一、IO多路复用
传统的BIO服务器处理客户端IO请求时会为每一个客户端请求都分配一个线程去处理,当客户端数量增加时会导致服务端线程数过多而带来性能隐患,所以迫不得已需要一个线程处理多个客户端请求,也就衍生了多路复用IO模型,Java中的NIO核心就是使用到了操作系统的多路复用IO。
IO多路复用的本质是内核缓冲IO数据,应用程序开启线程监控多个文件描述符,一个IO链接对于一个文件描述符,一旦某个文件描述符就绪,会通知应用程序执行对应的读操作或者写操作。
操作系统提供了三种多路复用API给应用程序使用,分别是select、poll和epoll
1.1、select机制
select函数有一个参数为fd_set,表示监控的描述符集合,数据结构为long类型数组,每一个数组元素都与一个打开的文件句柄相关联,文件句柄可以是socket描述符、文件描述符等;当调用select函数之后,内核根据IO的状态更新fd_set的值,由此来通知调用select函数的应用程序那个IO就绪了。从流程上看select和同步阻塞IO差不多,而且select还额外多了select操作,但是select的优势是可以同时监控多个IO操作,而同步阻塞IO想要做到同时监控多个IO操作必须采用多线程的方式。很明显从线程消耗上来说,selec更合适一个线程同时和多个IO操作交互的场景。
select的问题:
1、每次调用select,都需要将fd_set从用户空间复制到内核空间,当fd_set比较大时,复制消耗较大
2、每次调用select,内核都需要遍历一次fd_set,当fd_set比较大时,遍历消耗较大
3、内核对于fd_set作了大小限制,最大值为1024或2048
4、当描述符数量较多,而活跃的较少时性能浪费较大,甚至还不如同步阻塞IO模型
1.2、poll机制
poll机制的实现逻辑和select基本上一致,只是没有对描述符的数量做限制,存储描述符的数据结构为链表结构poll相当于是select的改良吧,但是也只是在同时监控的描述符数量上改良了,其他实现逻辑并没有变,所以还是会有select遇到的问题select和poll都只适合文件描述符数量和活跃数都多时,如果文件描述符数量较多而活跃的较少时并不适合。
1.3、epoll机制
select和poll机制最大的问题是每次调用函数都需要将文件描述符集合从用户空间复制到内核空间,另外每次都需要线性遍历所有的文件描述符判断状态。而epoll的实现方式是通过注册事件回调通知的方式实现,另外通过一个文件描述符来管控多个文件描述符,同样也没有文件描述符数量的上限。epoll的实现流程为通过调用内核的epoll_ctl函数注册需要监听的文件描述符以及对应的事件,内核一旦发现该文件描述符状态就绪,就会将所有的已经就绪的文件描述符保存到ready集合中,应用程序通过函数epoll_wait函数不停从ready集合中获取已经就绪的文件描述符即可,所以epoll不需要对所有的文件描述符进行遍历,而只需要对已经就绪的文件描述符进行遍历即可。
当然如果文件描述符全部是活跃状态的,那么epoll机制的性能可能还没有select和poll的高,但是大多数情况下都是文件描述符数量较多,而活跃数较少的场景。
另外select、poll和epoll处理IO事件时都默认是水平触发,也就是每次查下文件描述符状态都是获取到所有就绪的文件描述符,如果对于就绪的文件描述符不进行处理,那么每次调用时都会返回该文件描述符;
而epoll除了支持水平触发之外,还支持边缘触发模式,边缘触发模式是每次只会返回上一次调用之后到目前为止的就绪文件描述符,也就是说一个文件描述符就绪事件只会通过epoll_wait方法返回一次,所以需要应用程序立即处理,如果不处理那么就需要等到下一次文件描述符就绪。边缘触发模式相比于水平触发模式来说大量减少了就绪事件触发的次数,所以效率更高,但是需要应用程序缓存事件就绪状态并且立即处理,否则可能会丢失数据。
总结select、poll、epoll的对比
| select | poll | epoll | |
| 获取FD状态的方式 | 线性遍历所有FD | 线性遍历所有的FD | 注册FD就绪的事件,回调通知 |
| FD数量限制 | 1024或2048 | 无上限 | 无上限 |
| FD存储数据结构 | 数组 | 链表 | 红黑树 |
| IO效率 | 线性遍历,时间复杂度o(n) | 线性遍历,时间复杂度o(n) | 遍历已经就绪的事件集合,时间复杂度o(1) |
| FD复制到内核 | 每次调用都需要复制一次 | 每次调用都需要复制一次 | epoll_ctl注册时复制一次,epoll_wait不需要复制 |
