浅谈Java线程池
线程池,简单来说,就是一个池子嘛,里面养着一群线程,ABCD........,然后你要用的时候,从里面拿一个去用,用完放回去。
一群人要用的时候,每个人都从池子里面拿一个线程,当池子的线程已经被拿完的时候,但是有人没有拿到线程,如果没有超过池子的最大承受量,池子就创造一些线程给未拿到线程的人用,否则这群人就在队伍里乖乖排队等着,等别人用完线程放回池子里,再去拿。
通过重用池子中的线程,可以在处理多个请求时分摊在线程创建和销毁过程中产生的巨大开销,在池子线程数足够时,也不会由于在等待创建线程过程中而延迟任务的执行。
当然,池子有很多种,放的线程的特点也不一样,常用的有:
- newFixedThreadPool( )
- newSingleThreadExecutor( )
- newCachedThreadpoll( )
- newSingleThreadScheduledExecutor( )
- newScheduledThreadPool( )
小试牛刀:
现假设有10个任务并发操作,来操作Java自带的几种线程池:
先创建一个Test类,做好准备工作:
public static class Test implements Runnable{ @Override public void run() { System.out.println(System.currentTimeMillis()+":Thread ID:"+Thread.currentThread().getId()); try { Thread.sleep(1000); } catch (Exception e) { e.printStackTrace(); } } public void sub(ExecutorService es) {//对10个任务进行并发操作 for (int i = 0; i < 10; i++){ es.submit(this); } }}
newFixedThreadPool( ) :返回一个固定数量线程的线程池,池子里面的线程数量不会变。池子中若有空闲线程,则立即执行任务,没有则在队列中等待有空闲的线程。
Test test =new Test(); ExecutorService es1=Executors.newFixedThreadPool(5);//通过Executors来创建newFixedThreadPool,并线程池里有指定数量的线程(5) test.sub(es1); es1.shutdown(); /*输出结果: * 1513172016629:Thread ID:10 1513172016630:Thread ID:11 1513172016630:Thread ID:12 1513172016630:Thread ID:13 1513172016630:Thread ID:14 1513172017630:Thread ID:10 1513172017631:Thread ID:11 1513172017631:Thread ID:12 1513172017632:Thread ID:13 1513172017632:Thread ID:14 * 可以看到10个任务执行结果,是前5个后5个各一组(ID从10到14)的执行的,分成两个批。因为池子里只有5个线程,前5个占用了并执行花了1s,后5个任务就得等待多1s。 * */
newSingleThreadExecutor( ):返回只有一个线程的线程池。大于一个任务的时候,其他任务就在对列中等待。
ExecutorService es2=Executors.newSingleThreadExecutor();//整个池子中只有一个线程可用 test.sub(es2); es2.shutdown(); /*输出结果: * 1513172019633:Thread ID:15 1513172020634:Thread ID:15 1513172021634:Thread ID:15 1513172022634:Thread ID:15 1513172023634:Thread ID:15 * 只有一个线程,每次只有一个任务执行并花费1s时间,执行完后放回池子,等待下一个任务执行。线程是同一个,所以是同一个ID。 * * */
newCachedThreadpool( ):返回一个可根据实际情况调整线程数量的线程池。里面的线程数量不确定,若有空闲线程可复用,则不着急创建新线程,否则创建新的线程处理任务。
ExecutorService es3=Executors.newCachedThreadPool();//当线程池中线程不够用的时候,会创建新的线程。 test.sub(es3); es3.shutdown(); /*输出结果 * 1513172129987:Thread ID:10 1513172129987:Thread ID:11 1513172129988:Thread ID:12 1513172129988:Thread ID:13 1513172129988:Thread ID:14 1513172129988:Thread ID:15 1513172129989:Thread ID:16 1513172129989:Thread ID:17 1513172129990:Thread ID:18 1513172129990:Thread ID:19 * 当下时刻(1s内),线程都在工作中,所以没有空闲的线程来给其他任务用,所以池子会不断创建新的线程用于执行任务。 * */
