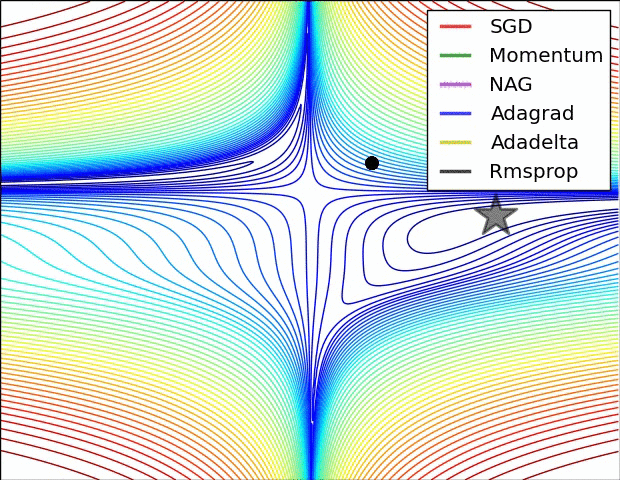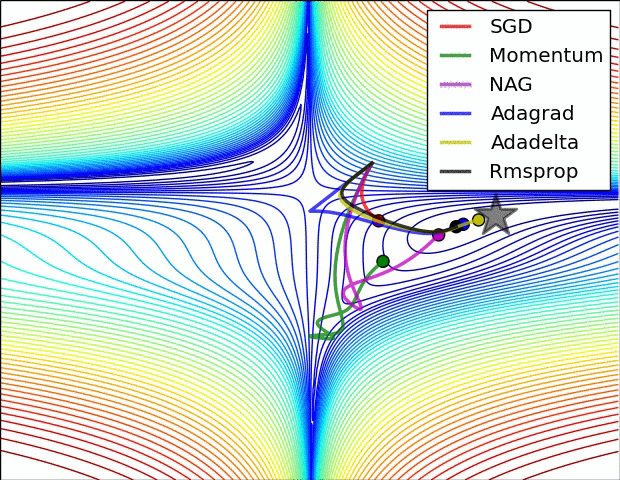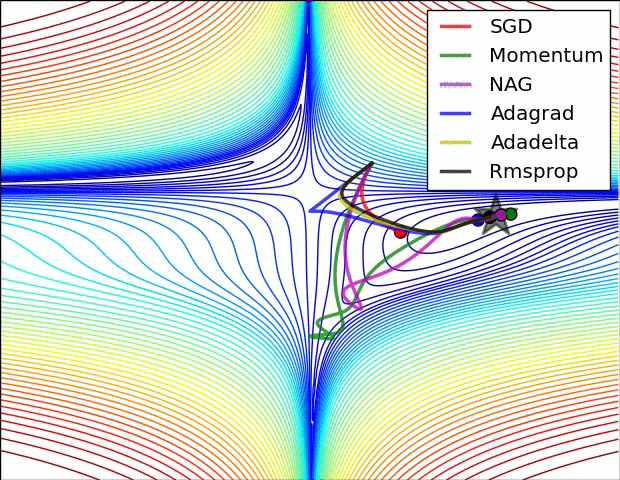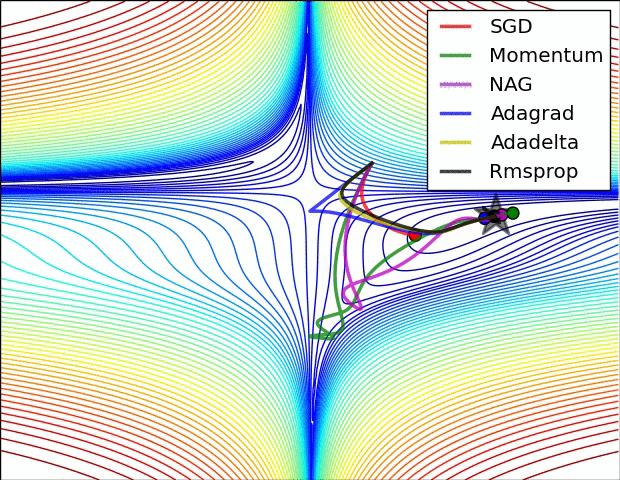
以下算法均为通过不同的方法调整学习率learningrate的过程
GradientDescent是使用全部数据做梯度下降
在该方法中,每次更新我们都需要在整个数据集上求出所有的偏导数。因此批量梯度下降法的速度会比较慢,甚至对于较大的、内存无法容纳的数据集,该方法都无法被使用。同时,梯度下降法不能以「在线」的形式更新我们的模型,也就是不能再运行中加入新的样本进行运算。

SGD是随机采样一每次对一个样本做梯度下降