| IO触发模式 | 仅支持水平触发 | 仅支持水平触发 | 支持水平触发和边缘触发 |
二、NIO理论浅析
BIO:同步阻塞IO,服务器会为每个IO连接分配一个线程处理IO操作,如果没有IO操作,那么线程就一直处于阻塞状态,直到能够读写IO数据操作。
BIO的弊端:
1、客户端连接数和服务器线程数1:1,随着客户端数量增加,服务器会有较大的创建销毁线程的性能消耗
2、IO操作的线程使用率较低,因为大部分场景下客户端连接之后并不是一直处于IO操作状态,所以大部分情况下会导致线程处于空闲状态
NIO:同步非阻塞IO,对于客户端的连接服务器并不会立即分配线程处理IO操作,而是先进行注册,注册每个客户端连接以及客户端需要监听的事件类型,一旦事件就绪(如可读事件、可写事件)那么才会通过服务器分配线程处理具体的IO操作
NIO相对于BIO的优点:
1、只需要一个注册线程就可以管理所有的客户端注册链接操作
2、只有客户端存在有效的IO操作时服务器才会分配线程去处理,大幅度提高线程的使用率
3、服务器采用采用轮询的方式监听客户端链接的事件就绪状态,而具体的IO操作线程不会被阻塞
2.1、NIO的三大核心
提到NIO就不得不先了解NIO相比于BIO的三大核心模块,分别是多路复用选择器(Selector)、缓冲区(Buffer)和通道(Channel)
2.1.1、Channel(通道)
Channel可以理解为是通信管道,客户端和服务端之前通过channel互相发送数据。通常情况下流的读写是单向的,从发送端到接收端。而通道支持双向同时通信,客户端和服务端可以同时在通道中发送和接收数据
另外通道中的数据不可以直接读写,而是必须和缓冲区进行交互,通道中的数据会写到缓冲区,另外发送的数据也必须先到缓冲区才能通过通道发送。
2.1.2、Buffer(缓冲区)
缓冲区本质上是一块可以读写数据的内存,通道中的数据读数据必须从缓冲区读,写数据也必须要写到缓冲区。而想要读写缓冲区的数据必须调用缓冲区提供的API进行读写数据。
缓冲区的好处是读写两端不需要关心彼此的状态,而只需要和缓冲区交互即可。类似于MQ的消息队列,发送方只需要把消息发送到队列中即可,而消费者不需要关心发送方的状态,只需要不停从队列中读取数据即可。
而针对IO操作也是一样,客户端把数据发送给服务端的缓冲区之后就结束了发送数据的任务,而具体数据何时使用完全看服务端何时从缓冲区去读数据。
2.1.3、Selector(多路复用选择器)
Selector主要负责和channel交互,多个channel将自己感兴趣的IO事件和自己绑定在一起注册到Selector上,Selector可以同时监控多个Channel的状态,如果发生了channel感兴趣的事件,那么就通知channel进行数据的读写操作。
如果没有Selector,就需要每个channel链接成功就需要分配一个线程去负责channel数据的读写,而使用了Selector之后,只需要一个线程监控多个channel的状态,只有有了真正的IO操作之后才会分配线程去处理真正的IO操作。
Selector的底层是通过操作系统的select、poll和epoll机制来实现的。
2.2、NIO的使用案例
NIO服务端案例代码如下:
1 public class NioServer { 2 3 /** 服务端通道 */ 4 private static ServerSocketChannel serverSocketChannel; 5 6 /** 多路复用选择器*/ 7 private static Selector selector; 8 9 public static void main(String[] args) { 10 try { 11 //1.初始化服务器 12 initServer(); 13 //2.启动服务器 14 startServer(); 15 }catch (Exception e){ 16 e.printStackTrace(); 17 } 18 } 19 20 private static void initServer() throws IOException { 21 /** 1.创建服务端通道 */ 22 serverSocketChannel = ServerSocketChannel.open(); 23 24 //设置通道为非阻塞类型 25 serverSocketChannel.configureBlocking(false); 26 27 /** 2. 