就理解了,就不需要进行详细的讲解,如果你不懂,可以在下面进行留言,写明情况我有时间会回复你!
弄到这里我本来想看看博主的这个博客系统 的资源是怎么放置的 , 第一版发现 图片链接都是直接调用 博客园的 链接
对于标签问题(这里只截了部分代码)
<a href="~/@(blogName)/GetTagBlogs/@(item.Id).html" >
发现匹配的 路由是 :
//第二种情况:以 域名 + 用户名 + action + id + html 后缀组合
routes.MapRoute(
name: "UserTagOrType",
url: "{name}/{action}/{id}.html/{controller}",
defaults: new { action = "UserBlogList", controller = "UserBlog" }
);
今天就解读到这里 , 下次解读异常处理!
现在开始继续读代码 : 这里先把昨天的遗留的问题给提下 , 已经解决 , 楼下的 游戏世界 也问了 , 由于博主时间有限 , 我就自己在认真的找了下 , 秒懂 , 上面的红体部分给出解析
那么接下来我就 研读下异常处理吧 , 因为我没自己搭建过项目 , 所以不懂, 就从博主的开始 ,至于他的处理方式好不好,我在文章中不做什么解析(我自己没这能力去评价,不过你觉得你的方法好,可以指点下我,小弟在这谢谢您了)
/// 全局未处理异常捕获
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
protected void Application_Error(object sender, EventArgs e)
{
#region 异常注释
Exception ex = Server.GetLastError().GetBaseException();
ErrLog.ErrLogSave(ex);
string strErr = ErrLog.GetExceptionInfo(ex);
//处理完及时清理异常
Server.ClearError();
#endregion
//Application_Error 里不能访问和操作 session为null 20150205
//HttpContext.Current.Session
//Context.Session
#region 跳转至出错页面
//跳转至出错页面
//Server.Transfer("~/html/500.aspx");
//注意:如果是ajax的请求 是不能 Response.Redirect 重定向的
string sheader = Context.Request.Headers["X-Requested-With"];
bool isAjax = (sheader != null && sheader == "XMLHttpRequest") ? true : false;
if (isAjax)
{
HttpContext.Current.Response.Write(
new CustomModel.JSData()
{
State = CustomModel.EnumState.异常或Session超时,
JSurl = "/html/500.html?err=" + Microsoft.JScript.GlobalObject.escape(strErr)//System.Web.HttpUtility.UrlEncode(strErr)
}.ToJson());
}
else
Response.Redirect("~/html/500.html?err=" + Microsoft.JScript.GlobalObject.escape(strErr));
#endregion
}
按F12 走了个大体流程我觉得有必要专门写一篇 关于 异常在这个博客系统中的应用 !
那么本篇文章到此结束 , 如果你感兴趣请继续阅读下篇 http://www.cnblogs.com/izhiniao/p/4790149.html
本文以学习、研究和分享为主,版权归作者和博客园共有,未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接 http://www.cnblogs.com/izhiniao,否则保留追究法律责任的权利