相比批量梯度下降法,随机梯度下降法的每次更新,是对数据集中的一个样本(x,y)求出罚函数,然后对其求相应的偏导数:
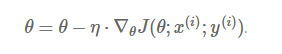
因为批量梯度下降法在每次更新前,会对相似的样本求算梯度值,因而它在较大的数据集上的计算会有些冗余(redundant)。而随机梯度下降法通过每次更新仅对一个样本求梯度,去除了这种冗余的情况。因而,它的运行速度被大大加快,同时也能够「在线」学习。
小批量梯度下降法(Mini-Batch Gradient Descent)
小批量梯度下降法集合了上述两种方法的优势,在每次更新中,对 n 个样本构成的一批数据,计算罚函数 J(θ),并对相应的参数求导:
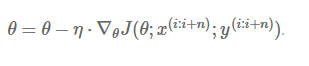
这种方法,(a) 降低了更新参数的方差(variance),使得收敛过程更为稳定;(b) 能够利用最新的深度学习程序库中高度优化的矩阵运算器,能够高效地求出每小批数据的梯度。通常一小批数据含有的样本数量在 50 至 256 之间,但对于不同的用途也会有所变化。小批量梯度下降法,通常是我们训练神经网络的首选算法。同时,有时候我们也会使用随机梯度下降法,来称呼小批量梯度下降法(译者注:在下文中,我们就用 SGD 代替随机梯度下降法)。
下降速度
更新神经网络参数的方法1:原始的权值更新-弯弯曲曲的到达终点
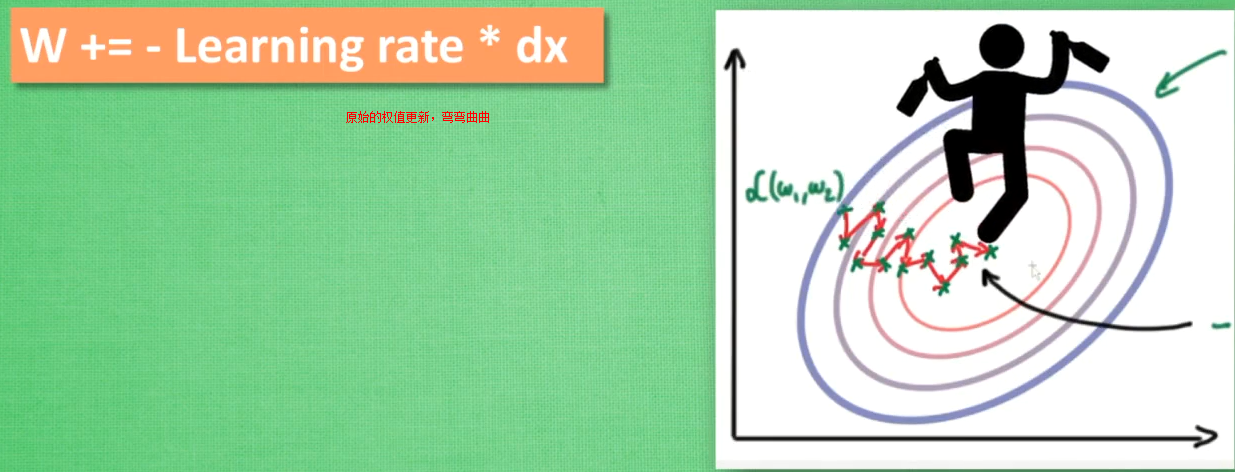
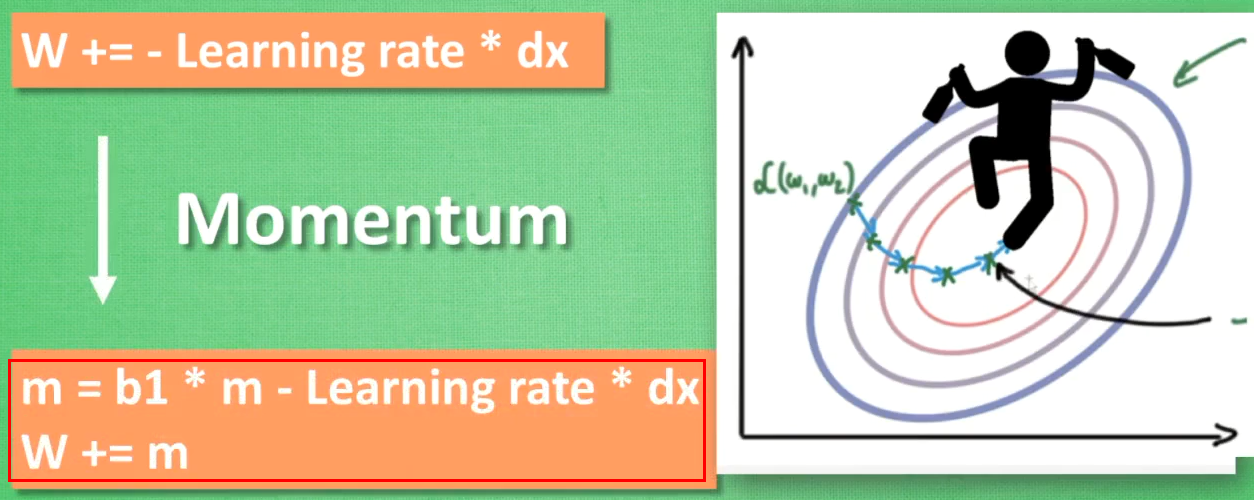
更新神经网络参数的方法2:往下坡方向走向终点----惯性原则