绑定监听端口号 */ 28 serverSocketChannel.socket().bind(new InetSocketAddress(8000)); 29 30 /** 3. 创建多路复用选择器 */ 31 selector = Selector.open(); 32 33 /** 4. 注册通道监听的事件 */ 34 serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT); 35 } 36 37 /** 启动服务器 */ 38 private static void startServer() throws IOException { 39 System.out.println("Start Server..."); 40 while (true){ 41 /** 1.不停轮训获取所有的channel的状态 */ 42 selector.select(); //阻塞当前线程,直到至少有一个通道触发了对应的事件 43 /** 2.获取所有触发了注册事件的channel及事件集合 */ 44 Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); 45 /** 3.遍历处理所有channel的事件 */ 46 while(iterator.hasNext()){ 47 SelectionKey key = iterator.next(); 48 /** 4.根据不同的事件类型处理不同的业务逻辑 */ 49 if(key.isAcceptable()){ 50 //表示当前通道接收连接成功,主要用于服务端接收到客户端连接成功 51 SocketChannel channel = serverSocketChannel.accept(); 52 channel.configureBlocking(false); 53 channel.register(selector, SelectionKey.OP_READ); 54 }else if(key.isConnectable()){ 55 //表示当前通道连接成功,主要用于客户端请求服务器连接成功 56 }else if(key.isReadable()){ 57 //表示当前通道有可读的数据 58 receiveMsg(key); 59 }else if(key.isWritable()){ 60 //表示当前通道可以写入数据,(网络不阻塞的情况下,基本上一直处于可写状态,除非缓冲区满了) 61 } 62 iterator.remove(); 63 } 64 } 65 } 66 67 /** 读取数据,当事件为可读事件时调用 */ 68 private static void receiveMsg(SelectionKey key) throws IOException { 69 SocketChannel channel = (SocketChannel) key.channel(); 70 /** 1.分配2048大小的缓存区大小 */ 71 ByteBuffer buffer = ByteBuffer.allocate(2048); 72 /** 2.将channel中数据读到缓冲区,并返回数据大小 */ 73 int i = channel.read(buffer); 74 if(i != -1){ 75 /** 3.从缓冲区获取所有数据,解析成字符串*/ 76 String msg = new String(buffer.array()).trim(); 77 System.out.println("服务器接收到消息:" + msg); 78 /** 4.调用write方法向channel中发送数据 */ 79 channel.write(ByteBuffer.wrap(("reply : " + msg).getBytes())); 80 }else { 81 channel.close(); 82 } 83 } 84 }
NIO客户端案例代码如下:
