多表关联:
准备数据
********************************************
工厂表:
| Factory | Addressed |
| BeijingRedStar | 1 |
| ShenzhenThunder | 3 |
| GongzhouHonDa | 2 |
| BeijingRising | 1 |
| GuangzhouDevelopmentBank | 2 |
| Tencent | 3 |
************************************** ****
地址表:
| Address | AddressName |
| 1 | Beijing |
| 2 | Guangzhou |
| 3 | ShenZhen |
| 4 | Xian |
******************************************
工厂-地址表:(中间的数据在结果中不显示)
| Factory | Addressed | AddressName |
| BeijingRedStar | 1 | Beijing |
| ShenzhenThunder | 3 | ShenZhen |
| GongzhouHonDa | 2 | Guangzhou |
| BeijingRising | 1 | Beijing |
| GuangzhouDevelopmentBank | 2 | Guangzhou |
| Tencent | 3 | ShenZhen |
解决思路:根据工厂表中的工厂地址ID和地址表的工厂ID相关,组合成工厂-地址表,可以达到多表关联。
步骤:
- map识别出输入的行属于哪个表之后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出。
- reduce解析map输出的结果,解析value内容,根据标志将左右表内容分开存放,然后求笛卡尔积,最后直接输出。
(1)自定义Mapper任务
1 private static class MyMapper extends Mapper<Object, Text, Text, Text> { 2 Text k2= new Text(); 3 Text v2= new Text(); 4 @Override 5 protected void map(Object k1, Text v1, 6 Mapper<Object, Text, Text, Text>.Context context) 7 throws IOException, InterruptedException { 8 String line = v1.toString();//每行文件 9 String relationType = new String(); 10 //首行数据不处理 11 if (line.contains("factoryname")==true||line.contains("addressed")==true) { 12 return; 13 } 14 //处理其他行的数据 15 StringTokenizer item = new StringTokenizer(line); 16 String mapkey = new String(); 17 String mapvalue = new String(); 18 19 int i=0; 20 while (item.hasMoreTokens()) { 21 String tokenString=item.nextToken();//读取一个单词 22 //判断输出行所属表,并进行分割 23 if (tokenString.charAt(0)>='0'&&tokenString.charAt(0)<='9') { 24 mapkey = tokenString; 25 if (i>0) { 26 relationType="1"; 27 }else { 28 relationType="2"; 29 } 30 continue; 31 } 32 mapvalue+=tokenString+" ";//存储工厂名,以空格隔开 33 i++; 34 } 35 k2 = new Text(mapkey); 36 v2 =new Text(relationType+"+"+mapvalue); 37 context.write(k2,v2);//输出左右表 38 39 } 40 }
(2)自定义Reduce任务
1 private static class MyReducer extends Reducer<Text, Text, Text, Text> { 2 Text k3 = new Text(); 3 Text v3 = new Text(); 4 5 @Override 6 protected void reduce(Text k2, Iterable<Text> v2s, 7 Reducer<Text, Text, Text, Text>.Context context) 8 throws IOException, InterruptedException { 9 if (0 == time) { 10 context.write(new Text("factoryname"), new Text("addressed")); 11 time++; 12 } 13 int factoryNum=0; 14 String [] factory=new String[10]; 15 int addressNum=0; 16 String [] address = new String[10]; 17 Iterator item=v2s.iterator(); 18 while (item.hasNext()) { 19 String record = item.next().toString(); 20 int len =record.length(); 21 int i=2; 22 if (len==0) { 23 continue; 24 } 25 //取得左右表标识 26 char relationType =record.charAt(0); 27 //左表 28 if ('1' == relationType) { 29 factory[factoryNum]=record.substring(i); 30 factoryNum++; 31 } 32 //右表 33 if ('2'==relationType) { 34 address[addressNum]=record.substring(i); 35 addressNum++; 36 } 37 } 38 // factoryNum和addressNum数组求笛卡尔积 39 if (0 != factoryNum && 0 != addressNum) { 40 for (int i = 0; i < factoryNum; i++) { 41 for (int j = 0; j < addressNum; j++) { 42 k3 = new Text(factory[i]); 43 v3 = new Text(address[j]); 44 context.write(k3, v3); 45 } 46 } 47 } 48 } 49 }