newScheduledThreadPool( ):返回一个可指定线程数量的ScheduledExecutorService对象,可在某个固定延时之后执行或者周期性执行某个任务。
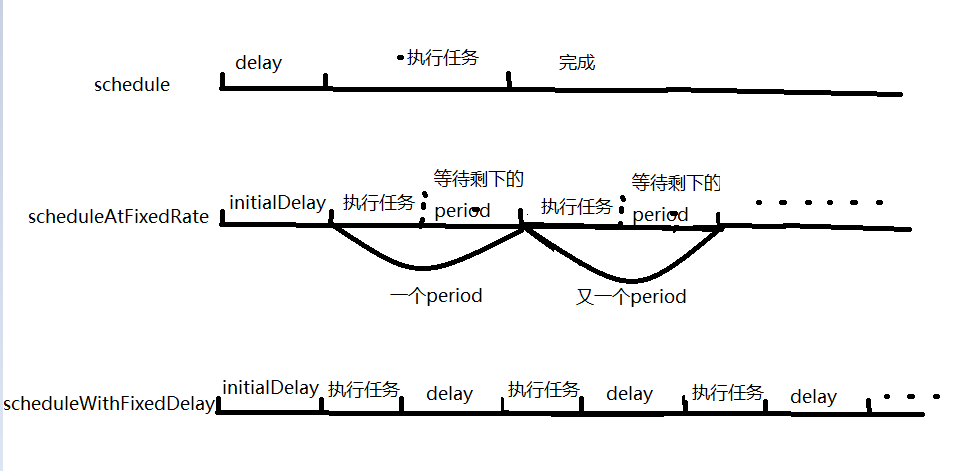
ScheduledExecutorService对象的几个主要方法,其中 delay:开始指定的延时时间,initialDelay:初始化延时(以后每一个任务的间隔延时),period:周期 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
对几个方法写一个eg,来看看他们的功能(这里主要看输出结果的时间差):
schedule方法:
1 ScheduledExecutorService ses=Executors.newScheduledThreadPool(10); 2 System.out.println("线程开始时间:"+System.currentTimeMillis()/1000); 3 ses.schedule(new Runnable() { 4 5 @Override 6 public void run() { 7 System.out.println(System.currentTimeMillis()/1000+":Thread ID:"+Thread.currentThread().getId()); 8 try { 9 Thread.sleep(1000); 10 } catch (Exception e) { 11 e.printStackTrace(); 12 } 13 } 14 }, 2, TimeUnit.SECONDS); 15 16 17 /* schedule会在给定时间,只对任务进行一次调度,这里设定两秒后执行 18 * 输出结果: 19 * 线程开始时间:1513174768 20 * 1513174770:Thread ID:10 21 */
scheduleAtFixedRate方法:
1 ses.scheduleAtFixedRate(new Runnable() { 2 3 @Override 4 public void run() { 5 System.out.println(System.currentTimeMillis()/1000+":Thread ID:"+Thread.currentThread().getId()); 6 try { 7 Thread.sleep(1000); 8 } catch (Exception e) { 9 e.printStackTrace(); 10 } 11 } 12 }, 3, 2, TimeUnit.SECONDS); 13 /* scheduleAtFixedRate会在给定延时initialDlay后(这里3秒),执行完一个任务(1秒),如果执行任务的时间大于周期period的时间,则执行完任务后直接到下一个任务;否则在周期内,任务执行完后,等待周期内剩余的时间。 14 * 输出结果: 15 * 线程开始时间:1513174386 16 1513174389:Thread ID:10 17 1513174391:Thread ID:10 18 1513174393:Thread ID:12 19 1513174395:Thread ID:10 20 1513174397:Thread ID:13 21 1513174399:Thread ID:12 22 * */
scheduleWithFixedDelay方法:
1 ses.scheduleWithFixedDelay(new Runnable() { 2 3 @Override 4 public void run() { 5 System.out.println(System.currentTimeMillis()/1000+":Thread ID:"+Thread.currentThread().getId()); 6 try { 7 Thread.sleep(1000); 8 } catch (Exception e) { 9 e.printStackTrace(); 10 } 11 } 12 }, 3, 2, TimeUnit.SECONDS); 13 /*scheduleWithFixedDelay会在给定延时initialDelay后(这里3秒),然后执行完一个任务(1秒),再间隔一个delay(2秒)后,再去执行别的任务 14 * 输出结果: 15 * 线程开始时间:1513174575 16 1513174578:Thread ID:10 17 1513174581:Thread ID:10 18 1513174584:Thread ID:12 19 1513174587:Thread ID:10 20 1513174590:Thread ID:13 21 * */
