来源:https://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php
参考:https://unicode-table.com/cn/

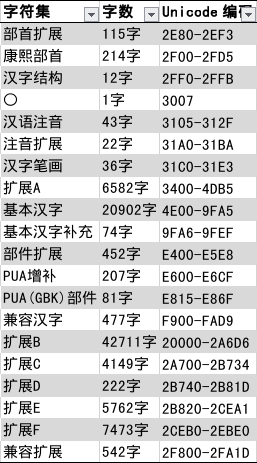
# 有拼音的汉字 if SUPPORT_UCS4: RE_HANS = re.compile( r'^(?:[' r'u3007' # 〇 r'u3400-u4dbf' # CJK扩展A:[3400-4DBF] r'u4e00-u9fff' # CJK基本:[4E00-9FFF] r'uf900-ufaff' # CJK兼容:[F900-FAFF] r'U00020000-U0002A6DF' # CJK扩展B:[20000-2A6DF] r'U0002A703-U0002B73F' # CJK扩展C:[2A700-2B73F] r'U0002B740-U0002B81D' # CJK扩展D:[2B740-2B81D] r'U0002F80A-U0002FA1F' # CJK兼容扩展:[2F800-2FA1F] r'])+$' ) else: RE_HANS = re.compile( # pragma: no cover r'^(?:[' r'u3007' # 〇 r'u3400-u4dbf' # CJK扩展A:[3400-4DBF] r'u4e00-u9fff' # CJK基本:[4E00-9FFF] r'uf900-ufaff' # CJK兼容:[F900-FAFF] r'])+$' )
def _is_chinese_char(self, cp): """Checks whether CP is the codepoint of a CJK character.""" # This defines a "chinese character" as anything in the CJK Unicode block: # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block) # # Note that the CJK Unicode block is NOT all Japanese and Korean characters, # despite its name. The modern Korean Hangul alphabet is a different block, # as is Japanese Hiragana and Katakana. Those alphabets are used to write # space-separated words, so they are not treated specially and handled # like the all of the other languages. if ((cp >= 0x4E00 and cp <= 0x9FFF) or # (cp >= 0x3400 and cp <= 0x4DBF) or # (cp >= 0x20000 and cp <= 0x2A6DF) or # (cp >= 0x2A700 and cp <= 0x2B73F) or # (cp >= 0x2B740 and cp <= 0x2B81F) or # (cp >= 0x2B820 and cp <= 0x2CEAF) or (cp >= 0xF900 and cp <= 0xFAFF) or # (cp >= 0x2F800 and cp <= 0x2FA1F)): # return True return False