(3)主函数
1 public static void main(String[] args) throws Exception { 2 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 3 //2将自定义的MyMapper和MyReducer组装在一起 4 Configuration conf=new Configuration(); 5 String jobName=MultiTableLink.class.getSimpleName(); 6 //1首先寫job,知道需要conf和jobname在去創建即可 7 Job job = Job.getInstance(conf, jobName); 8 9 //*13最后,如果要打包运行改程序,则需要调用如下行 10 job.setJarByClass(MultiTableLink.class); 11 12 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 13 FileInputFormat.setInputPaths(job, new Path(args[0])); 14 //4指定解析<k1,v1>的类(谁来解析键值对) 15 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 16 job.setInputFormatClass(TextInputFormat.class); 17 //5指定自定义mapper类 18 job.setMapperClass(MyMapper.class); 19 //6指定map输出的key2的类型和value2的类型 <k2,v2> 20 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 21 job.setMapOutputKeyClass(Text.class); 22 job.setMapOutputValueClass(Text.class); 23 //7分区(默认1个),排序,分组,规约 采用 默认 24 25 //接下来采用reduce步骤 26 //8指定自定义的reduce类 27 job.setReducerClass(MyReducer.class); 28 //9指定输出的<k3,v3>类型 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(Text.class); 31 //10指定输出<K3,V3>的类 32 //*下面这一步可以省 33 job.setOutputFormatClass(TextOutputFormat.class); 34 //11指定输出路径 35 FileOutputFormat.setOutputPath(job, new Path(args[1])); 36 37 //12写的mapreduce程序要交给resource manager运行 38 job.waitForCompletion(true); 39 }
完整的源代码--多表链接


1 package Mapreduce; 2 3 import java.io.IOException; 4 import java.util.Iterator; 5 import java.util.StringTokenizer; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 17 18 import com.sun.jdi.Value; 19 20 public class MultiTableLink { 21 private static int time = 0; 22 23 public static void main(String[] args) throws Exception { 24 //必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定 25 //2将自定义的MyMapper和MyReducer组装在一起 26 Configuration conf=new Configuration(); 27 String jobName=MultiTableLink.class.getSimpleName(); 28 //1首先寫job,知道需要conf和jobname在去創建即可 29 Job job = Job.getInstance(conf, jobName); 30 31 //*13最后,如果要打包运行改程序,则需要调用如下行 32 job.setJarByClass(MultiTableLink.class); 33 34 //3读取HDFS內容:FileInputFormat在mapreduce.lib包下 35 FileInputFormat.setInputPaths(job, new Path(args[0])); 36 //4指定解析<k1,v1>的类(谁来解析键值对) 37 //*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class 38 job.setInputFormatClass(TextInputFormat.class); 39 //5指定自定义mapper类 40 job.setMapperClass(MyMapper.class); 41 //6指定map输出的key2的类型和value2的类型 <k2,v2> 42 //*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定 43 job.setMapOutputKeyClass(Text.class); 44 job.setMapOutputValueClass(Text.class); 45 //7分区(默认1个),排序,分组,规约 采用 默认 46 47 //接下来采用reduce步骤 48 //8指定自定义的reduce类 49 job.setReducerClass(MyReducer.class); 50 //9指定输出的<k3,v3>类型 51 job.setOutputKeyClass(Text.class); 52 job.setOutputValueClass(Text.class); 53 //10指定输出<K3,V3>的类 54 //*下面这一步可以省 55 job.setOutputFormatClass(TextOutputFormat.class); 56 //11指定输出路径 57 FileOutputFormat.setOutputPath(job, new Path(args[1])); 58 59 //12写的mapreduce程序要交给resource manager运行 60 job.waitForCompletion(true); 