可以看图帮助更好的理解这3个方法:
针对这几个线程池做了一个测试,大概了解了他们的运作方式,接下来我们来看看他们的内部实现原理。
一探究竟——内部实现:
这里给出3个简单的线程池的内部实现原理:
1 public static ExecutorService newFixedThreadPool(int nThreads) { 2 return new ThreadPoolExecutor(nThreads, nThreads, 3 0L, TimeUnit.MILLISECONDS, 4 new LinkedBlockingQueue<Runnable>()); 5 } 6 public static ExecutorService newSingleThreadExecutor() { 7 return new FinalizableDelegatedExecutorService 8 (new ThreadPoolExecutor(1, 1, 9 0L, TimeUnit.MILLISECONDS, 10 new LinkedBlockingQueue<Runnable>())); 11 } 12 public static ExecutorService newCachedThreadPool() { 13 return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 14 60L, TimeUnit.SECONDS, 15 new SynchronousQueue<Runnable>()); 16 }
他们都返回一个ThreadPoolExecutor对象,只不过他们的参数不同罢了,来了解一下ThreadPoolExecutor具体的参数
1 public ThreadPoolExecutor(int corePoolSize, 2 int maximumPoolSize, 3 long keepAliveTime, 4 TimeUnit unit, 5 BlockingQueue<Runnable> workQueue, 6 ThreadFactory threadFactory, 7 RejectedExecutionHandler handler) { 8 if (corePoolSize < 0 || 9 maximumPoolSize <= 0 || 10 maximumPoolSize < corePoolSize || 11 keepAliveTime < 0) 12 throw new IllegalArgumentException();//这些参数强制不能小于0,否则抛异常 13 if (workQueue == null || threadFactory == null || handler == null) 14 throw new NullPointerException();//这些参数强制不能为空,否则抛异常 15 this.corePoolSize = corePoolSize; 16 this.maximumPoolSize = maximumPoolSize; 17 this.workQueue = workQueue; 18 this.keepAliveTime = unit.toNanos(keepAliveTime); 19 this.threadFactory = threadFactory; 20 this.handler = handler; 21 }
我们来看下方法里面的参数:- int corePoolSize, 核心线程数,就是制定了池子中的线程数量
- int maximumPoolSize,线程池中线程最大容量数
- long keepAliveTime,当线程数超过corePoolSize时,超过的那部分线程的剩余存活时间。
- TimeUnit unit,keepAliveTime的单位
- BlockingQueue<Runnable> workQueue,任务队列,下面详细介绍
- ThreadFactory threadFactory,线程工厂,用于创建线程,下面介绍
- RejectedExecutionHandler handler,拒绝策略,下面详细介绍
关于任务队列:
workQueue,就是在那些没有在池子拿到线程的,还在排队的任务所在的队列。这些队列都是一个BlockingQueue接口的对象,主要有以下几种:
直接提交队列:
SynchronousQueue实现,没有具体的容量大小,每一个插入操作都对应等待一个删除操作,每一个删除操作都对应等待一个插入操作,队列不会真实的保存任务,而是直接转交给线程去执行。
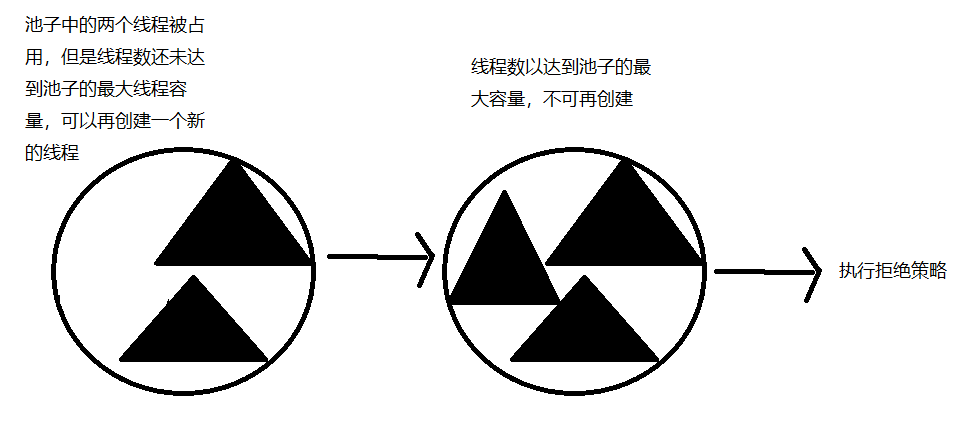
工作流程如下:将新任务提交给线程执行,如果池子中的线程被用完了,就尝试让池子创建线程,如果池子已经达到最大容量,不可再创建了,就执行拒绝策略(如果池子最大容量太小,则会很容易执行拒绝策略)。
