系列四主要介绍硬件的东西,也不是说不重要,如果要深入研究程序运行机制也是必须了解的。暂时时间比较紧,还没来得及了解,先介绍优化程序性能,主要通过一个程序和一张思维导图来介绍。
主要程序如下,给出了最原始的实现,然后通过各种优化点进行优化,给出了各种优化代码。
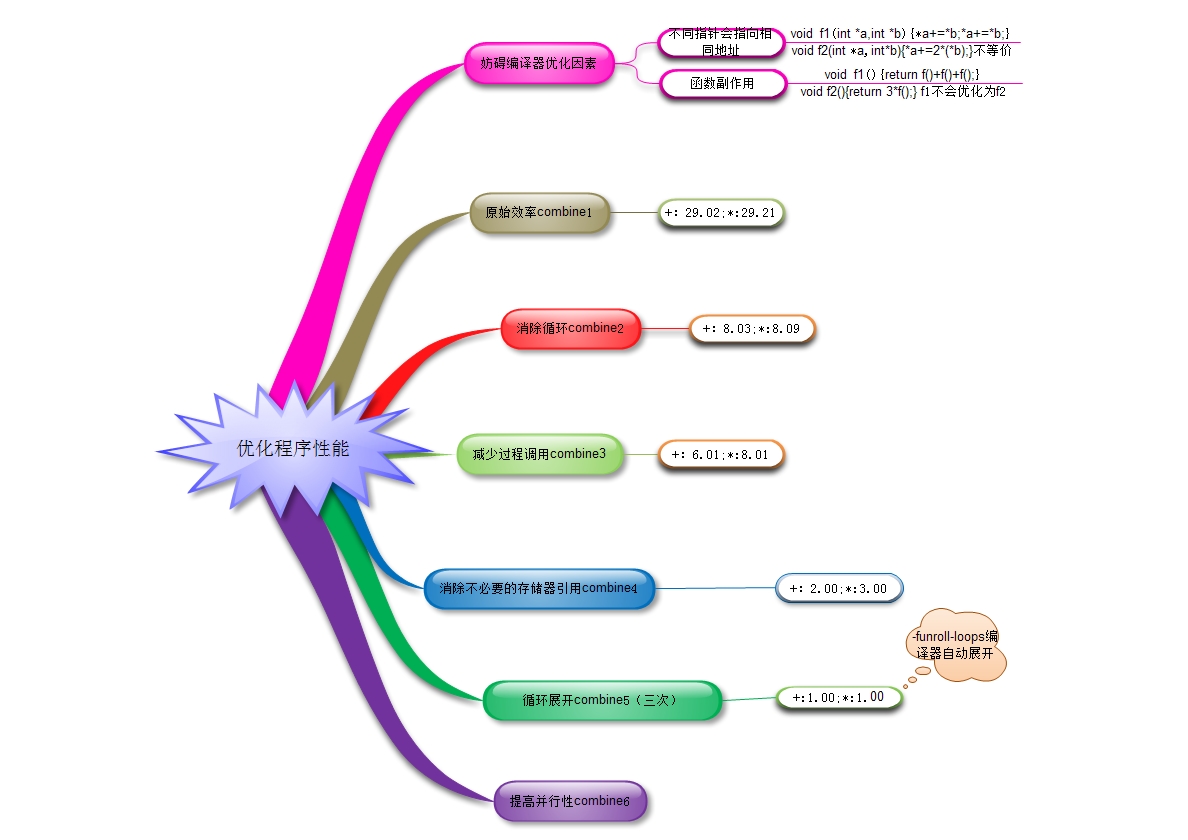
1 typedef struct{ 2 long int len; 3 data_t *data; 4 }vec_rec,*vec_ptr; 5 6 typedef int data_t;//通过定义data_t,操作不同的基本数据类型 7 8 //对向量元素求和 9 #define IDET 0 10 #define OP + 11 12 //对向量元素求积 13 #define IDET 1 14 #define OP* 15 16 vec_ptr new_vec(long int len) 17 { 18 vec_ptr result=(vec_ptr)malloc(sizeof(vec_rec)); 19 if(!result) 20 result NULL; 21 result->len = len; 22 if(len>0){ 23 data_t *data=(data_t*)malloc(len,sizeof(data_t)); 24 if(!data){ 25 free((void *)result); 26 return NULL; 27 } 28 result->data=data; 29 } 30 else 31 result->data=NULL; 32 return result; 33 } 34 35 int get_vec_element(vec_ptr v, long int index, data_t *dest) 36 { 37 if(index<0||index>=v->len) 38 return 0; 39 *dest=v->data[index]; 40 return 1; 41 } 42 43 long int vec_length(vec_ptr v) 44 { 45 return v->len; 46 } 47 48 //合并的原始实现 49 void combine1(vec_ptr v, data_t *dest) 50 { 51 long int i; 52 53 *dest=IDET; 54 for(i=0;i<vec_length(v);i++){ 55 data_t val; 56 get_vec_element(v,i,&val); 57 *dest = *dest OP val; 58 } 59 } 60 61 //消除循环的低效率 62 void combine2(vec_ptr v, data_t *dest) 63 { 64 long int i; 65 long int length=vec_length(v); 66 67 *dest=IDET; 68 for(i=0;i<length;i++){ 69 data_t val; 70 get_vec_element(v,i,&val); 71 *dest = *dest OP val; 72 } 73 } 74 75 //减少过程调用,只提高了整数求和 76 data_t *get_vec_start(vec_ptr v) 77 { 78 return v->data; 79 } 80 void combine3(vec_ptr v, data_t *dest) 81 { 82 long int i; 83 long int length=vec_length(v); 84 data_t *data=get_vec_start(v); 85 86 *dest=IDET; 87 for(i=0;i<length;i++){ 88 *dest = *dest OP data[i]; 89 } 90 } 91 92 //消除不必要的存储器应用 93 //combine3每次从%rbp(存放dest的地址)中读出数据,并写入 94 //编译器不会把combine3优化为combine4,以为别名使用 95 //v=[2,3,5],combine3(v,get_vec_start(v)+2);combine4(v,get_vec_start(v)+2); 96 //得到的结构为36和30 97 void combine4(vec_ptr v, data_t *dest) 98 { 99 long int i; 100 long int length=vec_length(v); 101 data_t *data=get_vec_start(v); 102 103 data_t acc=IDET; 104 for(i=0;i<length;i++){ 105 acc = acc OP data[i]; 106 } 107 *dest = acc; 108 } 109 110 //循环展开,减小循环开销 111 void combine5(vec_ptr v, data_t *dest) 112 { 113 long int i; 114 long int length=vec_length(v); 115 long int limit=length-1; 116 data_t *data=get_vec_start(v); 117 118 data_t acc=IDET; 119 for(i=0;i<limit;i+=2){ 120 acc = acc OP data[i] OP data[i+1]; 121 } 122 for(;i<length;i++){ 123 acc = acc OP data[i]; 124 } 125 *dest = acc; 126 } 127 128 //提高并行性 129 void combine6(vec_ptr v, data_t *dest) 130 { 131 long int i; 132 long int length=vec_length(v); 133 long int limit=length-1; 134 data_t *data=get_vec_start(v); 135 136 data_t acc0=IDET; 137 data_t acc1=IDET; 138 for(i=0;i<limit;i+=2){ 139 acc0 = acc0 OP data[i]; 140 acc1=acc1 OP data[i+1]; 141 } 142 for(;i<length;i++){ 143 acc0 = acc0 OP data[i]; 144 } 145 *dest = acc0 OP acc1; 146 } 147 148 //重新结合 149 void combine5(vec_ptr v, data_t *dest) 150 { 151 long int i; 152 long int length=vec_length(v); 153 long int limit=length-1; 154 data_t *data=get_vec_start(v); 155 156 data_t acc=IDET; 157 for(i=0;i<limit;i+=2){ 158 acc = acc OP (data[i] OP data[i+1]); 159 } 160 for(;i<length;i++){ 161 acc = acc OP data[i]; 162 } 163 *dest = acc; 164 }
本节的主要思维导图如下,后面的数据是根据intel core 7测的性能,每次优化过程标识了函数名,对应于上面的程序。
性能查看工具可以使用perf,具体使用可以参考:
1 IBM的相关文档https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
2 淘宝的相关文档http://kernel.taobao.org/index.php/Documents/Kernel_Perf