1 public class NioClient { 2 3 private SocketChannel channel; 4 5 public static void main(String[] args) throws Exception { 6 NioClient client = new NioClient(); 7 client.initClient(); 8 client.sendMsg("Hello NIO Server"); 9 client.receiveMsg(); 10 } 11 12 /** 初始化客户端*/ 13 private void initClient() throws Exception{ 14 /** 1.创建客户端通道,并绑定服务器IP和端口号 */ 15 channel = SocketChannel.open(new InetSocketAddress("localhost", 8000)); 16 } 17 18 /** 发送数据到服务端*/ 19 private void sendMsg(String msg) throws IOException { 20 byte[] bytes = msg.getBytes(); 21 ByteBuffer buffer = ByteBuffer.wrap(bytes); 22 /** 向通道发送数据 */ 23 channel.write(buffer); 24 buffer.clear(); 25 } 26 27 /** 从服务器接收数据*/ 28 private void receiveMsg() throws IOException { 29 ByteBuffer buffer = ByteBuffer.allocate(2048); 30 channel.read(buffer); 31 System.out.println(new String(buffer.array())); 32 channel.close(); 33 } 34 }
2.3、NIO的工作流程
服务端:
1、创建ServerSocketChannel通道对象,是所有客户端通道的父通道,专门用于负责处理客户端的连接请求
2、绑定服务器监听端口,设置是否阻塞模式
3、创建多路复用选择器Selector对象,可以创建一个或者多个
4、将ServerSocketChannel以及监听的客户端连接事件(ACCEPT事件)一起注册到Selector上(只需要监听ACCEPT事件即可,专门用于处理客户端的连接请求,至于和客户端读写数据的交互再另外创建通道实现)
5、死循环不停的轮训Selector上注册的所有的通道是否触发了注册的事件
5.1、通过调用Selector的select()方法,该方法会阻塞当前线程,直到至少有一个注册的通道触发了对应的事件才会取消阻塞,然后通过SelectedKeys方法获取所有触发了事件的通道
5.2、遍历所有的SelectionKey,根据触发的事件的类型,进行不同的处理
6、当监听到客户端连接事件之后,为客户端创建SocketChannel用于TCP数据通信,并且将该通道和可读事件(ON_READ)注册到Selector上
7、当监听到客户端可读事件之后,表示客户端向服务器发送数据,那么为该通道创建一定大小的缓冲区,将通道中的数据写入到缓冲区
8、业务处理逻辑从缓冲区读取客户端发送来的数据,进行解析和业务处理
9、服务器通过调用channel的write方法回写数据存入buffer中,(不需要关闭channel,channel是客户端断开了连接之后,服务端会接收到ON_READ事件,然后报错就知道channel断开了)
客户端:
1、创建SocketChannel通道对象,并绑定服务器IP和端口信息进行连接请求
2、直接通过缓冲区向服务器发送数据
3、直接尝试从通道中读取数据发到缓冲区
三、NIO源码解析
3.1、服务器的初始化
服务器的初始化包括创建ServerSocketChannel通道的初始化和多路复用选择器Selector的初始化
3.1.1、ServerSocketChannel初始化
ServerSocketChannel是通道接口Channel的实现类,主要用于服务器客户端连接的通信,通过静态方法open()方法创建,源码如下:
1 /** 创建 ServerSocketChannel对象 */ 2 public static ServerSocketChannel open() throws IOException { 3 /** 通过SelectorProvider的openServerSocketChannel方法创建*/ 4 return SelectorProvider.provider().openServerSocketChannel(); 5 }
这里是通过SelectorProvider的provider方法先获取SelectorProvider对象,然后再调用SelectorProvidor的openServerSocketChannel方法创建,该方法代码如下:
1 public ServerSocketChannel openServerSocketChannel() throws IOException { 2 /** 直接创建ServerSocketChannel接口的实现类 ServerSocketChanelImpl对象 */ 3 return new ServerSocketChannelImpl(this); 4 }
可以看出最终创建的ServerSocketChannel对象实际就是创建了一个ServerSocketChannelImpl对象
3.1.2、Selector初始化
Selector的初始化也是调用了Selector类的静态方法open方法创建的,代码如下
1 public static Selector open() throws IOException { 2 /** 调用具体的SelectorProvider的openSelector方法 */ 3 return SelectorProvider.provider().openSelector(); 4 }
可以发现和ServerSocketChannel的open逻辑基本上一直,都是先获取SelectorProvider对象,然后调用对应的openSelector方法来创建,只不过openSelector的实现这里有多个子类都实现了该方法,因为Selector是完全依赖于底层操作系统的支持的,所以openSelector方法会根据当前操作系统的不同返回不同的Selector对象,Windows系统就会返回WindowsSelectorImpl对象,而Linux系统就可以根据具体使用哪一种多路复用机制来选用哪种Selector实现类,可以使用SelectorImpl、PollSelectorImpl、KQueueSelectorImpl(mac系统)等。不同电脑查看openSelector方法的实现可能会不一样,因为不同操作系统的JDK包不一样,所以源码也不同,主要看当前操作系统支持哪一种Selector,所以openSelector的功能就是根据当前操作系统创建一个Selector对象
3.2、Selector的工作原理
Selector的工作流程主要步骤如下:
1、调用Selector的select()方法阻塞当前线程,直到有channel触发了注册的事件
2、调用Selector的selectedKeys()方法获取所有通道和事件,事件和通道一起封装成了SelectionKey对象
3、遍历所有的SelectionKey集合,分别判断事件的类型,执行对应的处理
SelectionKey类
SelectionKey类可以看作是channel和事件的封装类,当一个channel触发了对应的事件之后,就会将事件类型和Channel一起封装成一个SelectionKey对象,而事件类型主要有以下四种:
int OP_READ = 1<<0 = 1 : 可读事件,表示当前通道中有数据可以读取(服务端和客户端公用)
int OP_WRITE = 1<<2 = 4 :可写事件,表示当前可以向通道中写入数据(服务端和客户端公用)
int OP_CONNECT= 1<<3 = 8 :连接事件,表示客户端向服务端连接成功(用户客户端)
int OP_ACCEPT = 1<<4 = 16 :接收连接事件,表示服务端接收到客户端连接成功(用于服务端)
SelectionKey针对不同事件提高了不同的方法,判断是否触发了对应的事件,方法如下:
1 /** 是否触发可读事件 */ 2 public final boolean isReadable() { 3 /** 获取当前状态 和 可读事件值进行与运算 */ 4 return (readyOps() & OP_READ) != 0; 5 } 6 7 /** 是否触发可写事件 */ 8 public final boolean isWritable() { 9 /** 获取当前状态 和 可写事件进行与运算 */ 10 return (readyOps() & OP_WRITE) != 0; 11 } 12 13 /** 是否触发连接成功事件 */ 14 public final boolean isConnectable() { 15 /** 获取当前状态 和 连接成功事件进行与运算*/ 16 return (readyOps() & OP_CONNECT) != 0; 17 } 18 19 /** 是否接收连接成功事件 */ 20 public final boolean isAcceptable() { 21 /** 获取当前状态 和 接收连接成功事件进行与运算*/ 22 return (readyOps() & OP_ACCEPT) != 0; 23 } 24 25 /** 获取当前通道就绪的状态值,由子类实现 */ 26 public abstract int readyOps();