61 } 62 63 private static class MyMapper extends Mapper<Object, Text, Text, Text> { 64 Text k2= new Text(); 65 Text v2= new Text(); 66 @Override 67 protected void map(Object k1, Text v1, 68 Mapper<Object, Text, Text, Text>.Context context) 69 throws IOException, InterruptedException { 70 String line = v1.toString();//每行文件 71 String relationType = new String(); 72 //首行数据不处理 73 if (line.contains("factoryname")==true||line.contains("addressed")==true) { 74 return; 75 } 76 //处理其他行的数据 77 StringTokenizer item = new StringTokenizer(line); 78 String mapkey = new String(); 79 String mapvalue = new String(); 80 81 int i=0; 82 while (item.hasMoreTokens()) { 83 String tokenString=item.nextToken();//读取一个单词 84 //判断输出行所属表,并进行分割 85 if (tokenString.charAt(0)>='0'&&tokenString.charAt(0)<='9') { 86 mapkey = tokenString; 87 if (i>0) { 88 relationType="1"; 89 }else { 90 relationType="2"; 91 } 92 continue; 93 } 94 mapvalue+=tokenString+" ";//存储工厂名,以空格隔开 95 i++; 96 } 97 k2 = new Text(mapkey); 98 v2 =new Text(relationType+"+"+mapvalue); 99 context.write(k2,v2);//输出左右表 100 101 } 102 } 103 private static class MyReducer extends Reducer<Text, Text, Text, Text> { 104 Text k3 = new Text(); 105 Text v3 = new Text(); 106 107 @Override 108 protected void reduce(Text k2, Iterable<Text> v2s, 109 Reducer<Text, Text, Text, Text>.Context context) 110 throws IOException, InterruptedException { 111 if (0 == time) { 112 context.write(new Text("factoryname"), new Text("addressed")); 113 time++; 114 } 115 int factoryNum=0; 116 String [] factory=new String[10]; 117 int addressNum=0; 118 String [] address = new String[10]; 119 Iterator item=v2s.iterator(); 120 while (item.hasNext()) { 121 String record = item.next().toString(); 122 int len =record.length(); 123 int i=2; 124 if (len==0) { 125 continue; 126 } 127 //取得左右表标识 128 char relationType =record.charAt(0); 129 //左表 130 if ('1' == relationType) { 131 factory[factoryNum]=record.substring(i); 132 factoryNum++; 133 } 134 //右表 135 if ('2'==relationType) { 136 address[addressNum]=record.substring(i); 137 addressNum++; 138 } 139 } 140 // factoryNum和addressNum数组求笛卡尔积 141 if (0 != factoryNum && 0 != addressNum) { 142 for (int i = 0; i < factoryNum; i++) { 143 for (int j = 0; j < addressNum; j++) { 144 k3 = new Text(factory[i]); 145 v3 = new Text(address[j]); 146 context.write(k3, v3); 147 } 148 } 149 } 150 } 151 } 152 }
程序运行结果
(1) 数据准备:新建文件夹,并在文件夹内新建factory文件和address文件
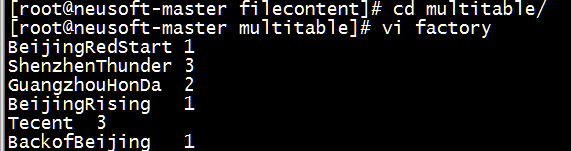
[root@neusoft-master multitable]# vi factory
BeijingRedStart 1
ShenzhenThunder 3
GuangzhouHonDa 2
BeijingRising 1
Tecent 3
BackofBeijing 1
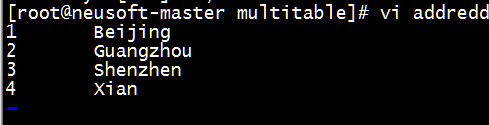
[root@neusoft-master multitable]# vi addredd
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
(2)将文件夹上传到HDFS中
[root@neusoft-master filecontent]# hadoop dfs -put multitable/ /neusoft/
(3)打成jar包并指定主类,提交至Linux中
[root@neusoft-master filecontent]# hadoop jar MultiTableLink.jar /neusoft/multitable /out14

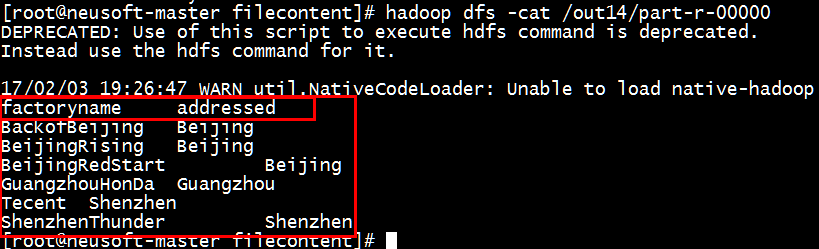
(4)查看结果
[root@neusoft-master filecontent]# hadoop dfs -cat /out14/part-r-00000
End~