AdaGrad-错误方向的阻力

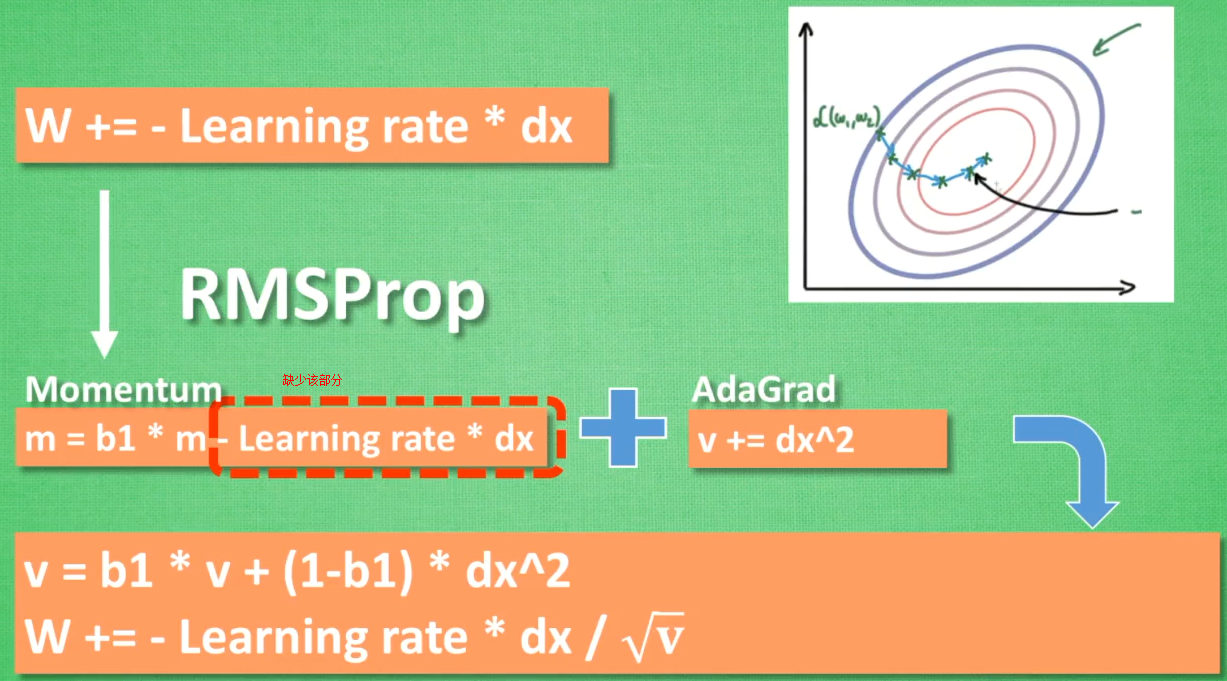
RMSProp=Momentum(惯性原则)+AdaGrad(错误方向的阻力)--Momentum中有一部分未包含,衍生了Adam方法
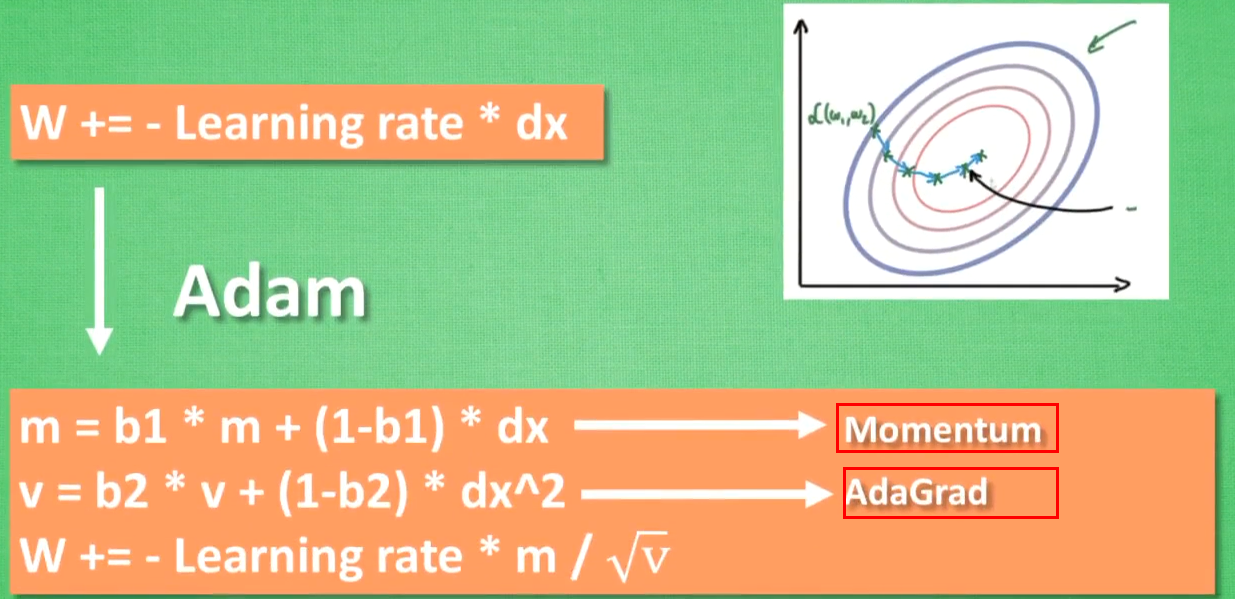
Adam
计算m有Momentum属性(惯性属性)+计算v时有Adagrad属性(阻力属性),更新参数时将m和v都考虑进去
在大多数情况下使用Adam都能又快又好的达到目标
经验之谈
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
-
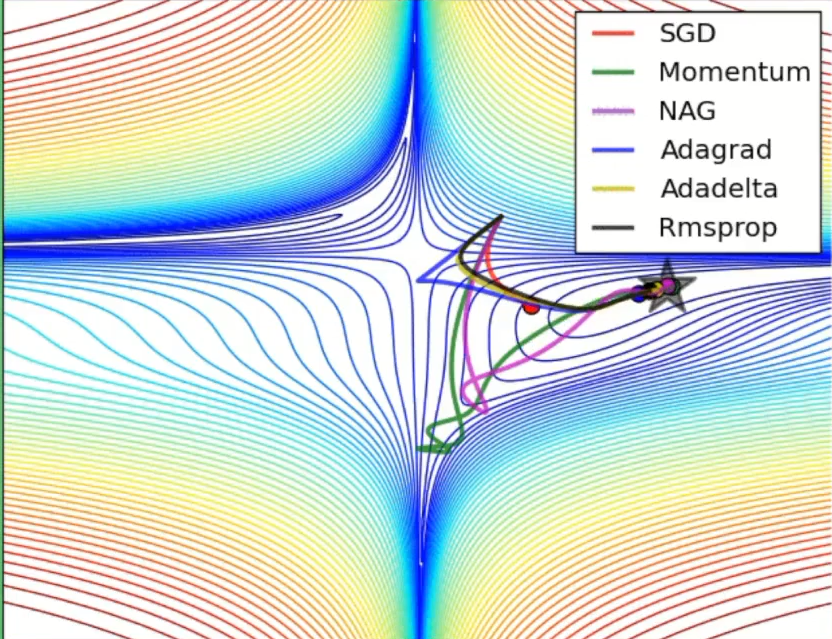
动态图