newCachedThreadPool()就是用这种方式的,核心线程设置为0,maximumPoolSize设置为无穷大,这样当没有任务时,则池子里没有线程;当有任务时,若有空闲线程则使用,若无则加入SynchronousQueue队列,而这直接提交队列会迫使线程池增加新的线程去执行任务,如果任务很多又执行的很慢。。。。那就GG了,这样下去会耗尽内存。。。
有界任务队列:
ArrayBlockingQueue(int capacity)实现,参数capacity是队列的最大容量。
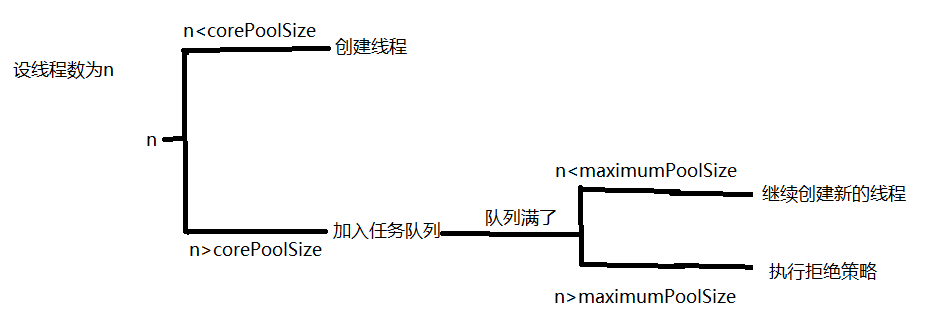
工作流程如下:将新任务提交给线程执行,如果池子里的线程数小于核心线程数,则会创建线程;否则将任务加入队列中;若队列已经满了,则就创建新的线程,直到maximumPoolSize为止;若超过了maximumPoolSize,就会执行拒绝策略了。
无界任务队列:
LinkedBlockingQueue实现,与有界队列相比,除非系统资源耗尽,否则此队列不存在入队失败。
工作流程如下:将新任务提交给线程执行,如果池子线程数小于核心线程数,池子会新生成线程去执行任务;当线程数到达核心线程数的时候,池子里的线程不再增加,若无空闲线程,则把任务放到任务队列里,队列一直增长,直到内存耗尽。
newFixedThreadPool()就是用这种方式的任务队列。因为对于固定大小的线程池而言,不存在线程的动态变化(corePoolSize==maximumPoolSize)。
newSingleThreadPool()同理。

优先任务队列:
PriorityBlockingQueue实现,可以控制任务的执行先后顺序。
这优先队列是一个无界队列,根据任务的优先级顺序先后执行,优先级高的先执行。
关于ThreadFactory :
ThreadFactory是只有一个方法的接口,实现它可以创建出线程:
1 public interface ThreadFactory { 2 Thread newThread(Runnable r); 3 }
这样我们可以在自定义线程池的时候,也自定义线程的名称、组以及优先级等信息。
在ThreadPoolExecutor方法的ThreadFactory threadFactory这个参数,可以这样自定义:
new ThreadFactory(){ @Override public Thread newThread(Runnable r){ //这里自定义啦,想做啥做啥,比如创建一个新的线程,然后命名之类的? } }
关于拒绝策略:
当池子中的线程已经用完了,并且对列中也已经排满,再也装不下了,此时,就需要拒绝策略来拒绝新的任务来拿线程。
JDK内置的拒绝策略均实现了RejectedExecutionHandler接口:
public interface RejectedExecutionHandler { void rejectedExecution(Runnable r, ThreadPoolExecutor executor); }
下面我们拿出源码来分析,来看看JDK自带的4种拒绝策略是如何工作的。
AbortPolicy策略:直接抛出异常,阻止系统正常工作
1 public static class AbortPolicy implements RejectedExecutionHandler { 2 public AbortPolicy() { } 3 /** 4 * Always throws RejectedExecutionException.//总是抛出异常 5 */ 6 public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 7 throw new RejectedExecutionException("Task " + r.toString() + 8 " rejected from " + 9 e.toString()); 10 } 11 }
CallerRunsPolicy策略:只要池子没有关闭,它会拿起被丢弃的任务继续执行
1 public static class CallerRunsPolicy implements RejectedExecutionHandler { 2 public CallerRunsPolicy() { } 3 4 /** 5 * Executes task r in the caller's thread, unless the executor 6 * has been shut down, in which case the task is discarded. 7 * 就是说如果线程池没有关闭,直接在调用者的线程中,运行当前被拒绝的任务 8 */ 9 public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 10 if (!e.isShutdown()) {//如果线程池没有关闭 11 r.run();//执行当前被拒绝的任务 12 } 13 } 14 }
DiscardOledestPolicy策略:丢弃最老的请求(就是即将被执行的那个),并尝试再次提交当前任务