3.3、Selector的regist方法源码解析
Selector的regist方法用来注册Channel和感兴趣的事件,将channel和事件封装成SelectionKey对象保存在Selector中,源码如下:
1 /** 2 * 注册通道和事件 3 * @param var1 : 通道 4 * @param var2 : 事件 5 * */ 6 protected final SelectionKey register(AbstractSelectableChannel var1, int var2, Object var3) { 7 if (!(var1 instanceof SelChImpl)) { 8 throw new IllegalSelectorException(); 9 } else { 10 /** 构建SelectionKeyImpl对象 */ 11 SelectionKeyImpl var4 = new SelectionKeyImpl((SelChImpl)var1, this); 12 var4.attach(var3); 13 synchronized(this.publicKeys) { 14 /** 注册SelectionKey */ 15 this.implRegister(var4); 16 } 17 /** 设置SelectionKey对象感兴趣的事件 */ 18 var4.interestOps(var2); 19 return var4; 20 } 21 }
3.4、Selector的select方法源码解析
1 public int select() throws IOException { 2 //调用内部重载方法select方法 3 return this.select(0L); 4 } 5 6 public int select(long var1) throws IOException { 7 if (var1 < 0L) { 8 throw new IllegalArgumentException("Negative timeout"); 9 } else { 10 //调用内部的lockAndDoSelect方法 11 return this.lockAndDoSelect(var1 == 0L ? -1L : var1); 12 } 13 } 14 15 private Set<SelectionKey> publicKeys; 16 private Set<SelectionKey> publicSelectedKeys; 17 18 private int lockAndDoSelect(long var1) throws IOException { 19 /** 将当前Selector对象锁住*/ 20 synchronized(this) { 21 //1.判断当前Selector是否是开启状态 22 if (!this.isOpen()) { 23 throw new ClosedSelectorException(); 24 } else { 25 int var10000; 26 /** 27 * 锁住publicKeys对象 28 * */ 29 synchronized(this.publicKeys) { 30 /** 31 * 所以publicSelectedKeys对象 32 * */ 33 synchronized(this.publicSelectedKeys) { 34 /** 调用内部 doSelect方法 35 * doSelect方法的具体是否由子类实现,根据不同的Selector类型调用本地方法, 36 * 而本地方法的实现就是调用操作系统的多路复用技术select、poll或epoll机制返回结果 37 * */ 38 var10000 = this.doSelect(var1); 39 } 40 } 41 return var10000; 42 } 43 } 44 } 45 46 /** SelectionKey数组 */ 47 protected SelectionKeyImpl[] channelArray; 48 49 /** 以PollSelectorImpl实现类为例*/ 50 protected int doSelect(long var1) throws IOException { 51 if (this.channelArray == null) { 52 throw new ClosedSelectorException(); 53 } else { 54 //清理已经无效的SelectionKey 55 this.processDeregisterQueue(); 56 57 try { 58 /** 调用begin方法使得线程进入阻塞状态,直到有SelectionKey触发了事件*/ 59 this.begin(); 60 /** 调用本地方法poll方法,本质是调用操作系统的poll方法*/ 61 this.pollWrapper.poll(this.totalChannels, 0, var1); 62 } finally { 63 this.end(); 64 } 65 66 this.processDeregisterQueue(); 67 /** 统计触发了事件的SelectionKey个数,并添加到Set<SelectionKey>集合中*/ 68 int var3 = this.updateSelectedKeys(); 69 if (this.pollWrapper.getReventOps(0) != 0) { 70 this.pollWrapper.putReventOps(0, 0); 71 synchronized(this.interruptLock) { 72 IOUtil.drain(this.fd0); 73 this.interruptTriggered = false; 74 } 75 } 76 77 return var3; 78 } 79 }
有三个大小为1025大小的数组,1位存放发生事件的socket的总数,后面存放发生事件的socket句柄个数,分别是readFds、writeFds和exceptFds,分别对应读事件、写事件、异常事件,然后调用本地的poll方法,如果有事件发生统计数量封装成SelectKey返回,如果没有数据就一直阻塞知道有数据返回或者是达到超时时间返回。
Tips:
1、遍历SelectionKey集合之后,需要将SelectionKey从集合中删除,否则下一次调用select方法时还会返回
2、调用select()方法之后主线程会一直被阻塞,直到有channel触发了事件,通过调用wakeup方法唤醒主线程
3.3、Buffer的源码解析
Buffer是NIO中IO数据存储的缓冲区,数据从channel中写入到Buffer中或者数据由channel从Buffer中读取数据。而缓冲区的本质就是一个数组,如果是ByteBuffer那么就是byte数组,如果是CharBuffer,那么就是char数组。
3.3.1、Buffer的核心属性
而Buffer的使用又离不开数组位置的标记,用来标记Buffer数组的核心变量分别如下:
capacity:数组容量,数组的总大小,初始化Buffer时设置,固定不变
position:当前的位置,初始化值为0,每向数组中写1位数据,position的值就向后移动一位,所以position的取值范围为 0 ~ capacity-1;当Buffer从写模式切换到读模式之后,position值置位0,每读1位数据,position向后移动一位。
limit:表示当前可读或可写数据的上限,写模式下默认为capacity;读模式下值为position的值
mark:标记位置,调用mark方法之后将mark值设置为position值用来标记,当调用reset方法之后position值再恢复到mark值,默认为-1
四个属性之间的大小关系为 : 0 <= mark <= position <= limit <= capacity
3.3.2、Buffer的核心方法
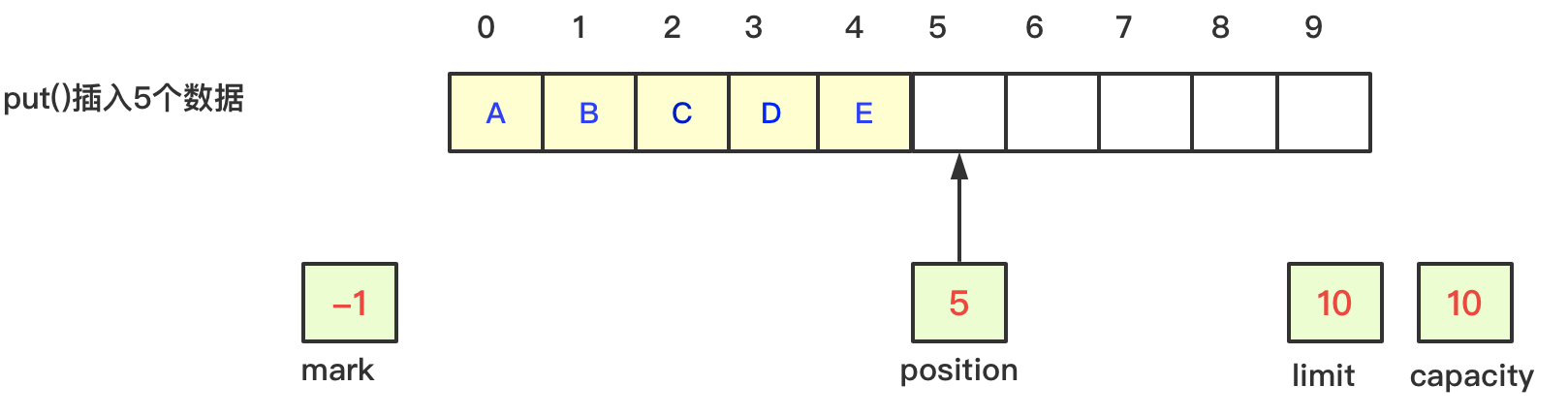
put方法:向数组中插入数据,position值随着插入数据而变化,假设插入5个数据,那么position值为5,其他变量值不变
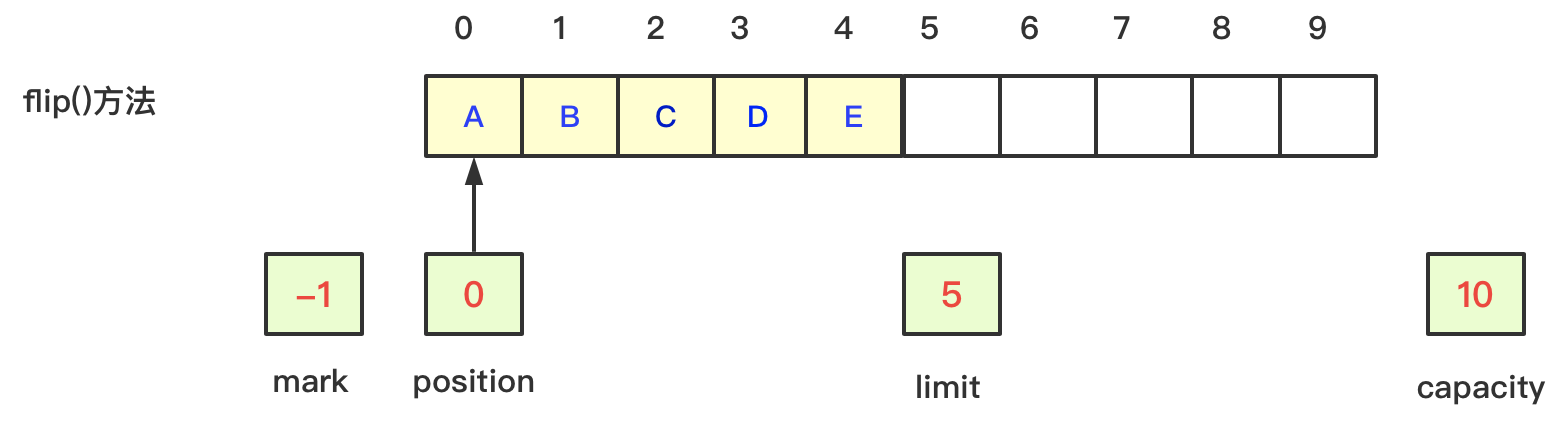
flip方法:将缓冲区数据由写模式切换成读模式,此时limit值设置为position,position重新置为0,其他变量值不变
rewind方法:当读取数据读到一半时发现数据有问题,需要从头开始读起,此时可以调用rewind方法,该方法和flip方法类似,但是不影响limit属性,而只是将position置为0,mark设置为-1,相当于读模式下从头开始读数据;写模式下从头开始写数据
