转自:https://zhuanlan.zhihu.com/p/31391535
在实际工作中,复杂度上来后,各模块之间错综复杂,调用关系网千头万绪。即使有各种设计模式做指导,做出合理的设计也并不容易。程序员天天疲于应对层出不穷的变化,在不断紧逼的deadline压力下,面对巨大的重构工作量往往感到心有余而力不足。
系统复杂度的根源除了业务本身的复杂度,就是设计了不恰当的耦合关系。本文试图探讨依赖关系的主要类型,并总结应对依赖的编程范式。
耦合:依赖和变化
耦合是一个有歧义的词语(为什么“耦合”概念该要摒弃)。当我们说“A和B耦合”的时候,我们是想表达A和B之间有紧密的联系。具体是什么,不容易讲清楚。
在我看来,耦合至少包含了两个方面的含义:依赖和变化。
业务逻辑固有的复杂度决定了,模块之间必然存在着依赖。规范模块间的依赖关系,就是梳理业务复杂度的过程。最终的成果反映在代码中,代表了对业务复杂度的一种认识。这种认识随着业务需求的变化而演化,随着设计者的能力提升而深化。依赖不能被消除,但是可以被优化。探讨一些应对的范式有助于规避已知的陷阱。
变化则来源于两个方面:发展中的用户需求,完善中的系统模型。用户的需求是我们努力的方向。系统模型则代表了我们对需求的理解,是经验和智慧的结晶。一个完善的系统模型,表达能力要足够强,对业务的适应能力要足够强。变化,意味着工作量,意味着成本,应该尽量降低。如果我们把“系统变更”和“业务需求变更”写成函数:
我们希望自变量不变的情况下,“系统变更”这个函数值越小越好。特别是“业务需求变更”在当前系统设计假设条件下产生调整的时候,“系统变更”应该局限在很小的范围内。
依赖的种类
在UML类图中,依赖关系被标记为<<use>>。A依赖B意味着,A模块可以调用B模块暴露的API,但B模块绝不允许调用A模块的API(IBM Knowledge Center)。
在类图中,依赖关系是指更改一个类(供应者)可能会导致更改另一个类(客户)。供应者是独立的,这是因为更改使用者并不会影响供应者。
例如,Cart 类依赖于 Product 类,因为 Product 类被用作 Cart 类中的“添加”操作的参数。在类图中,依赖关系是从 Cart 类指向 Product 类。换句话说,Cart 类是使用者元素,而 Product 类是供应者元素。更改 Product 类可能会导致更改 Cart 类。
在类图中,C/C++ 应用程序中的依赖关系将两个类连接起来,以指示这两个类之间存在连接,并且该连接比关联关系更加具有临时性。依赖关系是指使用者类执行下列其中一项操作:
- 临时使用具有全局作用域的供应者类,
- 将供应者类临时用作它的某个操作的参数,
- 将供应者类临时用作它的某个操作的局部变量,
- 将消息发送至供应者类。
模块之间产生依赖的主要方式是数据引用和函数调用。检验模块依赖程度是否合理,则主要看“变更”的容易程度。软件模块之间的调用方式可以分为三种:同步调用、回调和异步调用(异步消息的传递-回调机制)。同步调用是一种单向依赖关系。回调是一种双向依赖关系。异步调用往往伴随着消息注册操作,所以本质上也是一种双向依赖。
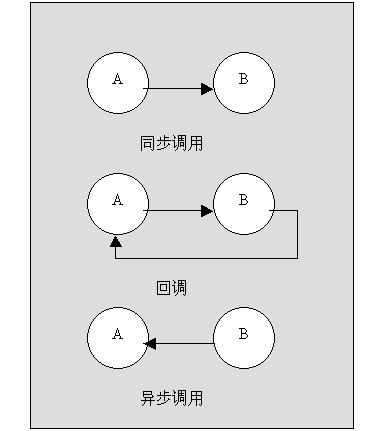 三种调用方式
三种调用方式
有一种观点将“依赖”直接总结为人脑中的依赖(为什么“耦合”概念该要摒弃),我非常认同。文中提到:
只要程序员编写模块A时,需要知道模块B的存在,需要知道模块B提供哪些功能,A对B依赖就存在。甚至就算通过所谓的依赖注入、命名查找之类的“解耦”手段,让模块A不需要import B或者include "B.h",人脑中的依赖仍旧一点都没有变化。唯一的作用是会骗过后文会提到的代码打分工具,让工具误以为两个模块间没有依赖。
代码的复杂度更主要的体现在阅读和理解,如果只是纠结于编译器所看到的依赖,实在是分错了主次,误入了歧途。
单向依赖与单一职责原则(SRP)
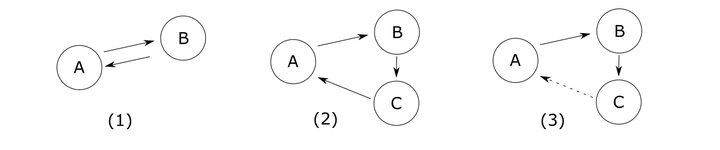
单向依赖是最简单的依赖。
 单向依赖
单向依赖
上述都是单向依赖的例子。其中,(1)是最理想的情况。当逻辑变复杂后,单个模块往往承担了过多的责任。即使模块之间可以保持简单的单向关系,模块内部各行为之间却形成高强度的耦合整体。根据单一职责原则(SRP),这样的模块也是难以维护的,我们需要对模块做拆分。
在有多个模块的情况下,(2)的依赖关系显然要好于(3),因为在(2)中模块的依赖关系要比(3)少。这样的解释过于抽象,我们用游戏中比较典型的一个应用场景来说明一下。
场景对象管理器GameObjectManager,管理着场景对象GameObjectInstance,而场景对象的构造需要资源AssetStore的支持。他们的调用关系,用(2)和(3)的模式分别实现一遍:
//(2) GameObjectManager从AssetStore取资源数据,然后调用GameObjectInstnce的初始化流程
class GameObjectManager{
public:
AssetForGameObject* GetAsset(DWORD dwID){m_Asset.GetAsset(dwID);}
GameObjectInstance* Create(DWORD dwAssetID){