1 public static class DiscardOldestPolicy implements RejectedExecutionHandler { 2 public DiscardOldestPolicy() { } 3 /** 4 * Obtains and ignores the next task that the executor 5 * would otherwise execute, if one is immediately available, 6 * and then retries execution of task r, unless the executor 7 * is shut down, in which case task r is instead discarded. 8 * 9 */ 10 public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 11 if (!e.isShutdown()) {//如果线程池没有关闭 12 e.getQueue().poll();//丢弃队列中最老的那个线程 13 e.execute(r);//尝试去执行当前提交的任务 14 } 15 } 16 }
DiscardPolicy策略:啥也不做,默默丢弃无法处理的任务。
1 public static class DiscardPolicy implements RejectedExecutionHandler { 2 public DiscardPolicy() { } 3 4 /** 5 * Does nothing, which has the effect of discarding task r. 6 *啥也不做 7 */ 8 public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 9 } 10 }
拒绝策略可以说是当多线程请求执行任务的数量超过实际承载能力时最有力的工具,是系统超负荷运作时的补救措施。
当然,JDK内部的拒绝策略都是实现RejectedExecutionHandler接口的,我们也可以照着葫芦画瓢,自定义一个拒绝策略,具体怎么写,大概就是在自定义创建线程池的时候,自定义handler就可。
1 ExecutorService es=new ThreadPoolExecutor(10,10,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(20),Executors.defaultThreadFactory(), 2 new RejectedExecutionHandlers(){ 3 @Override 4 rejectedExecution(Runnable r,ThreadPoolExecutor executor){ 5 //这里自定义啦,想做啥做啥 6 }});
说完ThreadPoolExecutor的参数,接下来说说它里面的核心的方法
要说最核心的方法,那必定是执行的方法execute,其中The main pool control state, ctl, is an atomic integer packing(clt是主线程池控制状态的标志,是一个integer原子类型)
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /*源码的注释翻译: *分三步进行: * 1.如果当钱线程的线程总数少于corePoolSize,则尝试开始一个新的线程任务。调用addWorker会自动检查runState和workerCount,防止将线程错误的添加。 * 2.如果任务进入等待队列,需再次检查是否添加一个线程(因为从上次检测到现在,线程池中可能有的线程已经销毁)或者检测线程池是否关闭了。
* 检查是有必要回滚这个入队操作,还是去开始一个新的线程。 * 3.如果入队失败,则尝试添加一个新的线程。 如果以上操作失败,则拒绝任务。 */ int c = ctl.get(); if (workerCountOf(c) < corePoolSize) {//当前线程池的线程总数小于核心线程数时,通过addWorker调度,分配线程执行 if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) {//进入等待队列 int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false))//进入等待队列失败的时候(有界队列到达上限,或者使用了SynchronousQueue),addworker将任务直接提交给线程池 reject(command);//如果提交给线程池失败,则执行拒绝策略(当前线程数达到maximumPoolSize) }
当然,ThreadPoolExecutor还有好多有趣的方法,如beforeExecute()、afterExecute()、terminated()等,可以对对其进行扩展来实现对线程池运行状态的跟踪,这里就不多说了,感兴趣的自行探索。
感谢阅读。