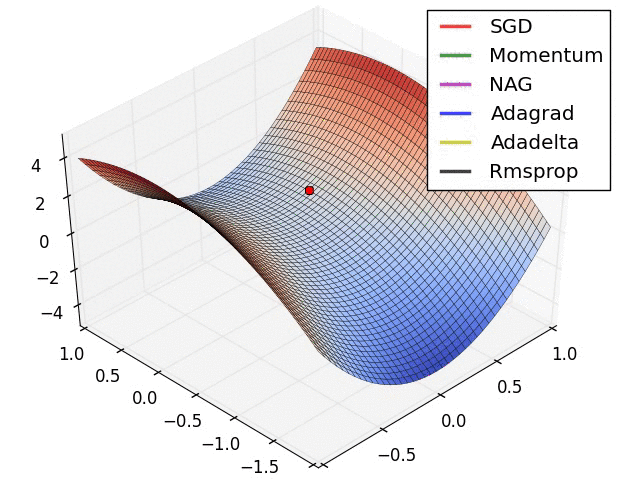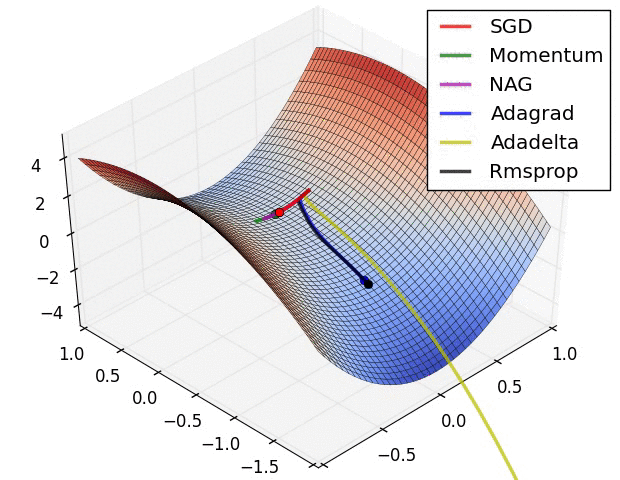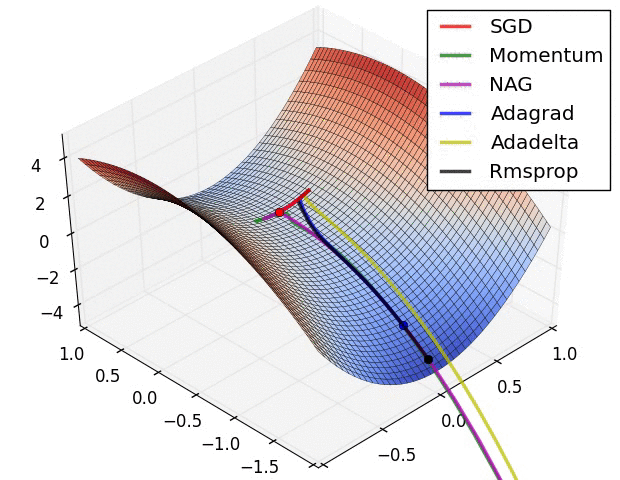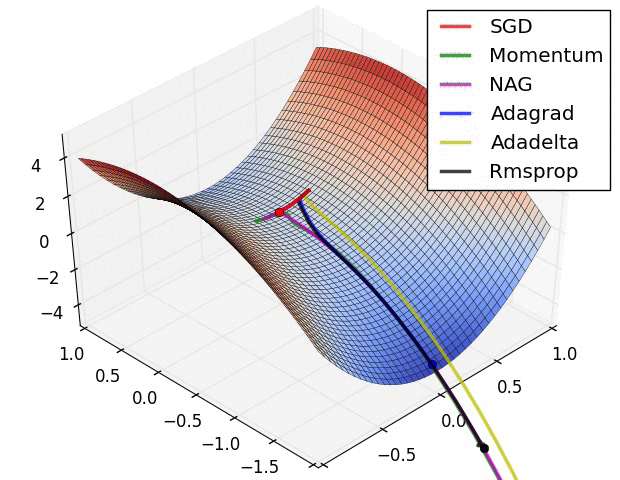
- 走到全局最优解的过程---红色的边界表示cost比较大的地方,蓝色的地方是cost比较小的
- 从起点如下图依次走向全局最优值的过程,每个方法都有不同的学习路径
- SGD:比其他的都慢一些
- Momwntum:跨越一个很长的步数,考虑的是上一个的learning_rate,下一个learning_rate会基于上一个跨越更长的步数,所以开始的时候走的方向上是错误的,但是会慢慢纠正,纠正的速度也很快