AssetForGameObject* pAsset = GetAsset(dwAssetID);
return m_GameObjects[dwNewID] = new GameObjectInstance(pAsset);
}
void TickGameObject(){foreach(auto go = m_GameObjects) go.Tick();}
private:
AssetStore m_Asset;
map<DWORD, GameObjectInstance*> m_GameObjects;
};
//(3) GameObjectInstance自己调用AssetStore的方法取资源数据,做初始化
class GameObjectManager{
public:
GameObjectInstance* Create(AssetStore* pAssets, DWORD dwAssetID){
GameObjectInstance* pGo = new GameObjectInstance();
pGo->Init(pAssets, dwAssetID);
return m_GameObjects[dwNewID] = pGo;
}
private:
AssetStore m_Asset;
map<DWORD, GameObjectInstance*> m_GameObjects;
};
class GameObjectInstance{
public:
void Init(AssetStore* pAssets, DWORD dwAssetID){
m_Data = pAssets->GetAsset(dwAssetID);
}
};
GameObjectInstance只需要依赖于AssetForGameObject,但是在依赖关系(3)中,却要依赖于一个范围更大的概念AssetStore。
将双向依赖转换为单向依赖
双向依赖关系在网络游戏中也是比比皆是。我们来看一个双向依赖的典型例子:网络数据包的收发。如果把“上层业务逻辑”和“底层网络连接”看作两个模块。在发数据包的过程中,业务逻辑调用底层发送接口发送数据。业务逻辑依赖于底层网络连接。而在收数据包的时候,数据首先在网络连接模块接收,再分派到不同的业务逻辑。上层业务逻辑和底层网络连接形成了一种天然的双向依赖关系。
class Logic{
public:
void SendMessage(byte* pbyBuffer, size_t uLen){
m_pConnection->Send(pbyBuffer, uLen);
}
void HandleMessage(byte* pbyBuffer, size_t uLen){/*...*/}
private:
Connection* m_pConnection;
};
class Connection{
public:
void SetLogic(Logic* pLogic){m_pLogic = pLogic;}
void SendMessage(byte* pbyBuffer, size_t uLen){/*...*/}
void RecvMessage(byte* pbyBuffer, size_t uLen){
m_pLogic->HandleMessage(pbyBuffer, uLen);
}
private:
Logic* m_pLogic;
};
用最自然的方式,我们写出了上面的代码。这其实是用“依赖注入”实现的回调。容易发现,当Logic增减成员变量或成员函数,Connection就需要重新编译,甚至重新调整代码。这样的耦合度是无法接受的。
我们可以尝试用"Don't call us, we will call you"把双向依赖转换为单向依赖。简单来说,当网络连接收到数据包后,可以先放到一个存储区。等调度到业务逻辑的时候,业务逻辑主动去取数据并处理。在存储区存储一个数据,就相当于存储一个对业务逻辑的调用请求。这样就演变为了单向依赖关系(3),模块C就相当于存储区。需要说明的是,存储区并不一定必须要独立出来一个模块,完全可以维护在模块B中。此种情形,A可以直接向B要数据。
并不是所有的双向依赖关系都可以很容易的转换为单向依赖。上述例子中,如果业务逻辑来不及处理数据包,网络连接层就要维护一个数据列表。这增加了存储开销。而且有时候把数据延迟处理是不合适的。代码也因此变得晦涩难懂,难以维护。如果导致这种结果,那就与我们转换依赖关系的初衷背道而驰了。
弱化双向依赖:回调与中间层
一般情况下,为了弱化双向依赖的影响,我们可以增加一个中间层。虽然调用链路是从“网络连接”又回到了“业务逻辑”,但是由于中间层的存在,变化被隔离,原先很强的依赖关系变弱了。以下介绍四种典型的中间层。
 通过添加稳定的中间层隔离变化
通过添加稳定的中间层隔离变化
需要说明的是,上述所说的中间层,偏向于概念,在代码实现中并不一定要独立成一个单独的模块。但为了方便,还是借用模块(如上图中的模块C)来表述。
1)接口与继承
我们很自然想到,依赖注入可以使用接口。当Connection依赖的是Logic的接口(假定为ILogic),虽然Logic变更,只要ILogic不变,就不会影响Connection。但是在实践中根本不是这么回事。