compact方法:当读取数据读到一半时,又需要重新切换到写模式时,此时已读部分数据的空间就无法再写入数据,那么就会造成空间的浪费,此时可以调用compact方法将剩余的空间进行压缩,实现逻辑就是将当前剩余未读的数据复制到数组的0的位置,而position设置为下一个可以写的位置,limit重新设置为最大值capacity。
mark方法:用来标记当前的position位置,将mark设置为position值
reset方法:将position重新设置上一次标记的值,也就是position=mark值
clear方法:清空缓冲区,设置position=0,mark=-1,limit=capacity,这里的clear只是设置各个位置属性的值,而数组内的数据并不会真的被清空
以ByteBuffer为例分配内存是可以分配堆内内存和堆外内存
ByteBuffer.allocation(int catacity):分配堆内内存
ByteBuffer.allocationDirect(int catacity):分配堆外内存(直接内存)
3.3.3、图解Buffer的核心方法逻辑
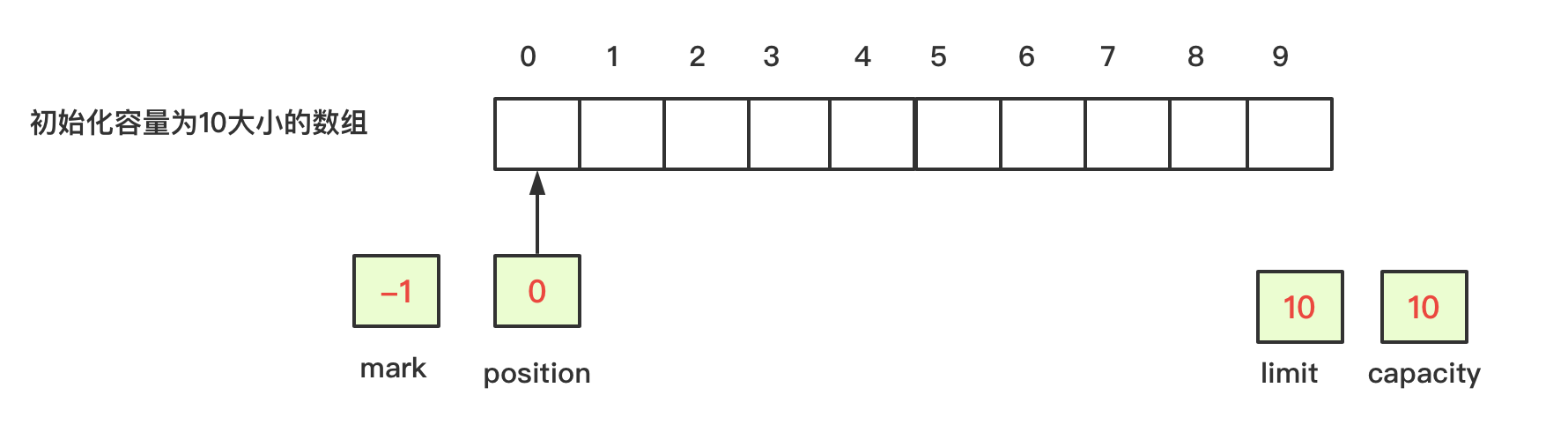
1、初始化容量为10的数组,如下图:
初始化时容量为10,此时mark为默认值-1,position为默认值0,limit和capacity都是容量的值为10
2、调用put方法向数组中写入5个数据,此时position值为5,limit、capacity和mark值不变,如下图:
3、此时不需要再写数据,而是需要从缓冲区读数据时,调用flip方法将写模式切换成读模式,此时position值为0,limit值为当前position值为5,capacity和mark值不变,如下图:
4、当读取数据读到第2个数据时,为了防止后面的数据读取失败,可以标记当前的位置,调用mark方法将mark设为position的值,而其他变量不变,如下图:

5、当读数据到位置2之后,发现又需要切换到写模式,那么此时就需要重新向数据中写入数据,此时0-4的位置已经有了数据,就需要从5的位置开始写入,而已经读取的0-2两个位置已经被浪费了,所以为了避免空间的浪费,可以调用compact方法进行空间压缩,
压缩的逻辑为将剩余所有未读的数据复制到数组下标为0的位置,然后将position设置为下一个可以写的位置i,limit设置为capacity的值。如下图示:
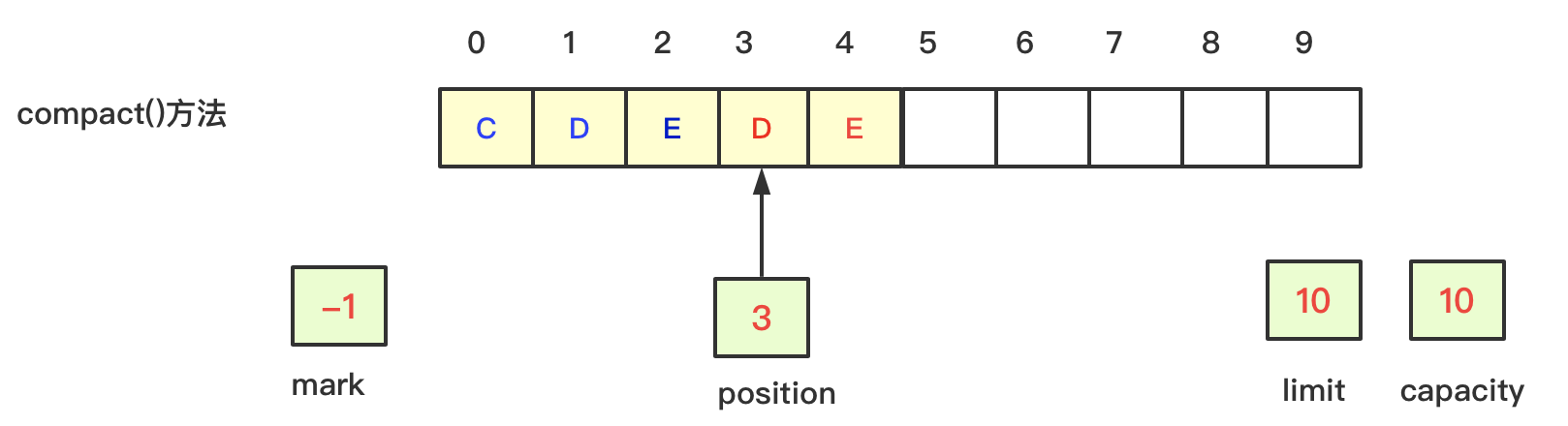
将数据“CDE”移动数组为0的位置,此时position值为3,虽然3-4位置已经有了数据"DE",但是马上就会被新写入的数据覆盖掉,所以不会有重复数据的问题。
Extra:
ByteBuffer创建的时候会在内存中申请一块区域,而分配的内存可以分为堆内内存和堆外内存(直接内存)
ByteBuffer的两个子类HeapByteBuffer和DirectByteBuffer分别就是使用的堆内内存和堆外内存
堆内内存是JVM堆内存中分配,所以堆内内存的分配和释放以及垃圾回收都是由JVM来控制的, 而堆外内存(直接内存)是直接在系统内存中分配和释放的,所以不会受到JVM的控制。
堆外内存的分配是通过本地类Unsafe的本地方法allocationMemory方法来分配的,释放内存是Unsafe的freeMemory方法来释放的。不过DirectByteBuffer本身的引用还是存在堆内内存中的,只不过持有堆外内存地址的引用。
由于DirectByteBuffer本身在堆中占用内存较少,但是持有直接内存的空间可能比较大,所以可能会出现不停创建比较大的DirectByteBuffer,就会出现堆内空间充足而堆外内存不足的情况。所以仅仅靠JVM的GC来回收DirectByteBuffer间接的回收
堆外内存肯定是不靠谱的,所以需要通过DirectByteBuuffer的Cleaner对象调用Clean方法来释放堆外内存。
相比于堆内内存,堆外内存的优缺点分明:
优点:
1、方便创建大对象,伸缩性更好,很少会遇到创建对象时出现内存不足的情况
2、进程之间共享内存,避免了将内存复制到虚拟机的过程
缺点:
1、垃圾回收不可控,容易出现内存泄露的问题
2、需要显式的调用System.gc()来释放堆外内存
DirectByteBuffer内部有一个Cleaner对象,Cleaner本身持有一个Cleaner对象的链表,当执行GC时会先通过Cleaner对象调用Unsafe的freeMemory方法进行堆外内存的释放。
当程序中需要用到将数据从堆外复制到堆内时,可以使用堆外内存,避免数据的复制过程,如常见的IO操作等。