我们经常听说,只要把接口设计得“正交”“紧凑”,就能保证接口的稳定。但是,在实践中,混乱的继承关系随处可见。大多数程序员都停留在利用继承思维构造业务逻辑关系,并尽快实现功能。极少有能力有时间检视继承关系是否恰当。正确使用继承对程序员的要求太高了。
当重新审视继承的时候我们发现,继承的父类和子类之间实际形成了一种双向依赖。继承和多态不仅规定了函数的名称、参数、返回类型,还规定了类的继承关系,是一种强耦合(https://cloud.github.com/downloads/chenshuo/documents/CppPractice.pdf, p45)。接口约定了外部调用的规范,继承类必须按照这些规范去实现。只要规范不变,继承类的实现可以调整而不将影响传递出去。糟糕的是,不管是规范还是实现,都基本上不可能一开始就确定好。当变化发生的时候,接口类和继承类都需要做大量的修改,而这些修改也很容易影响到所有使用接口的那些模块。
稳定的继承关系可以提供良好的扩展性,也可以避免把相同的逻辑写得到处都是(DRY原则)。但是滥用继承也会是灾难性的。在"Is-A"和"Has-A"的取舍中,要谨慎行事。
2)Delegation
一个对调用者和被调用者约束较小的方式是代理(Delegation)。所谓代理,就是将依赖转移到较稳定的代理类上。通过一个仿函数,调用不同类中有相同签名的方法。一个典型的代理类的例子如下所示(The Impossibly Fast C++ Delegates)。其最初版本需要对每种参数做不同处理。后来发展出来一种更一般的代理方式(C++ Delegates On Steroids),可以接受任意类型和任意数量的参数。
class delegate
{
public:
delegate() : object_ptr(0), stub_ptr(0){}
template <class T, void (T::*TMethod)(int)>
static delegate from_method(T* object_ptr){
delegate d;
d.object_ptr = object_ptr;
d.stub_ptr = &method_stub<T, TMethod>; // #1
return d;
}
void operator()(int a1) const{
return (*stub_ptr)(object_ptr, a1);
}
private:
typedef void (*stub_type)(void* object_ptr, int);
void* object_ptr;
stub_type stub_ptr;
template <class T, void (T::*TMethod)(int)>
static void method_stub(void* object_ptr, int a1){
T* p = static_cast<T*>(object_ptr);
return (p->*TMethod)(a1); // #2
}
};
3) Bind/Function
Bind/Function机制不要求被绑定的类有任何继承规范。其更像是C中的函数指针,比代理类要更简单。除了和代理类一样需要函数签名一致,不需要程序员额外维护一个类。
现在C++11提供了很好用的bind/function(Bind illustrated,C++11: std::function and std::bind)。我们可以将上述的数据包处理回调重写如下:
class Logic{
public:
void Init(){
m_pConnection->SetCallbackFunc(std::bind(HandleMessage), this);
}
void SendMessage(byte* pbyBuffer, size_t uLen){
m_pConnection->Send(pbyBuffer, uLen);
}
void HandleMessage(byte* pbyBuffer, size_t uLen){/*...*/}
private:
Connection* m_pConnection;
};
class Connection{
public:
void SetCallbackFunc(Logic* pLogic){m_pLogic = pLogic;}
void SendMessage(byte* pbyBuffer, size_t uLen){/*...*/}
void RecvMessage(byte* pbyBuffer, size_t uLen){
m_callbackfunc(pbyBuffer, uLen);
}
private:
func* m_callbackfunc;
};
4) Lambda与闭包
严格来说,bind/function的实现也属于闭包。这里把Lambda/Closure单独列出来是想强调Lambda表达式可以通过匿名函数把相同的事做的更简洁。比起bind一个成员函数,直接bind一个在局部空间定义的lambda表达式给程序员带来的思维负担更小。
毕竟,修改lambda表达式时,可以清楚知道影响的范围。而修改被bind的成员函数时,还要考虑该成员函数是不是在其他地方被用到。